可生成高清视频的Stable Diffusion来了!分辨率提升4倍,超分算法来自腾讯,支持Colab在线试玩
明敏 发自 凹非寺
量子位 | 公众号 QbitAI
免费玩的Stable diffusion,又出新变种了!

古典人像丝滑切换,还都是4倍超分辨率水平,细节也就多了亿点点吧,眉毛发丝都根根分明。

还能从一盘草莓意大利面,丝滑变成一份蓝莓面。

这就是最近在推特上火了Stable Diffusion视频版2.0.
它能够通过Real-ESRGAN进行上采样,让生成画面达到4倍超分。

要知道,之前Stable Diffusion生成的图像如果想要高清,还得自己手动提升分辨率。
现在直接二合一,在谷歌Colab上就能跑!
食用指南
Colab上的操作非常简单,基本上就是傻瓜式按照步骤运行即可。
需要注意的是,过程中要从个人Hugging Face账户中复制token登入。
拉取模型前,记得在Hugging Face上授权,否则会出现403错误。
搞定以上问题后,就能来用Stable Diffusion来生成高清视频了。
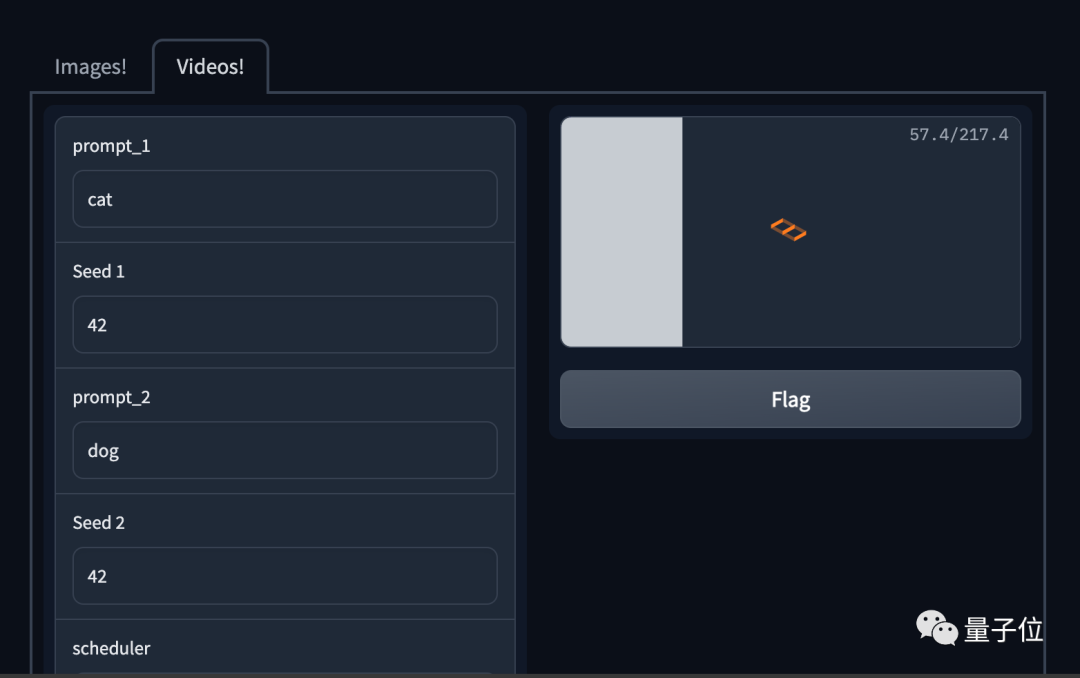
生成一段视频需要给出2个提示词,然后设置中间的步数,以及是否需要上采样。
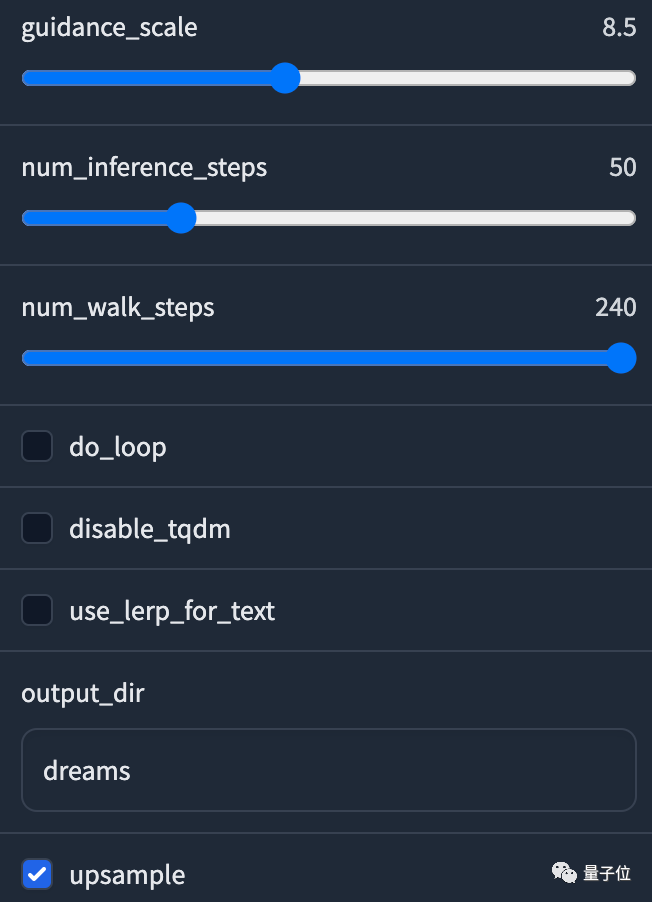
中间步骤越多,生成所需的时间越长;同样上采样也会一定程度上加长生成时间。
还能直接用代码来跑,修改几个简单的参数就能搞定。

除了线上模式外,该模型还支持本地运行,项目已在GitHub上开源。
注意需要额外安装Real-ESRGAN。
超分算法来自腾讯
简单来说,这次Stable Diffusion的变种版本就是把生成的图片,通过超分辨率方法变得高清。
Stable Diffusion的原理,是扩散模型利用去噪自编码器的连续应用,逐步生成图像。
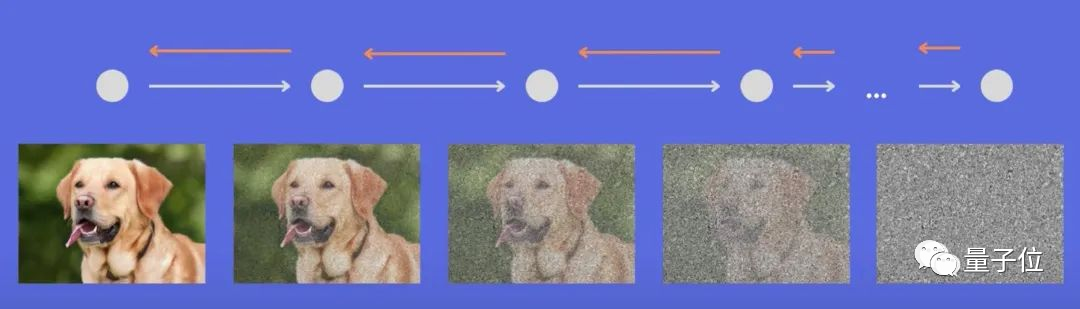
一般所言的扩散,是反复在图像中添加小的、随机的噪声。而扩散模型则与这个过程相反——将噪声生成高清图像。训练的神经网络通常为U-net。
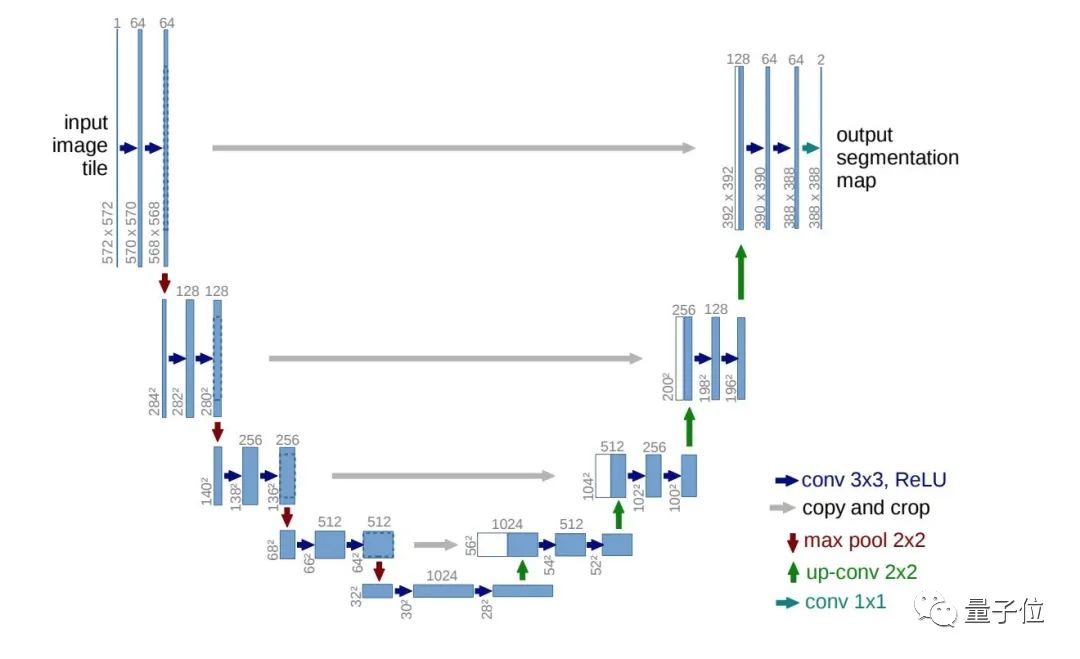
不过因为模型是直接在像素空间运行,导致扩散模型的训练、计算成本十分昂贵。
基于这样的背景下,Stable Diffusion主要分两步进行。
首先,使用编码器将图像x压缩为较低维的潜在空间表示z(x)。
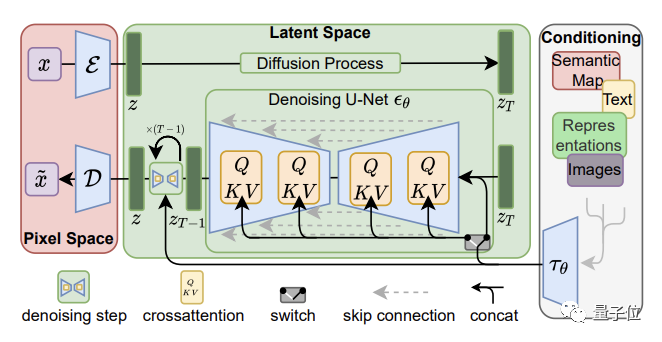
其中上下文(Context)y,即输入的文本提示,用来指导x的去噪。

它与时间步长t一起,以简单连接和交叉两种方式,注入到潜在空间表示中去。
随后在z(x)基础上进行扩散与去噪。换言之, 就是模型并不直接在图像上进行计算,从而减少了训练时间、效果更好。
再来看超分辨率部分。
用到的方法是腾讯ARC实验室此前开发的Real-ESRGAN,被ICCV 2021接收。

它可以更有效地消除低分辩率图像中的振铃和overshoot伪影;
面对真实风景图片,能更逼真地恢复细节,比如树枝、岩石、砖块等。

原理方面,研究人员引出了高阶退化过程来模拟出更真实全面的退化,它包含多个重复的经典退化过程,每个又具有不同的退化超参:
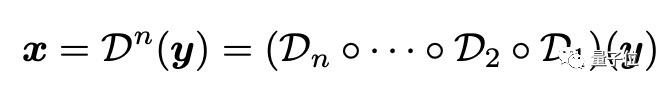
下图为Real-ESRGAN进行退化模拟的示意图:
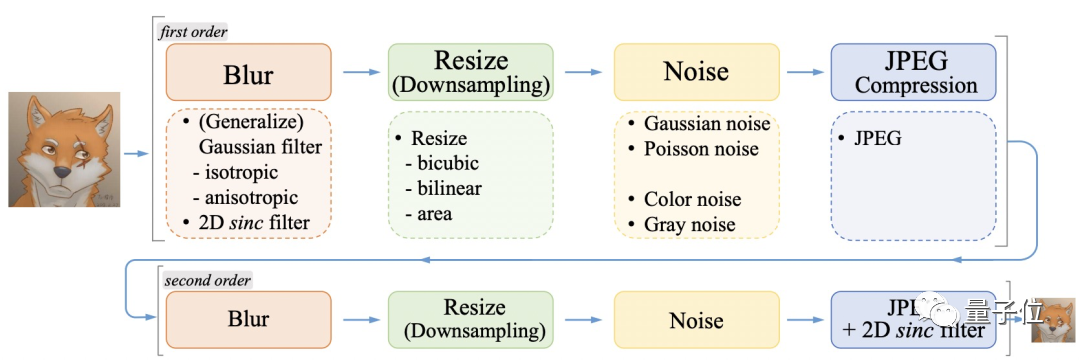
采用的是二阶退化,具体可分为在模糊(blur)、降噪(noise)、resize、JPGE压缩几个方面。
到训练环节,Real-ESRGAN的生成器用的是RRDBNet,还扩展了原始的×4 ESRGAN架构,以执行resize比例因子为×2和×1的超分辨率放大。
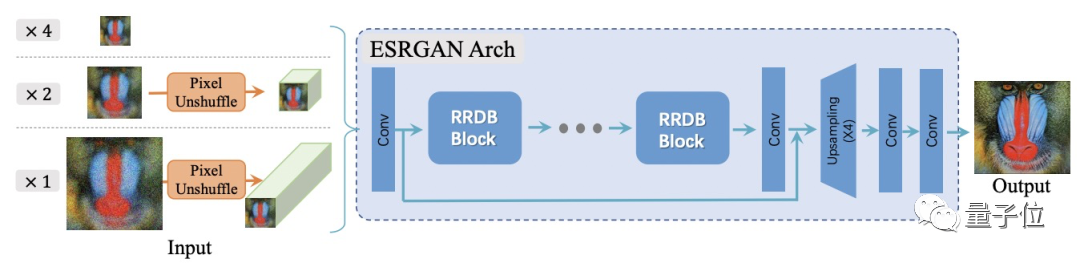
想要单独使用这种超分算法也不是问题。
在GitHub上下载该模型的可执行文件,Windows/Linux/MacOS都可以,且不需要CUDA或PyTorch的支持。

下好以后只需在终端执行以下命令即可使用:
./realesrgan-ncnn-vulkan.exe -i input.jpg -o output.png
值得一提的是,Real-ESRGAN的一作Wang Xintao是图像/视频超分辨率领域的知名学者。
他本科毕业于浙江大学本科,香港中文大学博士(师从汤晓鸥),现在是腾讯ARC实验室(深圳应用研究中心)的研究员。
此前曾登顶GitHub热榜的项目GFPGAN也是他的代表作。

One More Thing
前两天,大谷老师也发布了用Stable Diffusion生成了一组少女人像,效果非常奈斯。

顺带让我们都完成了一下“阅女无数”的成就(doge)。
Stable Diffusion还能玩出哪些新花样?你不来试试吗?
Colab试玩:
https://colab.research.google.com/github/nateraw/stable-diffusion-videos/blob/main/stable_diffusion_videos.ipynb
GitHub地址:
https://github.com/nateraw/stable-diffusion-videos
Hugging Face授权:
https://huggingface.co/CompVis/stable-diffusion-v1-4
参考链接:
[1]https://twitter.com/_nateraw/status/1569315090314444802
[2]https://www.bilibili.com/video/BV1yd4y1g7Wz?spm_id_from=333.999.0.0
— 完 —
「人工智能」、「智能汽车」微信社群邀你加入!
欢迎关注人工智能、智能汽车的小伙伴们加入我们,与AI从业者交流、切磋,不错过最新行业发展&技术进展。
PS. 加好友请务必备注您的姓名-公司-职位哦 ~

点这里👇关注我,记得标星哦~
一键三连「分享」、「点赞」和「在看」
科技前沿进展日日相见~


