Stable Diffusion火到被艺术家集体举报,网友科普背后机制被LeCun点赞
白交 发自 凹非寺
量子位 | 公众号 QbitAI
免费开源的Stable Diffusion太火了!
有人拿它来做视频短片,几分钟内穿越时间看遍地球万物的演变。
还有人拿它来制作守望先锋里的英雄。

甚至因为使用过于泛滥,牵涉到艺术版权的问题,一群艺术家们还吵了起来,并把一个非官方账号举报到封号。
这背后究竟是如何运作的,才能形成如此惊人的反响?
这几天,有位小哥分享了Stable Diffusion工作机制的线程,还被LeCun点了赞。
来看看究竟说了啥。
又是扩散模型
首先,从名字Stable Diffusion就可以看出,这个主要采用的扩散模型(Diffusion Model)。
简单来说,扩散模型就是去噪自编码器的连续应用,逐步生成图像的过程。
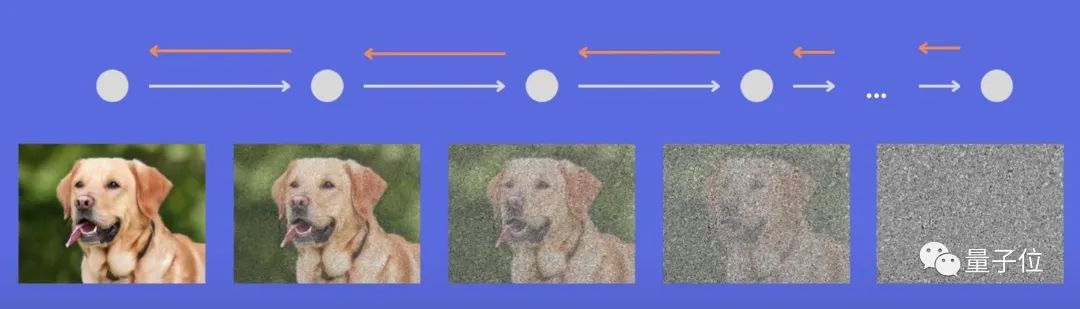
一般所言的扩散,是反复在图像中添加小的、随机的噪声。而扩散模型则与这个过程相反——将噪声生成高清图像。训练的神经网络通常为U-net。
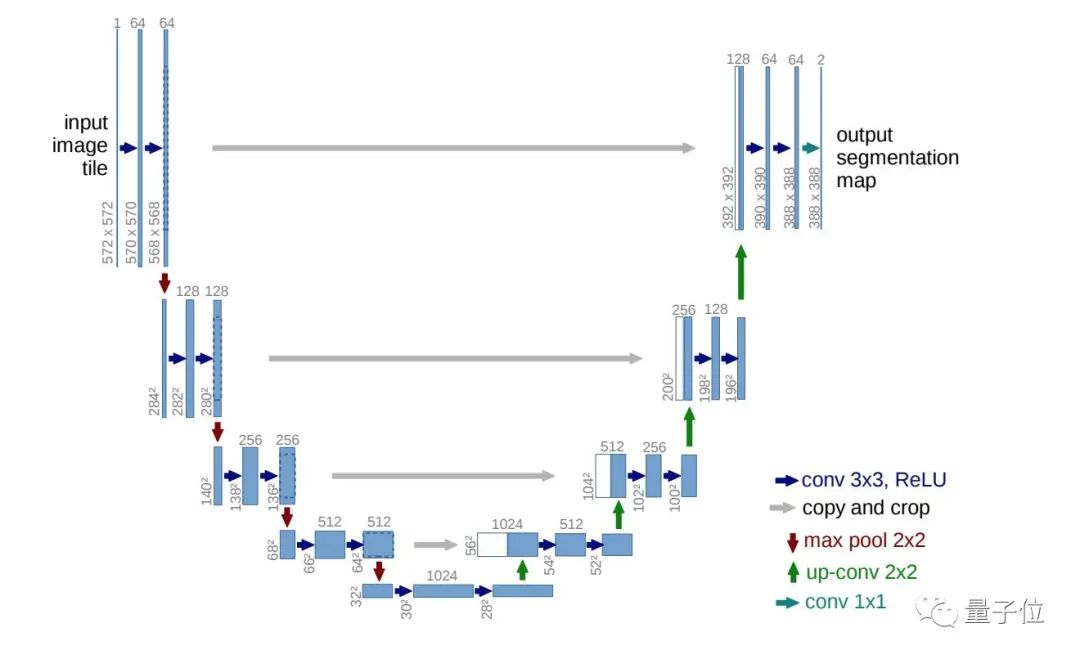
不过因为模型是直接在像素空间运行,导致扩散模型的训练、计算成本十分昂贵。
基于这样的背景下,Stable Diffusion主要分两步进行。
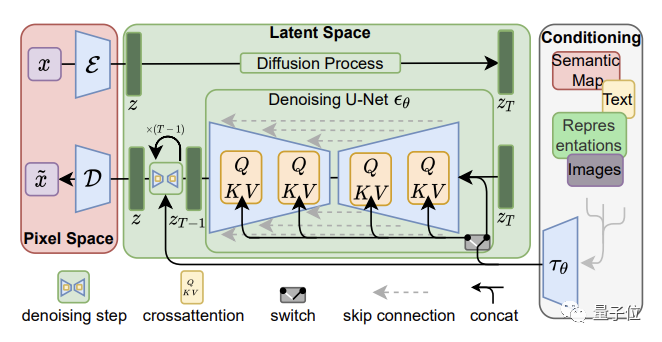
首先,使用编码器将图像x压缩为较低维的潜在空间表示z(x)。
其中上下文(Context)y,即输入的文本提示,用来指导x的去噪。

它与时间步长t一起,以简单连接和交叉两种方式,注入到潜在空间表示中去。
随后在z(x)基础上进行扩散与去噪。换言之, 就是模型并不直接在图像上进行计算,从而减少了训练时间、效果更好。
值得一提的是,Stable DIffusion的上下文机制非常灵活,y不光可以是图像标签,就是蒙版图像、场景分割、空间布局,也能够相应完成。


霸占GitHub热榜第一
这个平台一开源,就始终霸占GitHub热榜第一,目前已累计2.9k星。

它是由慕尼黑大学机器视觉与学习研究小组和Runway的研究人员,基于CVPR2022的一篇论文《High-Resolution Image Synthesis with Latent Diffusion Models》,并与其他社区团队合作开发的一款开源模型。

据官方介绍,它能在几秒内在消费级CPU上运行创作,也无需进行任何预处理和后处理。
核心数据集是LAION-5B的一个子集,它是专为基于CLIP的新模型而创建。
同时,它也是首个在4000个A100 Ezra-1 AI超大集群上进行训练的文本转图像模型。
不管怎么说,在文本生成图像这一趴,又多了一位实力强劲的明星了。(狗头)
GitHub链接:
https://github.com/CompVis/latent-diffusion
参考链接:
[1]https://twitter.com/ai__pub/status/1561362542487695360
[2]https://stability.ai/blog/stable-diffusion-announcement
[3]https://arxiv.org/abs/2112.10752
— 完 —
「计算生物学深度产业报告 · 量子位智库」下载
和数十家企业进行沟通交流并广泛调研后,量子位智库撰写了《计算生物学深度产业报告》,扫描下方二维码可下载完整报告。


量子位 QbitAI · 头条号签约作者
վ'ᴗ' ի 追踪AI技术和产品新动态
一键三连「分享」「点赞」和「在看」
科技前沿进展日日相见 ~





