编辑:小咸鱼 好困
【新智元导读】近日,一位博士给乐高小车装了个「大脑」,并且还让它学会了走迷宫!研究成果已在《Science Advances》发表。
有一种经典的游戏叫走迷宫。
迷宫,往往只有一个入口,一个出口,可是中间能选择的走法却是不胜枚举。
而人类为什么能快速找到走出迷宫的方法呢?
为研究大脑在走迷宫的任务中究竟是怎么想的,科学家们必须先找一个简单的案例,于是,他们把目光转移到了小鼠身上。
2016年,浙江大学吴朝晖课题组的研究人员在Nature子刊《Scientific Reports》发表了一篇论文,描述了一种结合了小鼠和强化学习算法的混合脑机系统。
![]()
https://www.nature.com/articles/srep31746
实验组小鼠的大脑都被植入了电极并连接上了计算机。
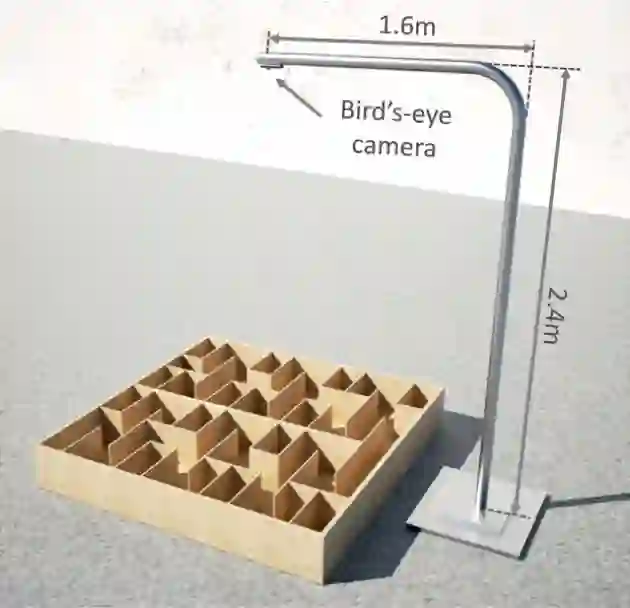
研究人员在小鼠大脑的内侧前脑束(MFB)植入电极,小鼠背上的背包会接收MFB的刺激参数,并且往小鼠大脑输入刺激脉冲。从迷宫上方鸟瞰的摄像头会记录下小鼠的运动和方位。
当小鼠走迷宫时,计算机上运行的学习算法(采用的是强化学习算法Q-Learning)会根据摄像头传来的视频输入计算MFB的刺激参数(电压、频率、占空比和脉冲数),从而对小鼠进行指导。
每次走迷宫,小鼠都必须在全部6个决策点进行正确的决策,才能在终点获得奖励(水)。而在一次走迷宫试验中,只要小鼠连续3次成功到达终点,就可以认为它学会了走这个迷宫。
实验中,小鼠在迷宫中不断行走,Q-Learning算法也生成了奖励地图。根据小鼠的位置和奖励地图,算法生成了实时的MFB刺激参数,指导着小鼠在迷宫中行走。
结果是,被「增强」后的小鼠在走迷宫任务中表现出了强大的学习能力,试了3次就走出了中途需要进行6次决策的迷宫,而没有强化学习算法指导的对照组需要走6次才能走出迷宫。
这个实验也说明了小鼠在迷宫中进行探索的时候,其大脑的学习过程类似于一个弱化版本的Q-Learning算法,本质也是在根据自己的位置和记忆中的地图进行决策。
虽说只靠大脑慢是慢了些,但还是能完成任务,而且肯定比计算机节能环保啊。
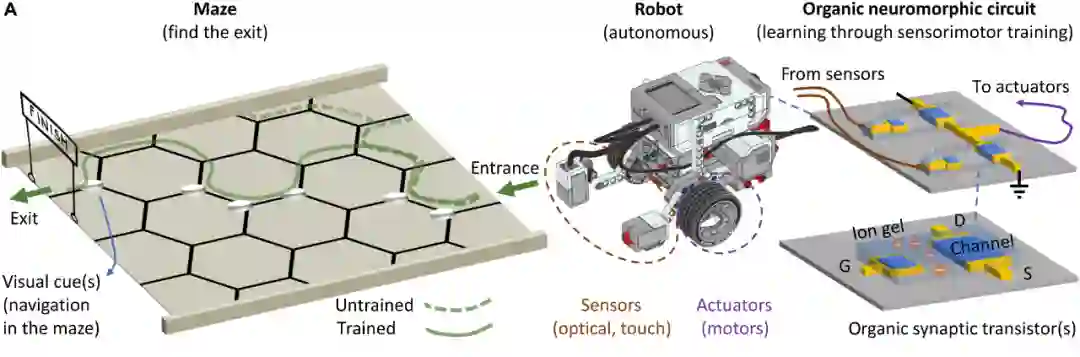
那么,如果把类似大脑的神经形态电路放到机器人身上,它们能学会在曲折的迷宫中穿梭吗?
近日,来自埃因霍温科技大学(TU/e)、马克斯·普朗克聚合物研究所、斯坦福大学和剑桥大学的研究人员给出了证明,并将成果发表在了《Science Advances》上。
https://www.science.org/doi/10.1126/sciadv.abl5068
机器学习和神经网络被应用于图像识别、医疗诊断等领域。尽管如此,这种基于软件的机器智能方法仍有其缺点,尤其是需要消耗大量的能源。
为了找到一个解决方案,研究人员开始在大脑中寻找灵感。
人脑可以将记忆和处理结合在一起,其中的神经元通过突触相互沟通,每次信息流经它们时,突触都会得到加强,而这种可塑性也确保了人类的记忆和学习。
于是,研究人员也把机器人的决策建立在人类用于思考和行动的系统之上:大脑。
机器人对目标任务的处理和学习是通过一个有机神经形态电路在本地实现的,经过不断地学习,最终走出迷宫。
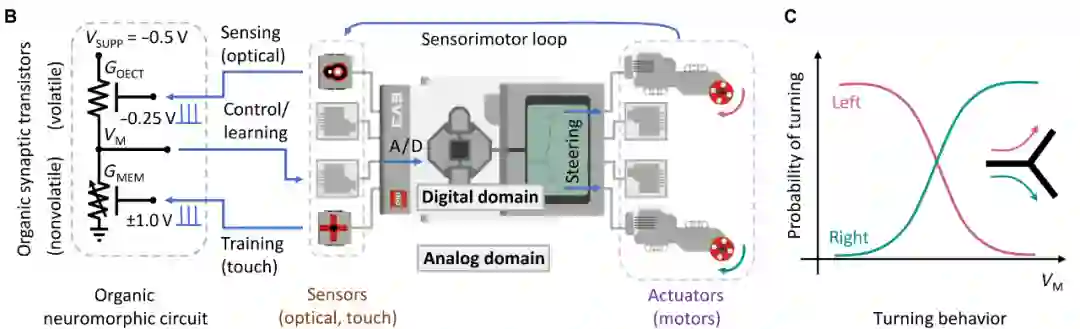
机器人感知运动系统的静态、低级控制是由数字领域的中央单元进行的。感知运动系统和有机神经形态电路在模拟域运行,控制单元(数字)和感知运动系统/神经形态电路(模拟)之间建立了一个实时的感知运动回路。
神经形态电路由有机突触晶体管组成:一个易失性(OECT)和一个非易失性(MEM)装置。
运行时,神经形态电路接收光机械感觉信号(在GOECT和GMEM器件的门上)以感知(适应)环境刺激,并向机器人的执行器发送运动指令(VM)以进行运动。
最终,神经形态电路通过训练形成了完成目标任务所需的感觉运动关联。
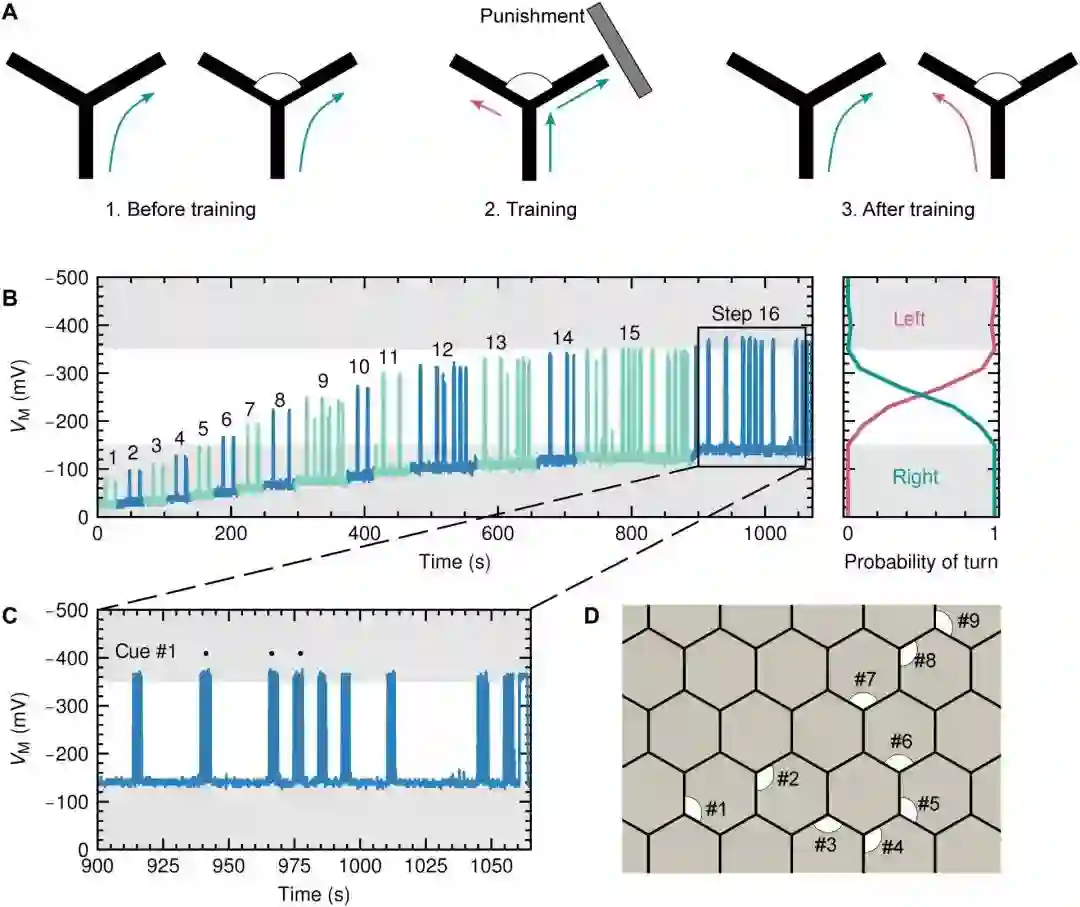
「正如小鼠大脑中的突触每次在迷宫中正确转弯时都会得到加强一样,我们通过施加一定量的电刺激来对机器人的『大脑』进行微调。」TU/e机械工程系的博士生、论文的主要作者Imke Krauhausen解释道。
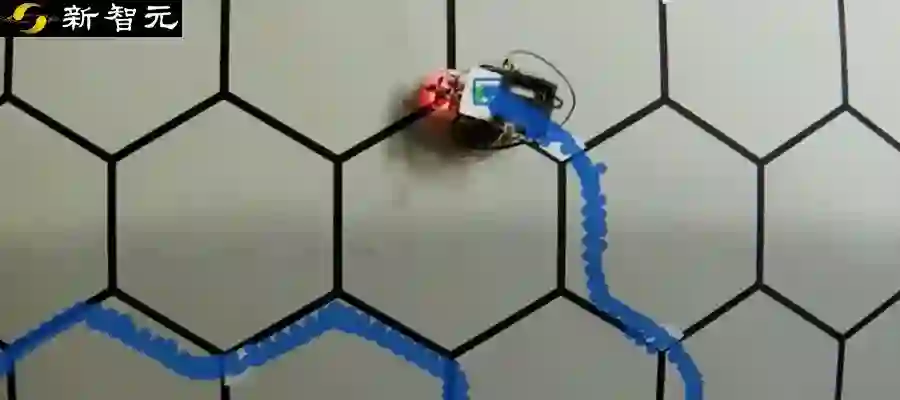
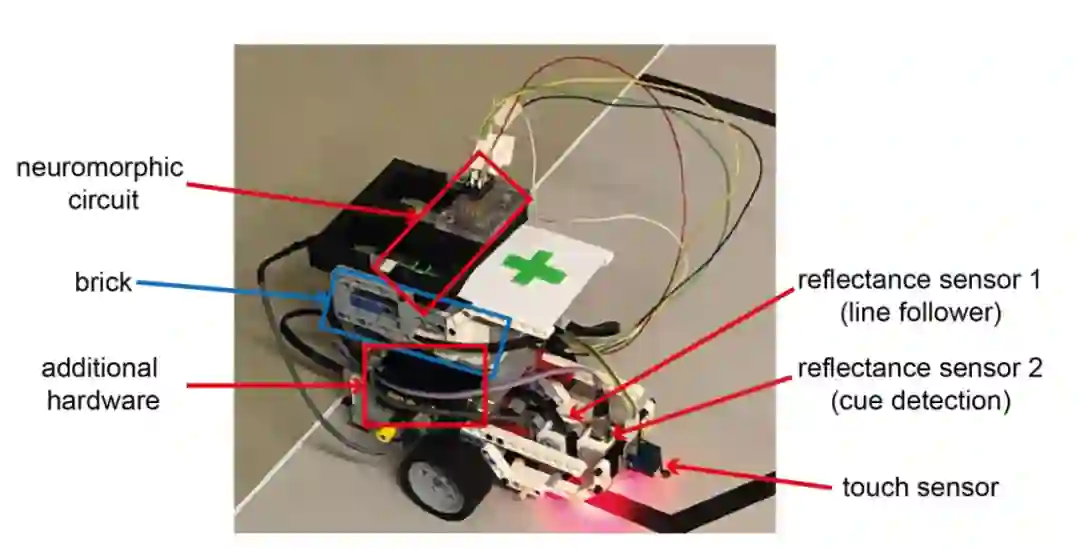
机器人基于乐高的Mindstorms EV3平台打造,除了有2个轮子和传统的引导软件来确保它能沿着线走以外,还有一些反射和触觉传感器。
实验场地是一个由黑色的六边形组成的蜂窝状迷宫,面积为2平方米。
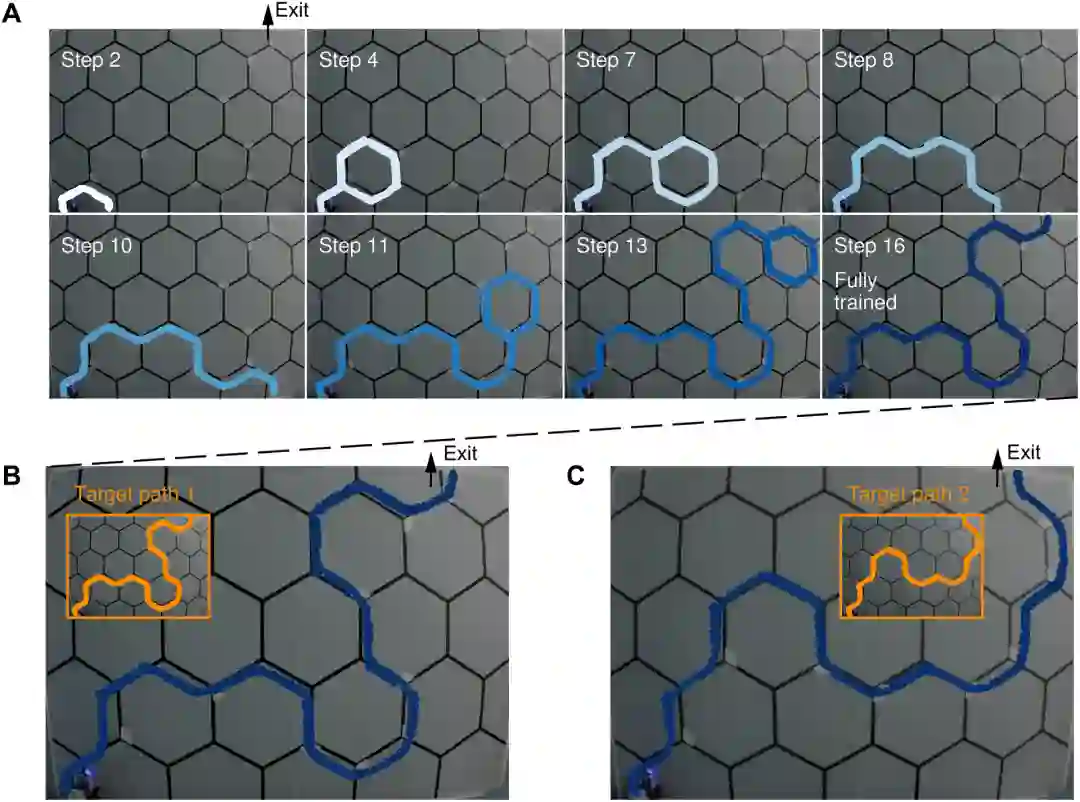
最初,机器人的视觉-运动关联尚未建立,默认只会向右转。每当它到达死胡同或偏离了指定的路径时,电刺激就会强化这种关联,告诉机器人要么返回要么向左转。
然后,通过将这种纠正性刺激储存在神经形态的「大脑」当中,机器人对导航线索的敏感性也进一步增强,并在之后的尝试中能够做出更加准确的决策。
此时,视觉运动关联已经形成,视觉线索触发行为结果:没有视觉线索,右转;有视觉线索,左转。
更重要的是,机器人一旦学会了某条特定的路线(目标路径1),就能在任何其他给定的路线中(目标路径2)一次性地走到终点。
Krauhausen表示,「这种感知和运动的相互加强,在很大程度上也是自然界的运作方式,所以这也是我们试图在机器人中模仿的东西」。
经过训练,机器人学会了将导航线索与转向运动联系起来
其中,D中展示了导航线索(#1至#9),标记处代表左转,否则为右转。
在研究中,神经形态机器人所使用的是有机材料,不是硅基的哦。
这种聚合物「p(g2T-TT)」不仅稳定,而且能够保留大部分在迷宫中「学习」到的特定状态。
![]() 有机神经形态电路的布局
就像人脑中的神经元和突触能记住事件或行动一样,「p(g2T-TT)」能让学到的行为能一直保持下去。
这种在神经形态计算领域使用聚合物是由马克斯·普朗克聚合物研究所的Paschalis Gkoupidenis和TU/e的Yoeri van de Burgt开创的。
经过研究(可追溯到2015年和2017年),他们证明了这种材料可以在比无机材料大得多的传导范围内进行调整,而且它能够 「记住」或长时间存储所学的状态。
从那时起,有机设备就成为了基于硬件的人工神经网络领域的一个热门话题。
由于聚合物材料的有机性质,这些智能设备原则上可以与实际的神经细胞集成,也就是说可以广泛地应用于生物医学领域。
假设你在一次意外中失去了胳膊,那么基于智能聚合物的设备就能将你的身体与仿生的手臂联系起来。
那么,是不是在将来的某一天,神经形态机器人也能学会踢足球呢?
Krauhausen说,「原则上,这当然是可能的。但我们还有很长的路要走。我们的机器人仍然依赖一部分传统的软件来移动。而为了让神经形态机器人执行真正复杂的任务,我们需要建立神经形态网络,其中许多设备在一个网格中一起工作。这是我在博士研究的下一阶段要做的事情。」
有机神经形态电路的布局
就像人脑中的神经元和突触能记住事件或行动一样,「p(g2T-TT)」能让学到的行为能一直保持下去。
这种在神经形态计算领域使用聚合物是由马克斯·普朗克聚合物研究所的Paschalis Gkoupidenis和TU/e的Yoeri van de Burgt开创的。
经过研究(可追溯到2015年和2017年),他们证明了这种材料可以在比无机材料大得多的传导范围内进行调整,而且它能够 「记住」或长时间存储所学的状态。
从那时起,有机设备就成为了基于硬件的人工神经网络领域的一个热门话题。
由于聚合物材料的有机性质,这些智能设备原则上可以与实际的神经细胞集成,也就是说可以广泛地应用于生物医学领域。
假设你在一次意外中失去了胳膊,那么基于智能聚合物的设备就能将你的身体与仿生的手臂联系起来。
那么,是不是在将来的某一天,神经形态机器人也能学会踢足球呢?
Krauhausen说,「原则上,这当然是可能的。但我们还有很长的路要走。我们的机器人仍然依赖一部分传统的软件来移动。而为了让神经形态机器人执行真正复杂的任务,我们需要建立神经形态网络,其中许多设备在一个网格中一起工作。这是我在博士研究的下一阶段要做的事情。」
参考资料:
https://www.science.org/doi/10.1126/sciadv.abl5068
https://www.nature.com/articles/srep31746
![]()






 有机神经形态电路的布局
有机神经形态电路的布局