![]()
作者 | 蒋宝尚
编辑 | 青暮
近日,图灵奖得主John Hennessy 在CNCC 2020进行了特邀报告,在报告《第四代计算机体系结构的终结与新的前进道路 》中,他就第四代计算机体系结构的终结与新的前进道路展开论述。
具体而言,他回答了:“我们如何设计计算机来提高性能,特别是对于像机器学习这样计算要求很高的任务”等问题。另外,他还断言:
计算机架构第五时代必然是专用处理器的天下,而目前我们正处在第四时代到第五时代转换的节点上。
以下是报告全文,AI科技评论进行了不改变原意的整理。
大家好,我是John L. Hennessy,非常高兴参与CNCC2020会议,与大家讨论计算机架构这一话题。虽然很希望能够到现场和大家互动,但是线上交流似乎是目前最明智的选择。
在1977年,我还年轻,当时在斯坦福大学担任助理教授,从此开启了研究生涯,记得那时苹果公司还没有成立,微型处理器还是相对新颖的研究方向。
那时候,1980 年代早期,人们对更大型控制存储器中大型微程序使用的复杂指令集计算机(CISC)进行了一些研究。而我进行的是让我们重新思考如何设计计算机的研究方向:精简指令集计算机(RISC)。
由于这项工作具有颠覆性,我当时以为工业界很快就接受其想法。但事实上并没有,甚至,最初以我们的想法为基础的一些实验项目,被停掉了。因此,这让我明白了必须要成立一家公司证明这项技术、想法的可行性。于是,MIPS科技公司诞生了。
具体的时间点是:1984年,MIPS计算机公司成立。1992年,美国硅图公司收购了MIPS计算机公司。1998年,MIPS脱离美国硅图。
创办MIPS计算机公司是我首次进入硅谷所做出的事情,之后我就又回到了大学,再之后(1999年)我就和我的同事斯坦福大学的Teresa Meng博士共同创办了Atheros, 这家公司早在WiFi成为标准之前,就已经引领WiFi趋势。当然,这家公司最后也卖给了高通,我也回到斯坦福大学担任工程院院长。
另外,我还在斯坦福大学担任了16年的校长,并领导了奈特-汉尼斯学者奖学金项目,作为斯坦福大学全新的研究生奖学金项目,旨在培养下一代的全球领袖以解决世界面临的日益复杂的各种挑战。
在我担任校长期间,通过观察,发现无论是在政府、学界还是业界,其有强大的领导能力的人并没有多少,因此我们正在做出各种努力来培养“下一代领导人”。这个话题并不是今天的重点,今天的重点是讲技术,也就是摩尔定律带来的有趣转折点。
65年的计算机结构发展
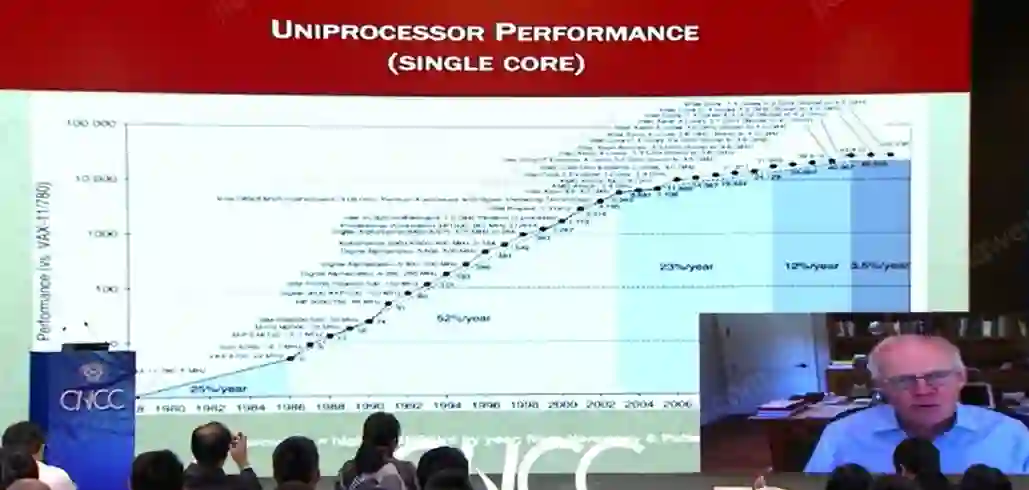
计算机架构已经走过了四个时代,在过去的65年期间取得了令人惊讶的进步,尤其是最近40年,微处理器的设计持续推陈出新,其处理性能每年提升1.4倍,与40年前相比计算机的运行速度已经提升了10^6倍。
1.架构越来越宽,从最初的8bit到16bit再到64bit。
2.指令级并行(ILP)在一段时间内是提高性能的主要架构方法。
3.出现多核技术,与单个内核相比,32 个内核的应用程序运行速度要快得多。
另外,在这期间,摩尔定律的出现预测了处理性能的提升:集成电路上可容纳的晶体管数目,约每隔18个月便会增加一倍,性能也将提升一倍。
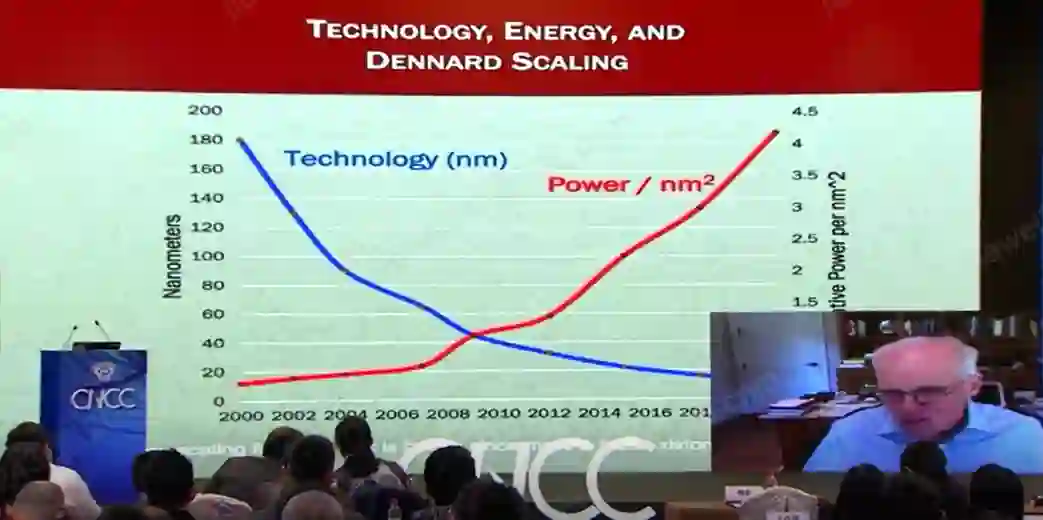
伴随摩尔定律是由罗伯特·登纳德(Robert Dennard)预测的登纳德缩放定律(Dennard scaling)。他指出,随着晶体管密度的增加,每个晶体管的能耗将降低,因此硅芯片上每平方毫米上的能耗几乎保持恒定。由于每平方毫米硅芯片的计算能力随着技术的迭代而不断增强,计算机将变得更加节能。
然后,让我们看看在过去的65年期间,计算机都发生了怎样的变化。从上图可知,计算机在不同的时代,其命名、技术以及特点各有不同。
在1955-1964,其使用的技术是晶体管,在这期间每一个模型都是不同的;随后进入了360时代,开始了小规模和中等规模的集成,使我们能够开发大型机器,甚至开发超级计算机。
微处理器出现之后,技术成本开始下降,在摩尔定律给出的预测下,微处理器变得越来越有能力。我们开始使用了大量的指令级并行性,兼顾效率的同时承担了其他风险。指令级并行大行其道之后,我们进入了第四个时代,重点在多核,即单芯片上存在多个单独的处理器,其性能再一次获得提升。
第四个时代即将结束,因为登纳德缩放定律和摩尔定律正在经历它的“没落王朝”,我们正站在第五个时代的门槛上,这个时代的重点以及趋势是专用处理器。
第五时代属于专用处理器
如上图所示,80年代中期至千禧年这段时间 ,计算机的性能每年能提高 52% 左右。
而在过去五~六年期间,每年只有3.5%性能提升。
更为具体一些,,自2012年以来,随着功率的增加,我们的芯片每纳米消耗的电力越来越多,这意味着增加了能源消耗,降低了效率。
因此,登纳德缩放定律的终结意味着工程师必须找到更加高效的利用方法。
能耗真的很重要,尤其是在过去的20年里,手机、IOT、大型的云服务的崛起,降低能耗已经成为重要成本花费。于是,我们看到处理器达到温度极限的现象,因此芯片过热而自动停止工作等设计也浮出水面,但即使设计非常巧妙,热量和电池仍然是限制因素。
我们必须改变架构设计,提高能耗的效率,在相同功率的情况下提高性能。其实,回顾历史,
计算机架构每一个时代的总结都伴随着能耗极限的到来
,例如2005年我们结束指令级并行,开始了多核的研究。
但是,在多核系统中,存在着某些规律的制约,意味着我们永远无法达到能源利用的上限。因此,通用处理器碰壁了。问题在于缓存变得越来越大,在性能博弈方面,得到的回报是递减的,而能耗却在继续扩大。
目前,以软件为中心的方法正在努力提高效率。我们使用脚本语言(如Java或Python)进行编程。它们属于解释性语言并且属于动态类型,因此在一定程度上具有重用性和灵活性。
这带来的缺点是:对于程序员来说是高效的,但是执行效率有待提高。
另一种思路是:以硬件为中心。其设计想法是设计针对特定问题和领域的架构(特定领域的体系结构(DSA))。这种特定领域的可编程处理器,通常是图灵完备的,效果拔群。但其缺点在于:只能执行少数任务。
而事实上,我们将两种方法结合:将特定领域的语言与旨在优化该语言执行的架构一起使用。
算力被锁死?顶层设计仍有希望
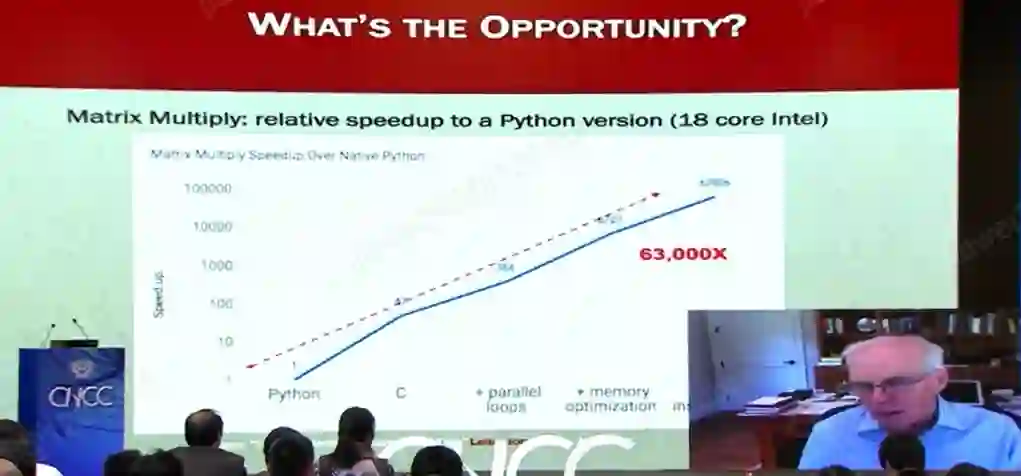
上图是MIT、英伟达、微软的研究者在《Science》上的文章,描述了性能提升软件方面的潜力。
具体而言,上图描述的是:Python 代码实现两个 4096×4096 的矩阵相乘的时候,代码在一台现代计算机上做该矩阵乘法需要 7 个小时,用 Java 实现的代码(Version 2)速度可以提高到原来的 10.8 倍,用 C 语言(Version 3)又可以提升到 Java 的 4.4 倍,运行时间比最初的 Python 版本快 47 倍。这种性能的提升来源于程序运行时操作数量的减少。
此外,根据硬件的特点来调整矩阵乘法的代码甚至可以让运行速度提升 1300 倍。最终,代码优化的方法可以把这项任务所需的时间减少到 0.41 秒,这跟需要 7 个小时运行的 Python 相比速度提升了 6 万倍。
诚然,这是一个相对容易优化的简单例子,但是我觉得这里面显示了一些机会。
对于特定领域的架构,根据领域的特点来定制架构,从而达到更高的效率。
这并不只是针对一个应用,而是针对一整个领域的应用。值得一提的是,这些特定领域的架构虽然可以进行一系列密切相关的应用。但与通用处理器相比,它们需要更多的特定领域知识。
因此,你只有以更加深层次的方式了解应用,才能获得一些性能的提升。
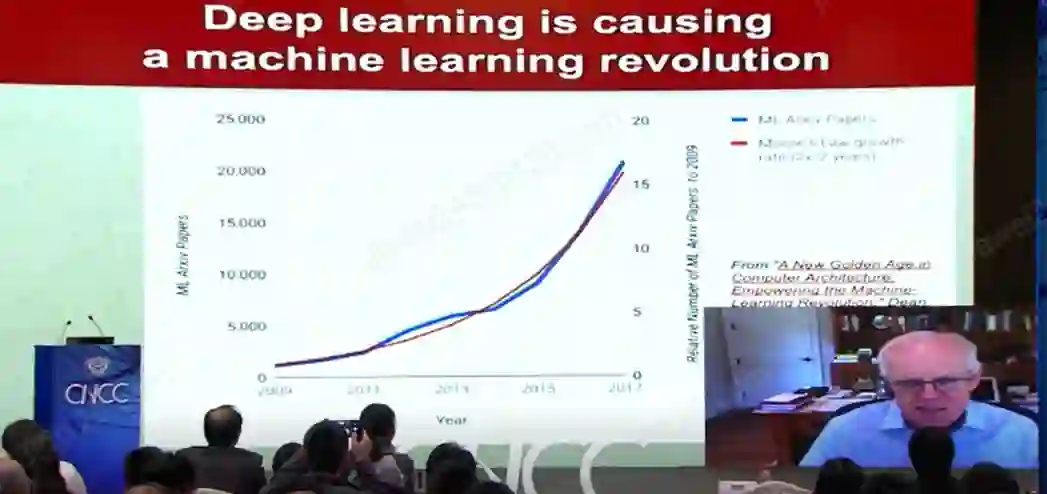
深度学习其所针对的神经网络处理器就是非常好的例子,我们可以看到GPU已经彻底改变了图形计算的性能。
GPU只是冰山一角,对特定领域进行定制处理器的需求巨大,当前在机器学习社区,更多人的研究方向是如何用机器学习处理数据,而不是编写大量代码尝试生成有趣应用程序的新方法。目前,机器学习发表论文的增速已经和摩尔定律一样快了。
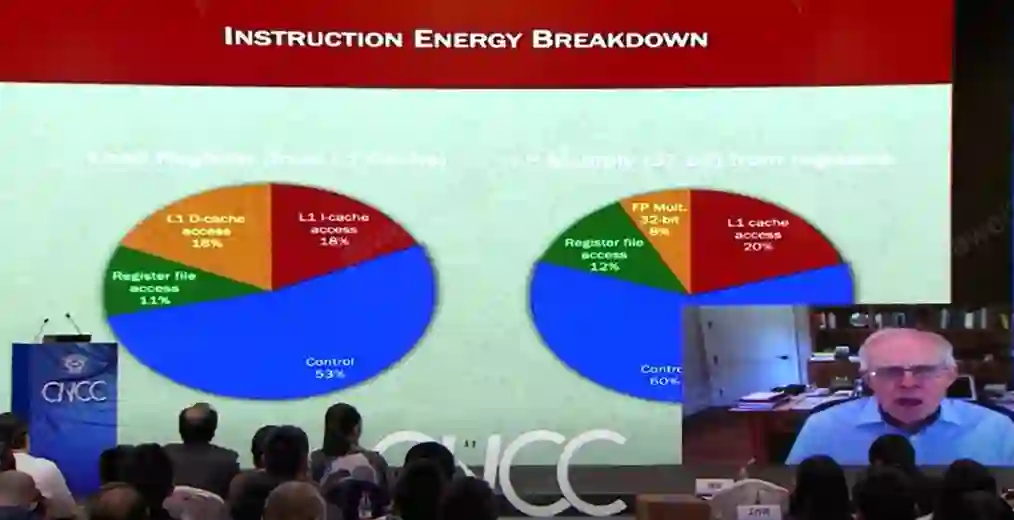
我对专用处理器的兴趣非常浓厚,我认为它正在引领着一场革命。那么,我们应该从什么角度观察它带来的机会呢?如上图所示,其展示的是,当我加载一段简单的指令,能量的消耗在各部分所占比例。
显然,控制占大头,缓存所占比例也不少,这两部分大概能消耗60%~80%的能量。
如果能改善这种情况,我们处理器的性能将会上一个台阶。面对这种情况,针对特定领域的专用处理器比通用处理器更能“打”,它带来的好处是:
1.它能够在特定领域使用更简单的并行性(较少控制硬件);2.也能够更有效地使用内存带宽;3.还能够消除不需要的精度。
第一种好处是从多指令、多数据类型的体系结构出发。其实,这暗符多核的意义。
第二种好处指的是其能够进行用户控制的存储,而不是缓存。虽然缓存能够满足灵活性的要求,但是其付出的代价也是巨大的。
第三种好处是,适用于通用任务的 CPU 通常支持 32 和 64 位整型数和浮点数数据。对于很多机器学习和图像应用来说,这种准确率有点浪费了。例如在深度神经网络中,推理通常使用 4、8 或 16 位整型数,从而提高数据和计算吞吐量。同样,对于 DNN 训练程序,浮点数很有意义,但 32 位就够了,16 为经常也能用。
来看一个比较简单的例子,上图展示了谷歌TPU-1的布局:TPU 的结构与通用处理器完全不同。它的主计算单元是矩阵乘法,即每个时钟周期提供提供 256×256 乘加运算的脉动阵列(systolic array)。
TPU 还结合了 8-bit 精度、高效脉动架构(systolic structure)和 SIMD 控制特性,这意味着每个时钟周期所能执行的乘加(multiply-accumulates)数是一般通用单核 CPU 的 100 倍。
TPU 使用 24MB 的本地内存以代替高速缓存,大约是 2015 年相同功耗 CPU 的两倍。最后,激活值内存和权重内存(包括储存权重的 FIFO 结构)可以通过用户控制的高带宽内存通道连接。
使用谷歌数据中心常见的 6 个推断问题的加权算术均值作为度量,TPU 比一般 CPU 要快 29 倍。因为 TPU 要求的能源少了一半,它的能源效率在这样的工作负载中是一般 CPU 的 80 倍。
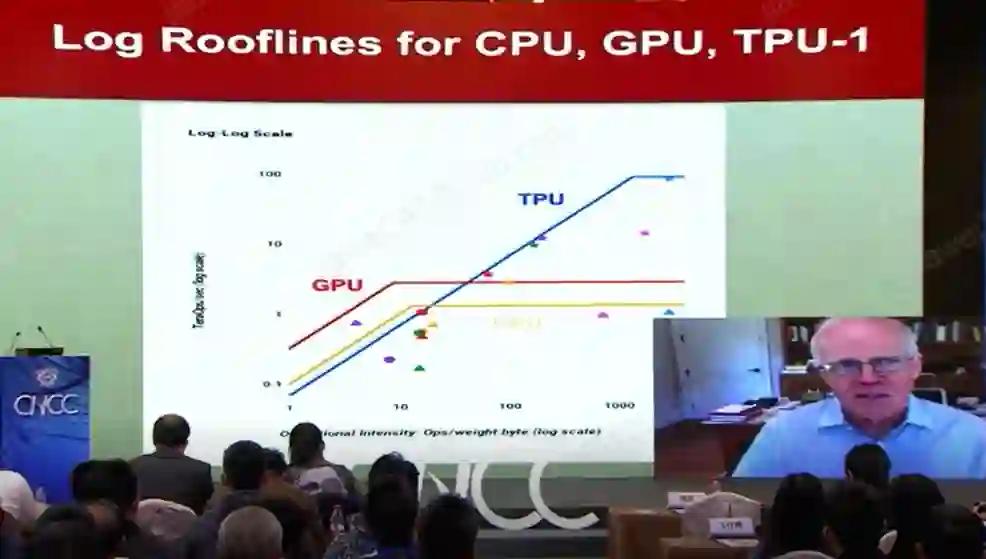
它们之间的性能是如何转化的呢?如上图所示,通过对CPU、GPU和TPU的Log Rooflines进行对比,其能够给我们一个直观的感受:如果让应用程序在上图的区间中运行,那么就可以获得比GPU或CPU更高的性能。
另外,用GPU的场景,往往是计算强度较低的需求,这些需求与内存相关。使用TPU的场景是计算大量矩阵,而不用移动那么多的数据。CPU的那条线更加平缓,因为它在内存、宽带、通用之间做出了权衡。
未来路在何方?
观察上述现象,这对我们的未来有何启示?启示是:我们正在步入一个新的时代,这个时代对于那些思考用新方法来构建硬件和软件的公司来说充满机遇。
值得一提的是,特定于领域的体系结构和特定领域的编程语言设计还处于初级阶段,它只有不到五年的“历史”,我们有很多机会重新思考未来的设计和前进方向。
DSAs和DSLs刚看到苗头,还有很多的悬而未决的问题。我们如何处理稀疏数据?比如机器学习、深度学习等大量稀疏数据、稀疏状态在传统上很难有效处理。
难题往往意味着机会,因此我我们要思考如何获得特定于领域的体系结构,如何才能使硬件开发变得更简单、更容易。
当前的一个方向是:让硬件开发更像软件,即开发原型、重用、抽象的架构;开放式硬件堆栈(ISA到IP库)等等。
在硅片方向,仍然可以考虑如何扩展登纳德缩放定律和摩尔定律。另外,在硅之外,碳纳米管、量子计算等也是研究方向,但这些仍然处在基础研究阶段。
总结一下:旧的东西总能变成新的。软件架构师Dave Kuck曾经说过:“真正让我沮丧的是使用 ILLIAC IV,给机器编程非常困难,架构可能不太适合我们试图运行的一些应用程序。
关键的想法是,我认为在ILLIAC IV中,应用程序和体系结构之间没有很好的匹配。
编者注:ILLIAC IV是首批超级计算机之一,服务近十年之后,于1981年9月7日停用。
因此,可以断言,不理解软件就开始构架硬件的架构师注定会失败,我们必须重新思考软禁、硬件堆栈以及跨越边界的权衡是什么。
如果我们能做到这一点,我们将迎来辉煌的第五个时代,在这个时代充满着提高性能的机会。
AI科技评论联合【机械工业出版社华章公司】为大家带来15本“新版蜥蜴书”正版新书。
在10月24号头条文章《1024快乐!最受欢迎的AI好书《蜥蜴书第2版》送给大家!》留言区留言,谈一谈你对本书内容相关的看法和期待,或你对机器学习/深度学习的理解。
AI 科技评论将会在留言区选出 15名读者,每人送出《机器学习实战:基于Scikit-Learn、Keras和TensorFlow(原书第2版)》一本(在其他公号已获赠本书者重复参加无效)。
活动规则:
1. 在留言区留言,留言点赞最高的前 15 位读者将获得赠书。获得赠书的读者请联系 AI 科技评论客服(aitechreview)。
2. 留言内容会有筛选,例如“选我上去”等内容将不会被筛选,亦不会中奖。
3. 本活动时间为2020年10月24日 - 2020年10月31日(23:00),活动推送内仅允许中奖一次。
![]()
点击阅读原文,直达NeurIPS小组~