10亿+/秒!看阿里如何搞定实时数仓高吞吐实时写入与更新

数据实时入仓所面临的挑战:高性能、可更新、大规模
-
Append only:传统日志类数据(日志、埋点等)中,记录(Record)和记录之间没有关联性,因此新来的记录只需要append到系统中就好了。这是传统大数据系统最擅长的一种类型。 -
Insert or Replace:根据设置的主键(Primary Key, PK)进行检查,如果系统中不存在此PK,就把这行记录append进系统; 如果存在,就把系统中旧的记录用新的记录整行覆盖。典型的使用场景有:
-
上游数据库通过Binlog实时同步,这种写入就是Insert or Replace。 -
Flink的结果实时写出。Flink持续刷新结果,需要Insert or Replace的写目标表。 -
Lambda架构下的离线回刷。Lambda架构下离线链路T+1回刷实时结果表中昨天的记录。 -
-
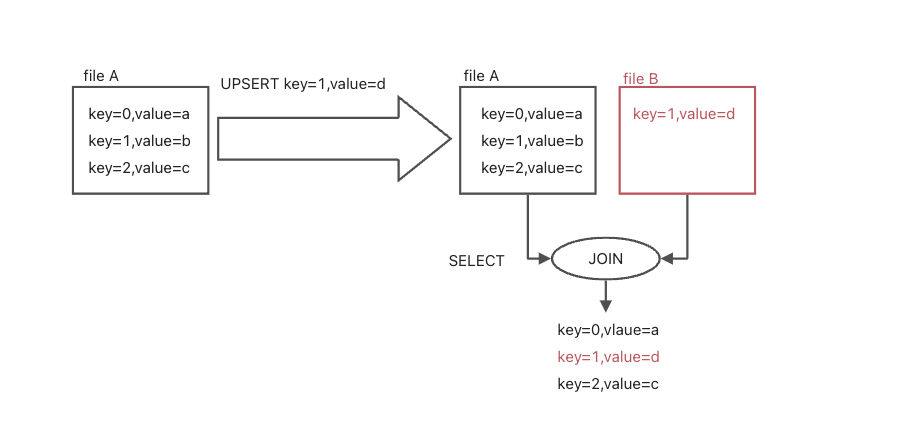
Insert or Update:通常使用在多个应用更新同一行数据的不同字段,实现多个数据源的JOIN。如果这行记录存在,各个应用直接根据PK去update各自的字段;但如果这行记录不存在,那么第一个要写入这行记录的应用就需要INSERT这行记录。典型的使用场景:
-
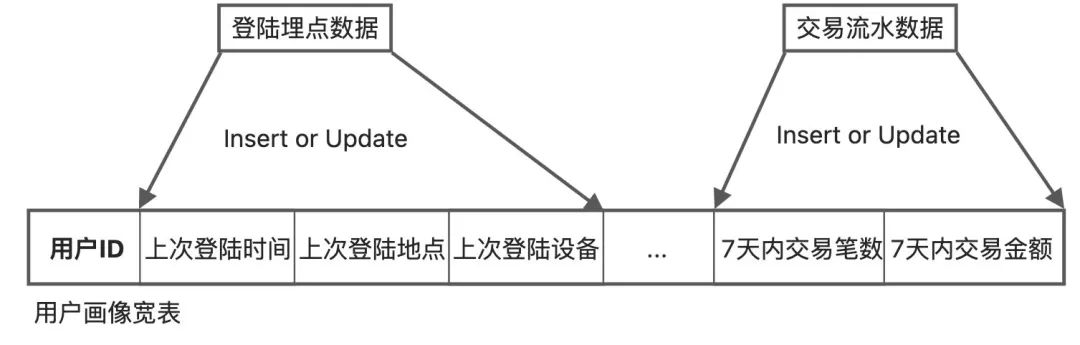
画像类应用。这类应用在实时风控、实时广告投放等非常常见。上游多个Flink Job实时计算画像的不同维度,并实时写入到同一行记录的不同字段中。 -
实时离线数据整合。在需要同时用到实时和离线计算的场合,把同一个PK的实时和离线结果放在同一行记录的不同字段中,就可以方便的同时取到实时和离线的计算结果。
Hologres的实时写入模型与性能
-
支持主键,可以高效利用主键更新、删除数据。 -
支持Upsert:完整支持高性能的Append Only、Insert or Replace、Insert or Update 3种能力,可根据业务场景选择写入模式。 -
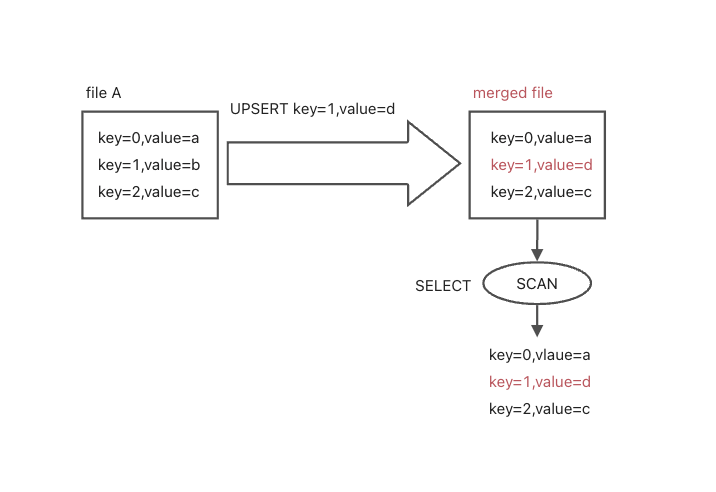
对于列存表,自动使用Merge on Write方案。对于行存表,自动使用Merge on Read方案,原因如下:
-
对于列存表,主要是做复杂的OLAP分析,因此查询性能最重要。 -
对于行存表来说,查询主要是点查,此时Merge on Read单行的开销足够小,因此重点考虑写入性能。在阿里很多点查场景,写入要求非常高的RPS。
-
支持Exactly Once。通过单行SQL事务和主键PK自动去重来实现。无论是批量数据写入(一次更新几亿条记录),还是逐条记录实时写入,Hologres都是保证单条SQL的原子性(ACID)。而对于上游Flink等failover造成的SQL重发,Hologres通过目标表的主键,实现自动覆盖或者忽略(对于Upsert是自动覆盖;对于append,是自动忽略Insert or Ignore)。因此,目标表是幂等的。 -
写入即可见。Hologres没有类似ElasticSearch的build过程,也没有类似ClickHouse或者Greenplum的攒批过程,数据通过SQL写入时,SQL返回即表示写入完成,数据即可查询。因此通过Flink等实时写入(背后也是SQL写入)能满足写入即可见,无延迟。
-
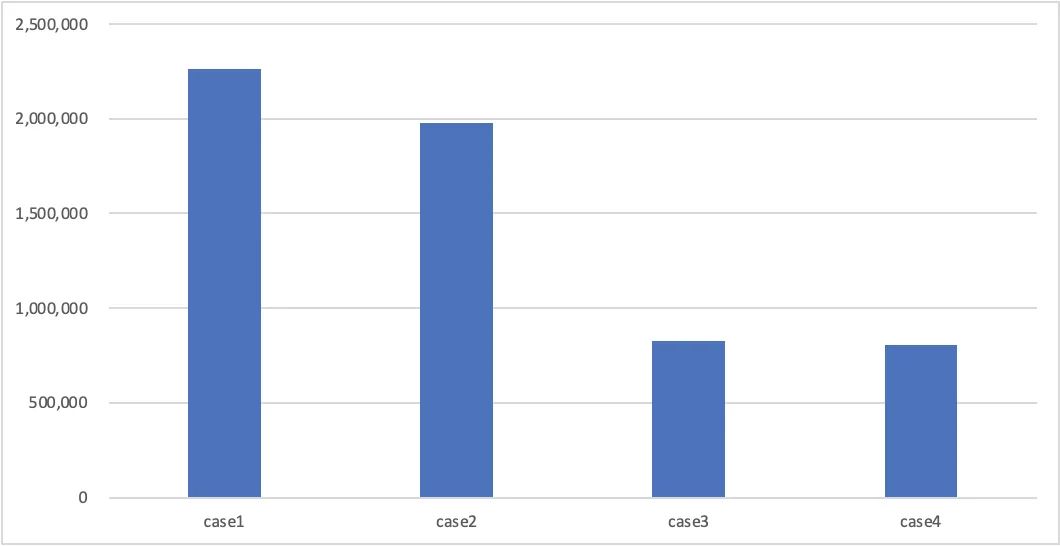
case1:写入无主键表; -
case2:写入有主键表(Insert or Replace),并且每次INSERT的主键和表已有数据都不冲突; -
case3:写入有主键表(Insert or Replace),并且每次INSERT的主键和表已有数据均冲突,表中数据量为2亿。 -
case4:写入有主键表(Insert or Replace),并且每次INSERT的主键和表已有数据均冲突,表中数据量为20亿。
-
对比case1和case2,可以看到Hologres判断主键是否存在性能损失较小; -
对比case2,case3,case4,可以看到主键冲突时,hologres定位数据所在文件并标记DELETE基本不随数据规模上涨而上涨,可以应对海量数据下的高速Upsert。
与常见产品对比
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Merge on Write模式下 实时写入与更新的常见原理
CREATE TABLE users (id int not null,name text not null,age int,primary key(id));INSERT INTO users VALUES (?,?,?)ON CONFLICT(id) DO UPDATESET name = EXCLUDED.name, sex = EXCLUDED.sex, age = EXCLUDED.age;
-
定位旧数据所在文件。 -
处理旧数据 -
写入新数据
1、定位旧数据所在文件
-
HBase状态和Hudi表状态的一致性,因为HBase和Hudi是独立的两套系统,一方如果发生故障可能导致索引失效。 -
性能上限是HBase的PK点查性能。要取得更好的写入性能是困难的。
2、处理旧数据+写入新数据
-
在数据文件对应的delta文件中标记该行旧数据为删除状态。 -
在delta中追加新数据的信息。
Hologres 基于Memtable的写入原理
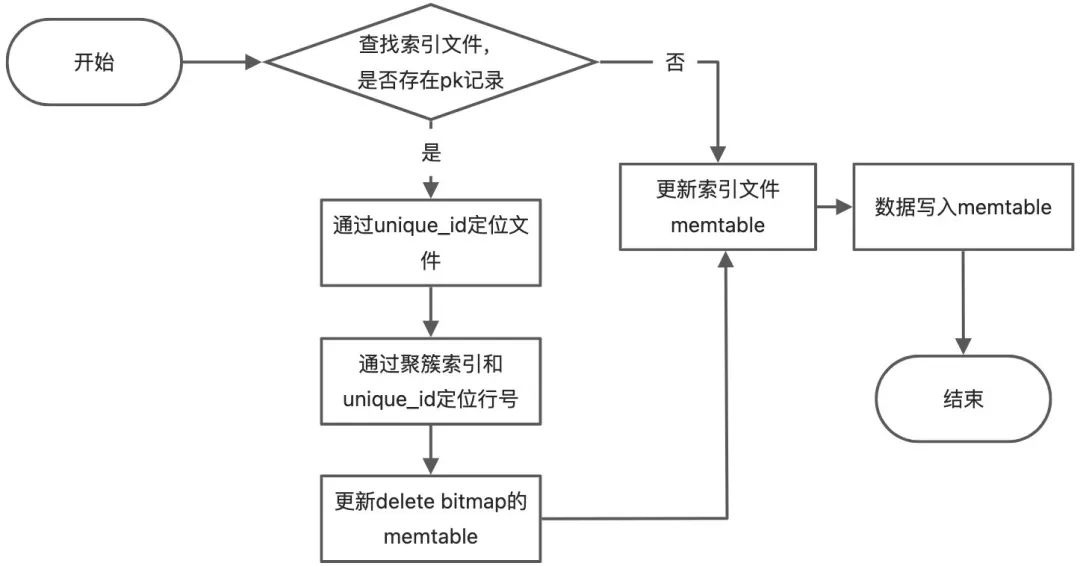
1、文件模型
-
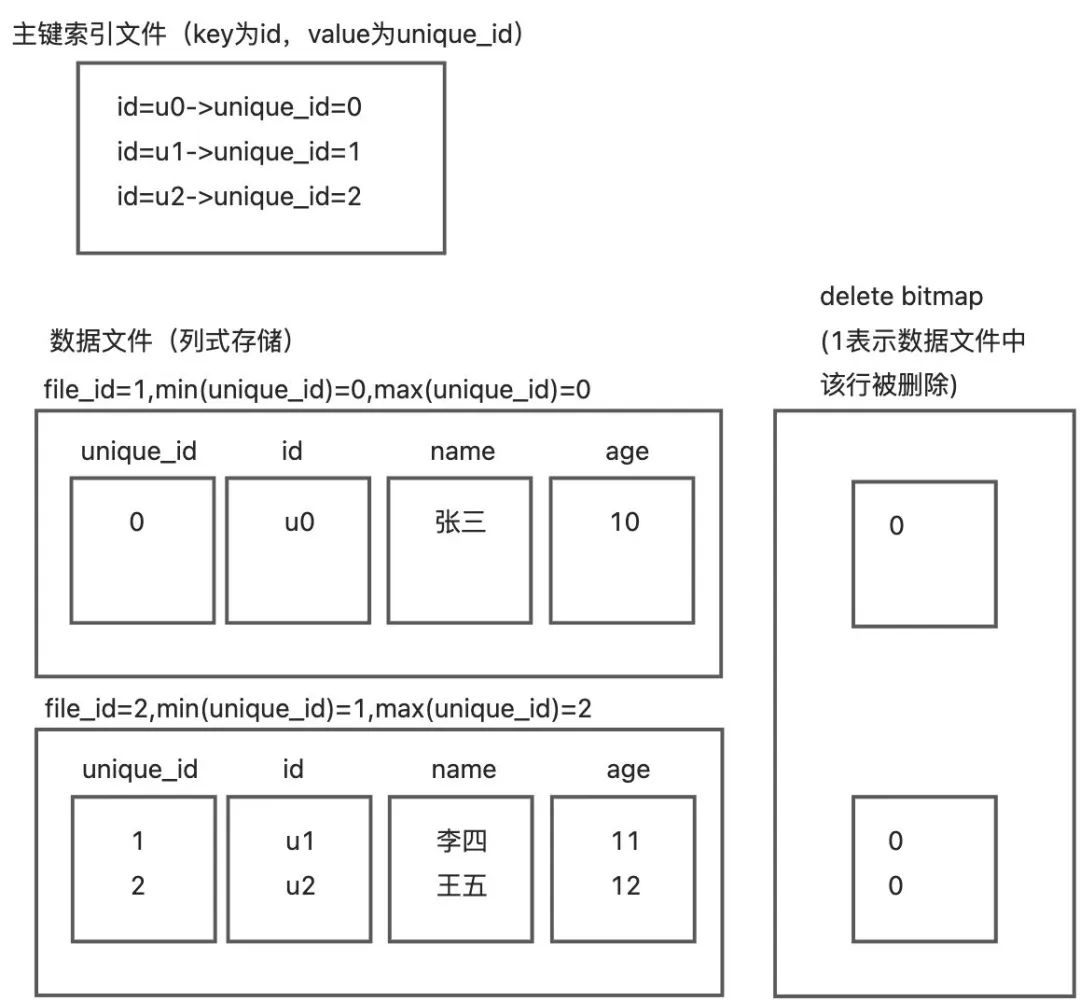
第一种是主键索引文件,采用行存结构存储,提供高速的key-value服务,索引文件的key为表的主键,value为unique_id和聚簇索引。unique_id每次Upsert自动生成,单调递增。主键索引文件实现高效的主键冲突判定并辅助数据文件定位; -
第二种是数据文件,采用列存结构存储,文件内按照聚簇索引+unique_id生成稀疏索引,并对unique_id生成范围过滤器; -
第三种是delete bitmap文件,每个file id对应一个bitmap,bitmap中第N位为1表示file id中的第N行标记为删除。delete bitmap在列存模型下,相当于是表的一列数据。Update时只刷新bitmap信息既保留了Merge on Write对查询性能几乎零破坏的优点,又极大降低了IO的开销。
2、Upsert流程
-
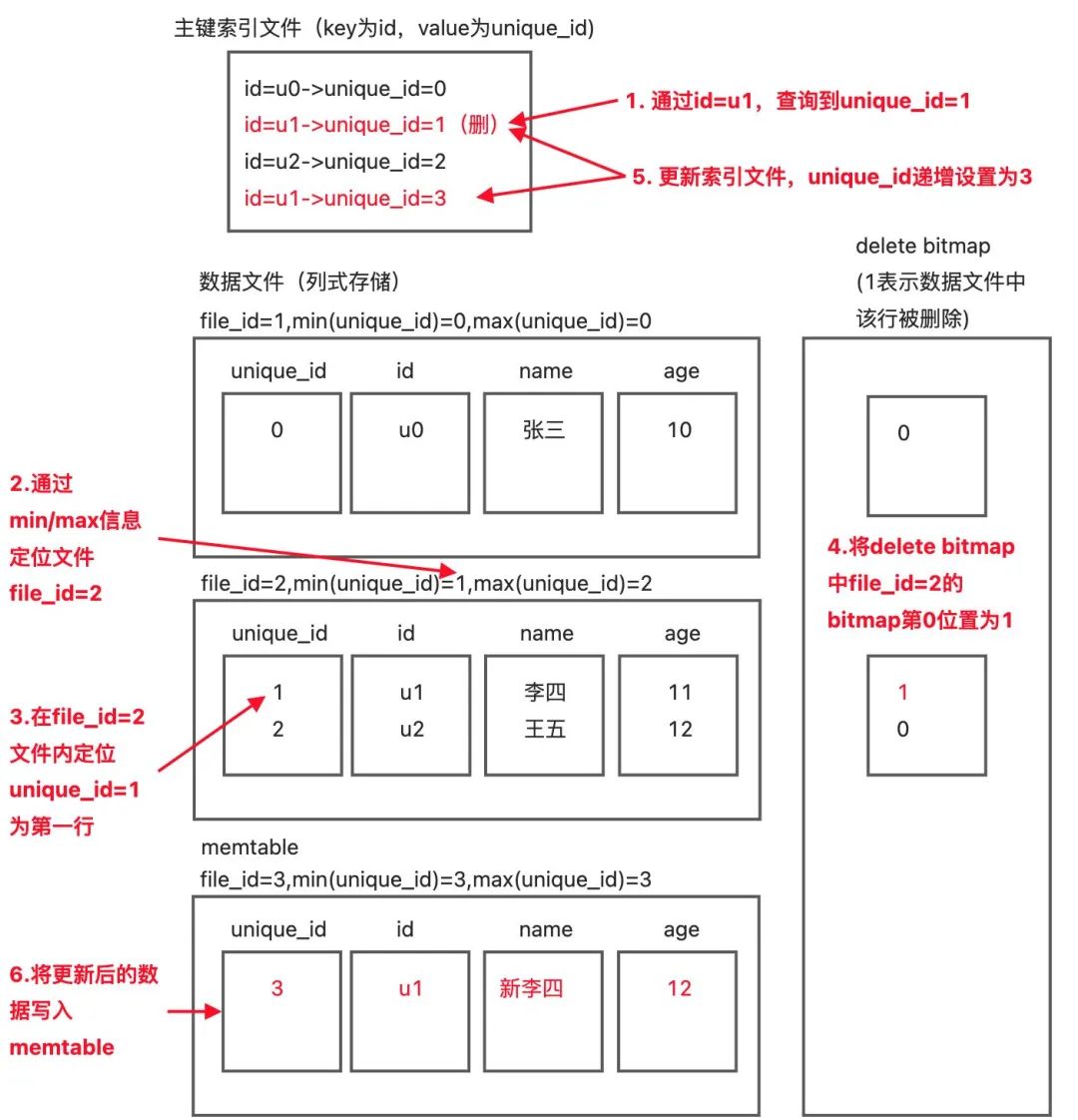
如果主键没有发生冲突,那么一次Upsert的的开销= 一次索引查询 + 两次内存写入操作; -
如果主键发生了冲突,那么一次Upsert的开销=一次索引查询 + 一次文件及行号定位 +三次内存写入操作。
3、Upsert示例
CREATE TABLE users ( id text not null, name text not null, age int, primary key(id));
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
INSERT INTO users VALUES ('u1','新李四',12) ON CONFLICT(id) DO UPDATE SET name = EXCLUDED.name, age = EXCLUDED.age;
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Hologres写入全链路优化,雕琢细节
1、Fixed Plan:降低、避免SQL解析与优化器的开销
-
Query Optimizer进行shortcut
-
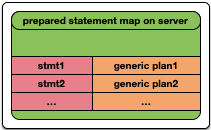
Prepared Statement
-
第一阶段:Client在Server端定义了一个带名字的Statement,并且生成了该Statement所对应的generic plan(不与特定的参数绑定的通用plan)。
-
第二阶段:用户通过发送具体的参数来执行第一阶段中定义的Statement。第二阶段可以重复执行多次,每次通过带上第一阶段中所定义的Statement名字,以及执行所需要的参数,使用第一阶段生成的generic plan进行执行。由于第二阶段可以通过Statement名字和附带的参数来反复执行第一个阶段所准备好的generic plan,因此第二个段在Frontend的开销几乎等同于0。
2、高性能的内部通信
-
Reactor模型、全程无锁的异步操作
-
高效的数据交换协议binary row
-
反压与凑批
3、稳定可靠的后端实现
-
基于C++纯异步的开发
-
IO优化与丰富的Cache机制
总结
Hologres是阿里巴巴自主研发的一站式实时数仓引擎,支持海量数据实时写入、实时更新、实时分析,支持标准SQL(兼容PostgreSQL协议),支持PB级数据多维分析(OLAP)与即席分析(Ad Hoc),支持高并发低延迟的在线数据服务(Serving),并在阿里巴巴双11等大促核心场景上,Hologres写入峰值达11亿条+/秒,经过大规模数据生产验证。
常见的数据仓库产品,大多都会牺牲读性能或者牺牲写性能,并且它们往往文件作为访问介质,这天然约束了数据更新的频率。Hologres 通过memtable使数据可以高频更新,通过delete map让读操作避免了join操作保持了良好的读性能,通过主键模型解决了写操作时的效率问题,做到了读写性能的兼顾。同时Hologres同Flink、Spark等计算框架原生集成,通过内置Connector,支持高通量数据实时写入与更新,支持源表、结果表、维度表多种场景,支持多流合并等复杂操作。
-
2020年VLDB的论文《 Alibaba Hologres: A cloud-Native Service for Hybrid Serving/Analytical Processing 》:http://www.vldb.org/pvldb/vol13/p3272-jiang.pdf -
Hologres揭秘: 首次公开!阿里巴巴云原生实时数仓核心技术揭秘:https://developer.aliyun.com/article/779118 -
Hologres揭秘: 首次揭秘云原生Hologres存储引擎:https://developer.aliyun.com/article/779284 -
Hologres揭秘: Hologres高效率分布式查询引擎:https://developer.aliyun.com/article/784506 -
Hologres揭秘: 高性能原生加速MaxCompute核心原理:https://developer.aliyun.com/article/784755 -
Hologres揭秘: 优化COPY,批量导入性能提升5倍+:https://developer.aliyun.com/article/785001 -
Hologres揭秘: 如何支持超高QPS在线服务(点查)场景:https://developer.aliyun.com/article/785647 -
Hologres揭秘: 从双11看实时数仓Hologres高可用设计与实践:https://developer.aliyun.com/article/829794
Hadoop 分布式资源管理框架 YARN
点击阅读原文查看详情。
登录查看更多
相关内容
专知会员服务
460+阅读 · 2020年7月7日
Arxiv
0+阅读 · 2022年8月29日

相关VIP内容
专知会员服务
460+阅读 · 2020年7月7日
相关资讯