一分钟破百亿GMV,阿里为什么钟爱 Flink ?| 极客时间

Flink 作为备受瞩目的新一代开源大数据计算引擎,已成为 Apache 基金会和 GitHub 最为活跃的顶级项目之一。
它在电商领域的应用尤为广泛,就拿天猫“双 11” ,这种一分钟破百亿成交额的场景为例,我们看到的实时展示商品数据(销售额、成交量等)的电子屏幕,他的背后就是 Flink 这套强大的流计算引擎在支撑。
可以说,在面对日益增长的数据规模,以及越来越低时延的数据处理需求,流处理已成为每家公司数据平台的必备能力。
目前主流的流计算技术有 Apache Storm,Spark Streaming 和 Apache Flink,但真正能同时做到低时延、Exactly-Once 数据一致性保障及高吞吐的,只有 Flink 一个。而且,Flink 同时支持流处理和批处理,解决了用批来模拟流的技术局限性。
所以,如果你要掌握未来大数据领域前瞻性技术,Flink 就是首选,随便搜一搜网上的招聘信息,也可以发现,Flink 研发的薪资也普遍偏高。
但是,Flink 的上手门槛比较高,API 不够直观和好用,不同使用模式的体验也不尽相同。所以,要真正掌握 Flink 并没有那么简单,比如:
长期做 Hive 或 Spark 等大数据项目的开发,但不知道如何用流数据处理;
遇到 Watermark 水印概念,不知道怎样用它来处理延时数据;
离线任务完成后的一段时间,Web 端没有显示或自动消失了;
Flink 集群搭建在 Yarn 上,如何实现高可用才能确保集群运行正常,以及 Kerberos 认证如何配置。
这些问题,我也曾有过,给你分享一个「Flink 知识图谱」,毕竟深入理解每个知识点,才能解决工作中的实际问题,建议收藏👇
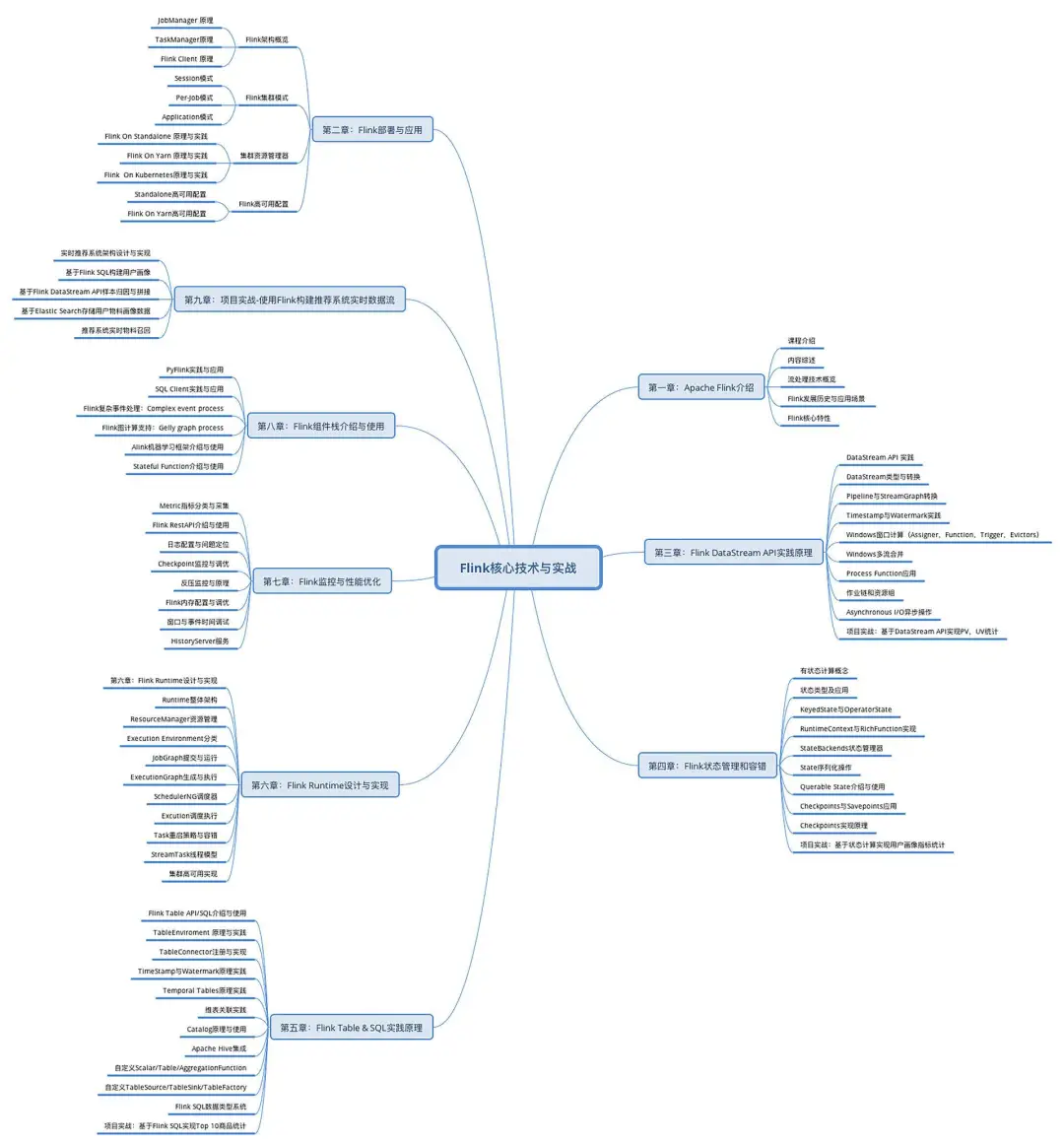
这张图谱出自张利兵,在 Flink 这块,他算是名副其实的 KOL了。
他是第四范式数据中台架构师,Apache Flink 社区贡献者。在大数据领域深耕 8 年了,主导过大型国有银行云计算平台产品研发和部署,以及大数据平台产品研发和实施,著有《Flink 原理、实战与性能优化》一书。
我最近刚看完他写的《Flink 核心技术与实战》视频课,很有启发。总结来说,深入剖析了 Flink Runtime 的设计与实现机制,讲解了 Flink SQL 接口的原理与操作方法,以及 Flink DataStream API 的实践原理,手把手教你构建一个完整的实时推荐数据流系统,让你彻底拿下 Flink。
课程原价¥199 了,现在 618 特惠,使用口令「618gogogo」立享 7 折优惠 !! 真的闭眼入,推荐给你。

618特惠 口令「618gogogo」
立享 7折,会员免费看
再来说说,他是怎么把 Flink 讲明白的。
我这些年学习流式计算和 Flink,总结出几个关键点:
了解数据处理过程中的基本模式,包括数据输入、处理和输出;
理解真实数据,因为流处理只是挖掘客观事实背后价值的手段,而只有真正理解数据,才能知道如何通过流计算产生价值;
深入理解 Flink 架构,例如流计算中的常见概念:有状态计算、数据一致性保障等等,这些是掌握流计算的重要前提。
这些张利兵在课程中都有一一讲解,值得一提的是:课程基于 Flink 最新 1.11.1 版本讲解,通过原理解读和实战练习,带你掌握 Flink 在实时开发过程中所涉及到的全部核心技术。
整体分为四部分:
一:Flink 基本概念。还有如何在不同的环境中安装 Flink 集群,让你对 Flink 有一个基本的认识;
二:Flink 作业的开发与实践。学习 DataStream API 和 Table ,以及 SQL 接口的使用与相应的原理解析。同时,每个章节末尾提供了对应的练习,加深你对 Flink 的掌握;
三:剖析 Flink 的核心原理。包括 Runtime 的设计与实现,常用的监控指标 Checkpoint 等等,带你了解这些指标底层的含义,以及如何在实际项目中对集群进行调优。
四:项目实战。通过一个完整的推荐项目,将所有知识点串联起来,让你真正理解和掌握 Flink。
这个视频课程一共 91 讲,全集更新完毕,口碑一级棒,我截图了一些留言可以给大家看看👇
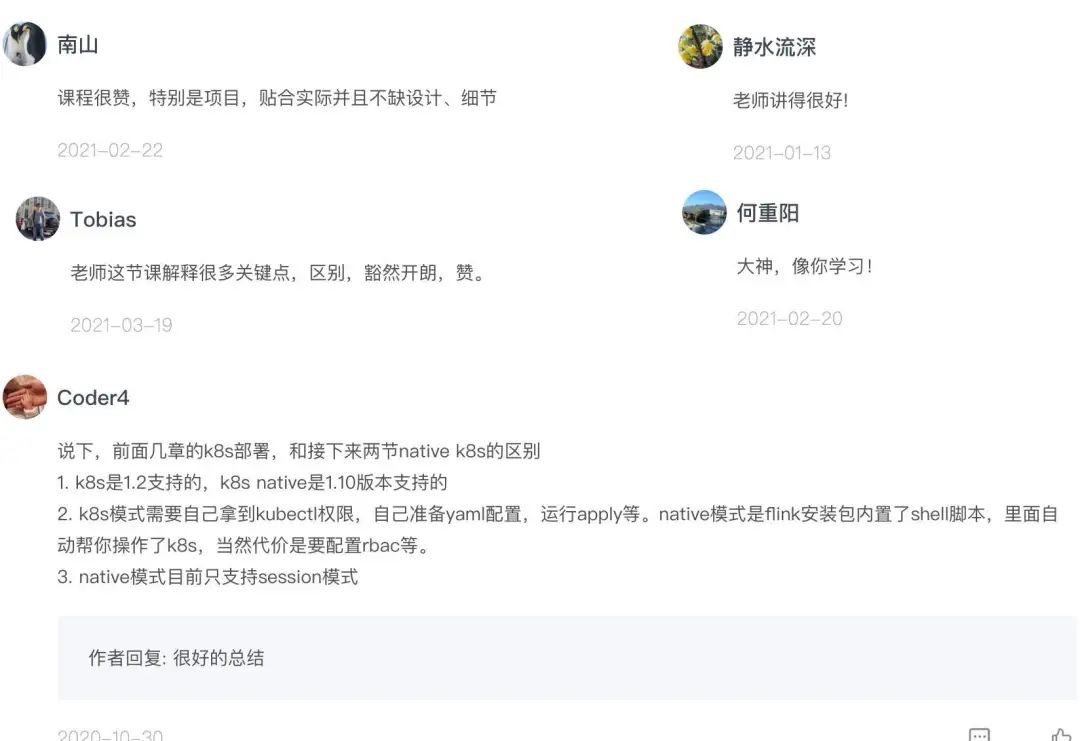
而且张利兵也非常真负责,基本上回复了每一条用户留言,内容也很走心,光看评论区就能学到不少。
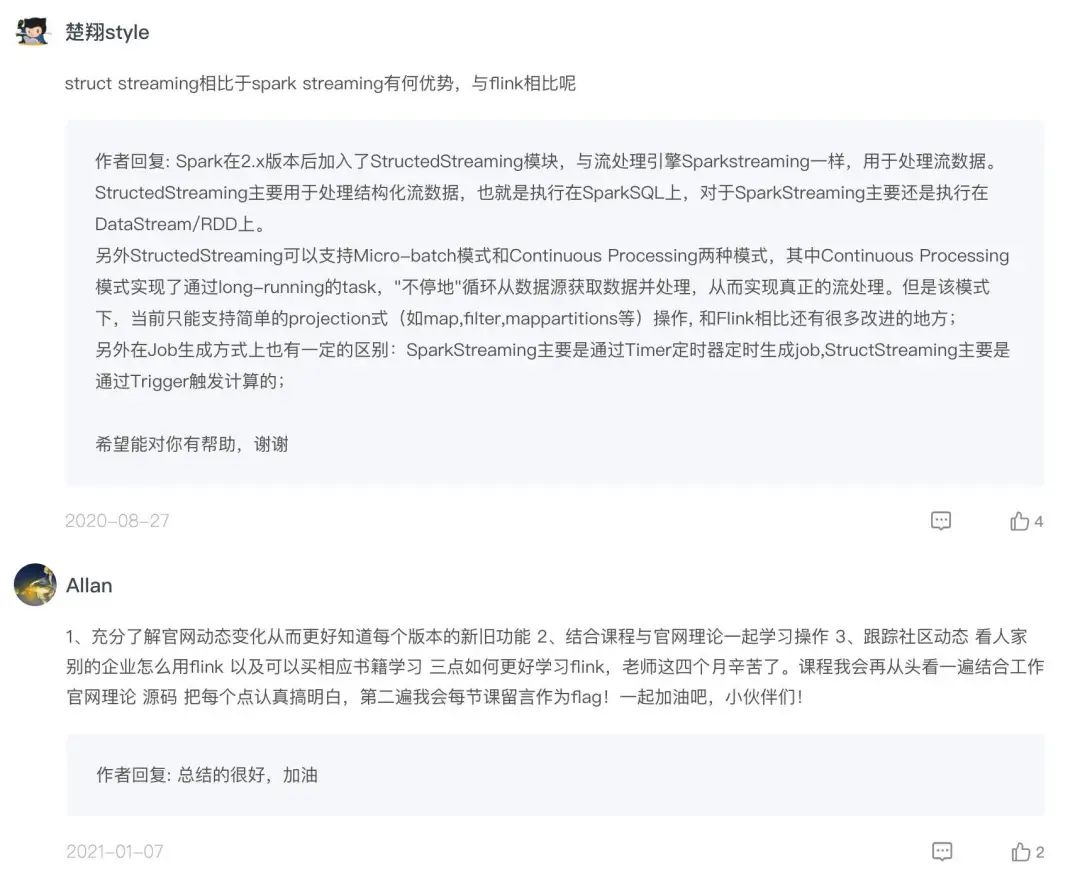
我有足够的把握,跟他学完这门课,你可以轻松解决工作中遇到的开发难题,提升流式数据处理能力,从而真正掌握 Flink。
说了那么多,先看看目录吧👇

是不是内容很丰富?反正我看完是走不动道了。
总的来说,绝对值得你一看。
最后再和大家强调一下:
618 特惠口令「618gogogo」
7折 到手,课程原价 ¥199

👆👆👆
扫码免费试读
一顿饭的钱,成为一个合格的 Flink Boy ,就是这么简单。
点击【阅读原文】,拿下未来大数据领域前瞻性技术。

