PAKDD 2019 AutoML3+竞赛结果公布,解读冠军团队解决方案
机器之心发布
作者:罗志鹏(深兰科技)
近日,PAKDD 2019 AutoML3+ 挑战赛公布了最终结果:Feedback phase 和 AutoML phase 的 Top3 排名相同,深兰科技 DeepBlueAI 团队斩获第一名,由微软亚洲研究院、北航组成的 ML Intelligence 团队位居第二名,由清华大学组成的 Meta_Learners 团队获得第三名。

PAKDD 是数据挖掘领域历史最悠久,最领先的国际会议之一。它为研究人员和行业从业者提供了一个国际论坛,供大家分享在 KDD 相关领域的新想法,原创研究成果和实践开发经验。
大赛简介
在人工智能的时代,许多实际应用程序都依赖于机器学习,然而这些程序的开发人员却并不都具备专业的机器学习算法研发能力,因而非常需要部署 AutoML 算法来自动进行学习。
此外,有些应用中的数据只能分批次获取,例如每天、每周、每月或每年,并且数据分布随时间的变化相对缓慢。这就要求 AutoML 具备持续学习或者终生学习的能力。
这一类的典型问题包括客户关系管理、在线广告、推荐、情感分析、欺诈检测、垃圾邮件过滤、运输监控、计量经济学、病人监控、气候监测、制造等。本次 AutoML for Lifelong Machine Learning 竞赛将使用从这些真实应用程序中收集的大规模数据集。
相比于与之前的 AutoML 比赛,本次比赛的重点是概念漂移,即不再局限于简单的 i.i.d. 假设。要求参与者设计一种能够自主(无需任何人为干预)开发预测模型的计算机程序,利用有限的资源和时间,在终身机器学习环境下进行模型训练和评估。
本次比赛分为 Feed-Back 阶段及 Blind-Test 阶段:
Feedback phase : 反馈阶段是代码提交的阶段,可以在与第二阶段的数据集具有相似性质的 5 个数据集上进行训练和测试。最终代码提交将转发到下一阶段进行最终测试。
AutoML phase:该阶段不需要提交代码。系统自动使用上一阶段的最后一次提交的代码对 5 个新数据集进行盲测。代码将自动进行训练和预测,无需人工干预。最终得分将通过盲测的结果进行评估。
这次竞赛主要有以下难点:
算法可扩展性:比赛提供的数据集比之前组织的竞赛大 10 到 100 倍;
不同的特征类型:包括各种特征类型(连续,二元,顺序,分类,多值分类,时间);
概念漂移:数据分布随着时间的推移而缓慢变化;
终身环境:本次比赛中包含的所有数据集按时间顺序分为 10 批,这意味着所有数据集中的实例批次按时间顺序排序(请注意,一批中的实例不保证按时间顺序排列)。参与者的算法需要基于前面批次的数据进行训练来预测后一批次的数据,从而测试算法适应数据分布变化的能力。测试后,才能把当前的测试集纳入训练数据中。
大赛结果
本次比赛在五个不同任务数据集上以 AUC 作为评分指标,官方排名规则是把 5 个任务的 Rank(在所有队伍中的排名)值进行平均做为最后的排名依据。DeepBlueAI 团队在 Feedback phase 的 5 项测试任务中斩获了 4 项第一、1 项第二的优异成绩,其中 4 项任务的 AUC 指标大幅度胜出。团队的 Rank 平均指标为 1.2,在所有队伍中具有显著的领先优势。
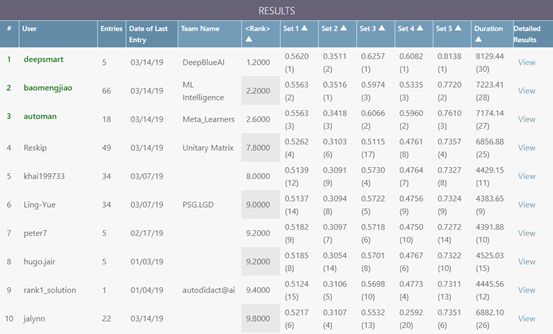
图 1 Feedback phase 排行榜
对比 Feedback phase 的 Top3 队伍的 AUC 指标,DeepBlueAI 团队在 Set1、Set3、Set4、Set5 的 4 个数据集上分别领先各 Set 第二名 0.57%、1.91%、1.22%、4.18%,在 Set2 上也只比最好的差 0.05%。
AUC 指标是一项相对而言很难提升的指标,通常在竞赛中 top 队伍只能在该指标上拉开千分位、万分位的差距,而 DeepBlueAI 团队在 Set1,3,4,5 这 4 个不同任务上平均领先第二名 1.97%,具有非常明显的优势。

图 2 Top3 AUC 指标对比
Feedback phase 榜单链接:https://competitions.codalab.org/competitions/20675#results
在 AutoML phase 中, 深兰科技的 DeepBlueAI 团队也稳住了 5 项任务总成绩排名第一,Top3 排名如下:

AutoML phase Top3
AutoML phase Top3 排名链接:https://www.4paradigm.com/competition/pakdd2019
冠军团队解决方案
我们团队基于所给数据实现了一个 AutoML 框架,包括自动特征工程、自动特征选择、自动模型调参、自动模型融合等步骤,在类别不平衡的处理上我们使用了自适应采样并在模型训练上有一定的创新,我们也有针对性的对概念漂移问题进行处理,并且利用了多种策略对运行时间和运行内存进行了有效的控制,以确保解决方案能在限制时间和内存下完成整个流程。
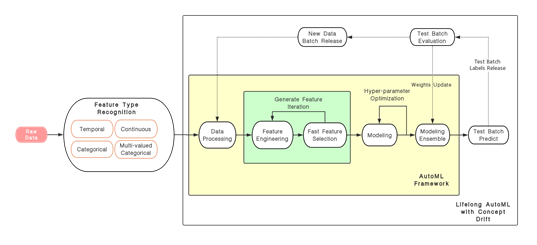
(1)自动特征工程
在大部分机器学习工业界应用中,数据和特征对于模型往往是最为关键的,在现有的 AutoML 框架中,大部分特征的提取是基于已有的数值特征进行高阶组合,它们的模型很难提取出跟时序问题或者概念漂移有关的关键特征,而且忽略了类别特征的重要性,然而现实中存在大量的时序问题,而且往往带有概念漂移。
我们构建的自动特征工程不仅是基于时间特征、分类特征、数值特征、多值分类特征做特征间的高阶组合,同时我们自动提取跨时间、样本以及特征的高阶组合。这是我们团队所做出的不同于以往模型的自动特征工程方案,同是也是我们在比赛中能取得显著优势的重要因素。并且我们实现了一个自动快速特征选择方法,进而提取重要特征进行高阶组合,从而避免了指数级的特征组合,并且能挖掘三阶甚至四阶不同类型的特征组合,有效地提升模型性能。
(2)自动快速特征选择
高阶组合往往容易导致生成大量特征,一般的特征选择方法是进行穷举搜索,这在大量特征的基础上是不可接受的。我们的自动快速特征选择首先过滤掉方差低的特征,以及通过特征的相似性计算删除相似性特征,并且结合特征重要性及序列后向选择算法,忽略重要性低的特征,这能过滤掉大量的特征并且对于模型的精度影响很小,并且极大地加速了后续的模型训练和预测速度。然后我们进行序列后向选择算法,对重要性极高的特征进行筛选,这能快速地筛选掉过拟合特征,从而大幅度提高模型性能。
(3)缓解类别不平衡
自适应采样:能够自动针对数据情况(数据大小,数据类型不同),以及比赛时间的限制等各种因素的不同,自适应地对数据采取不同的采样方式和比例。既保证了效率的同时又保证了效果。
数据训练方式创新:传统的类别不平衡的数据训练方式,是通过提前对数据进行采样,缓解类别不平衡问题,然后将数据加入模型中训练。但是这样会损失大量的数据信息,所以我们在数据采样的时候,仍然保留大量的高比例样本,并且将其分批,在加入模型中训练时,让模型轮流训练这些批次,这样能够尽可能保留更多的原始数据的信息,同时缓解了类别不平衡问题。
(4)抗概念漂移处理
自适应数据融合:针对数据大小,数据复杂度,自适应选择 batch 数目。同时,对于每个 batch,加入了「不同 batch 间采样率随时间增加」机制。
抗概念漂移特征:特征工程时,加入了大量关于不同 batch 数据之间的信息,实现了抗概念漂移特征。
(5)时间空间优化
针对代码进行了优化,在实现一些复杂操作时,预先进行评估,通过合理的采样,以及代码实现方式,来减少内存的使用以及时间的使用。
(6)模型构建
我们采用了业界常用的 GBDT 模型,其中 GBDT 模型常用的有 LightGBM,XGBoost,CatBoost 等模型,它们基于信息增益学习特征间的高阶非线性组合。其中 LightGBM 模型的运行速度和效果都表现得不错,所以我们采用了 LightGBM 模型。
同时我们引入了深度学习模型,对 Category 类型数据提取 Embedding 特征,将 Embedding 特征以及其余特征进行拼接构建 LightGBM 模型。
(7)自动模型调参
我们通过验证集采用随机搜索自动调整模型学习率、叶子结点、树的深度、行采样及列采样等。
(8)自动模型融合
基于所给时间,我们使用不同的行采样及列采样来训练多个不同的模型,这不仅仅更加充分的利用了样本,也使得每个模型使用的数据和特征具有充分的差异性,同时大大减少了过拟合的风险。一般 GBDT 模型和深度学习模型融合的时候,会单独进行融合,而本次竞赛中,这种融合方式效果提升并不明显,由于时间的限制,深度学习模型在表数据上表现力并不强。
所以我们利用深度学习模型对数据进行 embedding,将 embedding 特征加入到 GBDT 模型中进行训练学习,产生两类不同的模型(使用和不使用 embedding 特征),再对其进行融合。
总结
机器学习的理论进步为产业发展持续赋能,但在应用中还是存在模型训练难和效率低的问题。AutoML 意在构建整套从机器学习模型构建到应用的自动化框架,从而降低应用门槛,缩短项目开发周期,促进机器学习的大规模落地。因此,作为系统级的应用,AutoML 的研发更为复杂。
本次 PAKDD 竞赛延续了 NeurIPS 2018 AutoML 竞赛,并完善了一些竞赛规则问题,竞赛体验得到提高。感谢主办方辛勤的付出,为 AutoML 开发者提供了一次完美的同台竞技分享交流的机会。也感谢所有的参赛队伍让我们不断的优化和完善我们的 AutoML 框架,在角逐中为迸发各自的想法,为 AutoML 框架的各个环节提供了新的思路,取得了效果突破的同时也推进了 AutoML 的发展。
AutoML 领域的研究和产品开发越来越活跃,展现出了强大的发展潜力和空间,也会加速推动 AutoML 在各个垂直领域的应用落地。祝贺所有的 Top 队伍,愿大家在未来都能取得自己满意的成绩!
DeepBlueAI 团队介绍
团队主要成员来自深兰科技,拥有多年的机器学习经验,专注自然语言处理、计算机视觉、AutoML 方面研究。在 PAKDD2019、KDD cup2018、NeurIPS 2018 AutoML、CIKM Cup 2018 等国际知名比赛中多次取得冠军的优异成绩。

本文为机器之心发布,转载请联系本公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者 / 实习生):hr@jiqizhixin.com
投稿或寻求报道:content@jiqizhixin.com
广告 & 商务合作:bd@jiqizhixin.com


