一文概览机器学习面临的所有攻击类型
编者按:本文作者Elie Bursztein是谷歌不当行为和反欺诈部门的领导者,他在自己的博客上总结了目前机器学习可能面临的一些攻击行为,同时给出了详细的应对方案,是一份很有价值的技术贴,希望对读者有帮助。
这篇博文讲述了攻击AI系统的一些技术,以及应该如何防御它们。总的来说,针对分类器的攻击可以分为以下三种:
对抗输入(Adversarial inputs):这是经过精心设计过的输入,其目的就是为了迷惑分类器以逃过检测。对抗输入包括逃避杀毒软件的恶意文件以及躲避垃圾过滤的邮件。
数据攻击(Data poisoning):这是指在分类器中输入训练对抗数据。最常见的攻击类型是模型扭曲(model skewing),其中攻击者试图污染训练数据,让分类器无法识别哪些是好的数据。我们观察到的另一种攻击是“将反馈作为武器(feedback weaponization)”,它会攻击反馈机制,从而让系统将好的内容错误地识别成不良内容。
模型窃取技术(Model stealing):这类技术通过黑箱探测器复制模型或获取训练数据(所以称为“偷”)。这种技术可以用在窃取预测市场库存的模型和垃圾过滤模型上,以进行更好的优化。
这篇文章将对上述三种攻击方法逐一进行详解,同时会提供具体的案例并讨论具体的应对方法。本文面向所有对用AI进行反攻击感兴趣的读者,关注的重点是进行清晰的总结,而不详细说明其中的技术细节。希望这篇文章能对你有所启发。
对抗输入
对抗样本经常会向分类器输入新的元素以“瞒天过海”,这样的输入被称作“对抗输入”,因为它们很明显是为了逃避分类器的。

下面是一个具体的有关对抗输入的例子:许多年前,一位聪明的垃圾邮件制造者发现,如果在一封邮件里出现了很多次同样的复合附件,Gmail只会在屏幕上方显示最后一个附件。他利用这一漏洞,在附件中加入了许多可靠域,以逃过检测。这种攻击是“关键词堆砌”的一种变体。
总的来说,分类器面临两种对抗输入:首先是变异输入(mutated inputs),它是经过改造逃避分类器的一种攻击方式。另一种是零日输入(zero-day inputs),指的是输入全新的数据。下面就让我们详细讨论一下。
变异输入
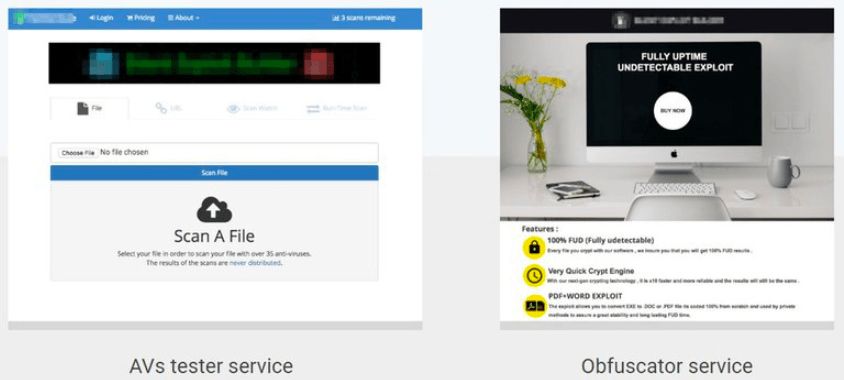
过去几年,我们看到很多“地下服务”层出不穷,它们大多是帮助网络犯罪行为进行“隐藏”的技术,简称FUD(fully undetectable)。这些服务包括能反抗防病毒软件的测试服务、能将恶意文件伪装的自动packers,让其躲过检测(并且还是有证书的!)。上方图片就展示了这两种服务。
这种灰色服务的崛起说明了一个事实:
攻击者不断优化它们的攻击技术,从而保证能将分类器的探测率最小化。
所以,重要的是创建难以让攻击者优化的监测系统。具体策略有三:
1.限制信息泄露

这里的目标是,当攻击者调查你的系统时,保证让他们知道的越少越好。重要的是尽量让反馈最小化,同时尽可能地延迟,例如避免返回详细的错误代码或者置信度值。
2.限制调查
这一方法的目的是减少攻击者针对你系统测试的次数,通过限制测试,你能有效减少他们创造出有害信息的机会。
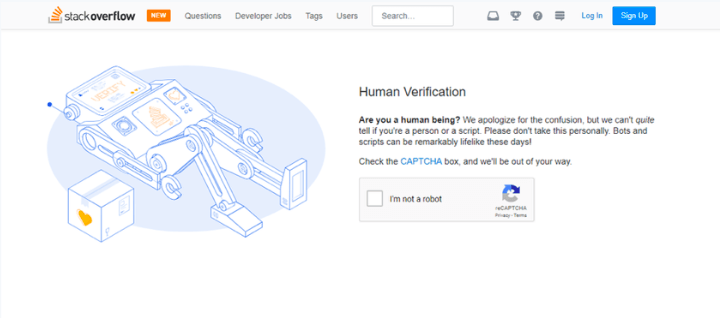
这种方法一般是在IP或账号等资源上实施速率限制,一个典型案例就是如果用户操作太频繁会要求输入验证码。
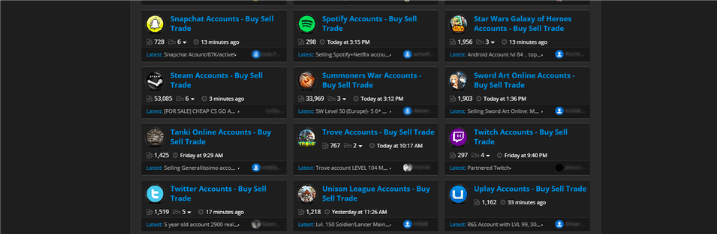
这种速率限制的消极影响就是,它会刺激哪些攻击者创建虚假账户,然后利用遭到侵入的用户电脑来丰富他们的IP池。业界广泛使用速率限制,也催生了很多黑色论坛,上面有许多账户和IP地址被贩卖,如上图所示。
3.集成学习
最后,重要的是结合多种检测机制,让攻击者无处可逃。利用集成学习将不同的检测方法结合,例如基于信誉的机制、AI分类器、检测规则以及异常检测等,都可以提高系统的稳定性,因为攻击者要设计一款能逃脱所有检测的方法还是有些难度的。

如图,为了保证Gmail分类器对垃圾邮件的鲁棒性,我们结合了多种分类器和辅助系统,包括信誉系统、大型线性分类器、深度学习分类自和其他一些保密技术。
针对深度神经网络的对抗攻击案例

目前一个很活跃的领域是研究如何制造对抗样本骗过深度神经网络,人们目前可以在一幅图上进行十分细小的改动,几乎看不出来差别,就可以骗过神经网络。论智此前也有关于这项技术的报道:
最近有研究认为,CNN在面对对抗样本输入的时候非常脆弱,因为它们只学习数据集表面的规律,而不会生成和学习高级表示,从而不易受噪声的干扰。
在视频中可以看到,这种攻击影响了所有DNN,包括基于强化学习的深度神经网络。为了了解更多此类攻击的内容,你可以阅读OpenAI的博客:https://blog.openai.com/adversarial-example-research/,或者参考:https://github.com/tensorflow/cleverhans。
从防御者的角度来说,这种攻击目前为止还比较令人头疼,因为没有一种有效方法能抵御这类攻击。你可以阅读Ian Goodfellow和Nicolas Papernot的博客来进一步了解:http://www.cleverhans.io/security/privacy/ml/2017/02/15/why-attacking-machine-learning-is-easier-than-defending-it.html
零日输入
对抗输入的另一个种类就是给分类器全新的攻击。这种技术出现的不是很频繁,但是还是有必要提一下的,因为一旦出现,攻击力还是很强的。新型攻击的出现可能有很多原因,在我们的经验里,下面两种情况最易引起新的攻击:
新产品或功能的发布:新功能上线很容易吸引攻击者,这也是为什么在发布新产品时提供零日防御非常重要。
利益诱惑:尽管很少提到,但很多新的攻击都是看到巨大利益的结果。去年12月加密货币疯狂上涨,有些人为了从其中获利,开始攻击云服务器(包括谷歌云)。

随着比特币价格突破10000美元,我们发现了许多新型攻击,试图从谷歌云服务器中窃取资源进行挖矿。
总而言之,黑天鹅理论也适用于基于AI的防御:
总有一天,一个从未预料到的攻击将会摆脱分类器控制,并造成巨大的影响。
然而,这并不是因为你无法预料出现的是何种攻击,还活着攻击什么时候来。你可以对此进行计划,做好预防工作。下面是几个应对黑天鹅事件的探索方向:
建立事故防御机制:首先要做的就是建立并测试恢复系统,一旦遭到攻击,还能够进行应对。
利用迁移学习保护新产品:一个关键难题就是你不能用历史数据继续训练分类器,而解决方法之一就是用迁移学习,可以重新使用现有数据,将其迁移运用到另一个域中。
使用异常检测:异常检测算法可以当做防御的第一道防线,因为一种新攻击会产生此前没有遇到过的异常,但这与你的系统相关。
还拿比特币为例,去年比特币价格疯狂上涨,很多人想免费“挖矿”,于是他们利用了许多攻击途径,包括入侵我们的免费方案、用偷来的信用卡作案、入侵合法用户的电脑或利用网络钓鱼的方法劫持云用户的账号。
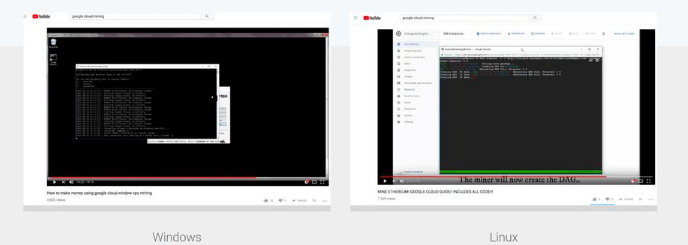
很快,这类攻击赢得了市场,YouTube上甚至还出了如何在谷歌云上挖矿的教程。
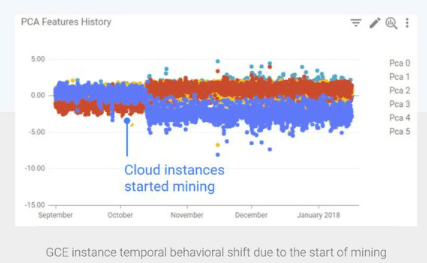
幸运的是,我们建立了合适的异常检测系统,上图显示,当攻击者开始挖矿,他们的行为变化的非常明显,因为相关资源用量和传统合法资源使用是不一样的。我们用这种变化检测禁止了新型攻击,保证了云平台的稳定。
数据攻击
分类器面临的第二种攻击表现为,对抗样本想扰乱你的数据,从而让系统失灵。
模型更改(Model skewing)
第一种数据干扰被称为模型更改,攻击者会试着污染训练数据,改变模型的判断标准。
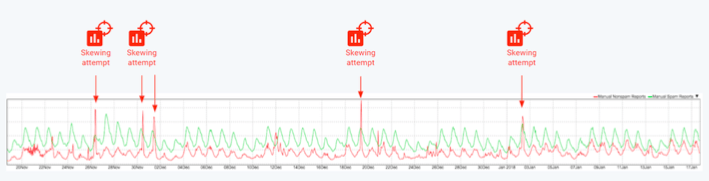
在实际中,我们经常能看到很多先进的垃圾邮件生产者试着逃过Gmail的过滤系统,将垃圾邮件伪装成正常邮件。上图表示在2017年11月末到2018年初,我们一共受到四次攻击,试图改变分类器。为减少此类攻击,应对策略有:
合理数据采样。你需要保证一小部分实体,包括IP和用户,不依赖大量训练数据。尤其小心不要在用户的误报和漏报上添加过多权重。这可以通过限制每个人可贡献的样本来实现,或者根据已经报告的样本衰减权重。
对比新训练的分类器和老分类器。例如,你可以用灰度发布(dark launch)对比两种不同的输出。
建立一个黄金数据集。即数据集中含有一组可能的攻击以及正常内容,对系统非常有代表性。这一过程可以保证你在受到攻击时还能进行检测,并且在对用户造成危害之前就进行重要的回归分析。
反馈武器化
数据干扰的第二种类型就是讲用户的反馈系统作为武器,攻击合法用户和内容。如果攻击者意识到你正在使用用户反馈,他们会试着将此作为攻击。
一个非常著名的例子就是2017年,以特朗普的支持者们为首的一群人在各大应用市场给CNN(美国有线电视新闻网)的APP打了一颗星。由此我们得知,任何反馈机制都有可能成为攻击武器。
应对策略:
在反馈和惩罚之间不要建立直接联系。而是要对反馈进行评估,同时在做决策之前与其他信号相结合。
搞破坏的不一定是真正的坏人。我们见过太多例子了,很多攻击者伪装成合法用户以掩盖他们的恶劣行为,并且引导我们去惩罚无辜的人。
模型窃取攻击
这类攻击非常关键,因为模型代表着知识产权,里面有很多公司非常重要的数据,比如金融贸易、医疗数据等。保证模型安全至关重要。
然而,模型窃取攻击有以下两种:
模型重建:在这种情况下,攻击者会利用公开API不断调整自己的模型,把它当做一个数据库,然后重建模型。最近有一篇论文认为,这种攻击对大多数AI算法十分有效,包括SVM、随机森林和深度神经网络。:https://www.usenix.org/system/files/conference/usenixsecurity16/sec16papertramer.pdf
会员信息泄露:攻击者会创建一个影子模型,让他知道训练模型都需要哪些特定元素。这类攻击不会复刻模型,只是潜在地泄露了敏感信息。

目前针对此类攻击最有效的方法是PATE,它是由Ian Goodfellow等人提出的一种私密框架(上图),论文地址:https://arxiv.org/abs/1802.08908。
如图,PATE的核心思想就是将数据分离,并且训练多个模型共同做决策。之后在决策中加入噪音,就像其他差分隐私系统一样。
了解更多差分隐私的知识,可以阅读Matthew Green(苹果公司任职)的介绍文章:https://blog.cryptographyengineering.com/2016/06/15/what-is-differential-privacy/
论智君也曾在另一篇文章中报道过苹果公司的差分隐私技术:苹果用机器学习和差分隐私大规模分析用户数据,并保证不会泄露信息
了解更多PATE和模型窃取攻击,可以阅读Ian Goodfellow的博文:http://www.cleverhans.io/privacy/2018/04/29/privacy-and-machine-learning.html
结语
尽管机器学习还面临着很多现实挑战,但AI是建立防御机制的关键,随着AI框架日趋成熟,目前是建立AI防御的最好时机,如果你也感兴趣快动手试试吧!
原文地址:https://elie.net/blog/ai/attacks-against-machine-learning-an-overview



