帝国理工联手谷歌提出抽象文本摘要最佳模型 | ICML 2020


论文代码:https://github.com/google-research/pegasus
导语
前言
各种 Transformer 模型与自监督预训练技术(如 BERT、GPT-2、 RoBERTa、XLNet、ALBERT、T5、ELECTRA)相结合,已被证明是学习生成通用语言的强大框架。之前的工作中,预训练使用的自监督目标对下游应用有一定程度的不可知性,即不考虑下游任务,如此有利于模型通用性的学习。本文认为如果预训练的自监督目标更接近最终的任务,那么最终的下游任务能取得更好的结果。
实验证明,将输入文档中部分句子遮蔽掉,用剩余的句子生成被遮蔽掉句子的这种预训练目标很适用于文本摘要任务。这种预训练目标确实适合于抽象摘要,因为它非常类似于下游任务,从而促进模型对整个文档的理解和类似摘要的生成。需要指出的是,选择重要句子比随机选择或者选择前几句的结果性能都要好。
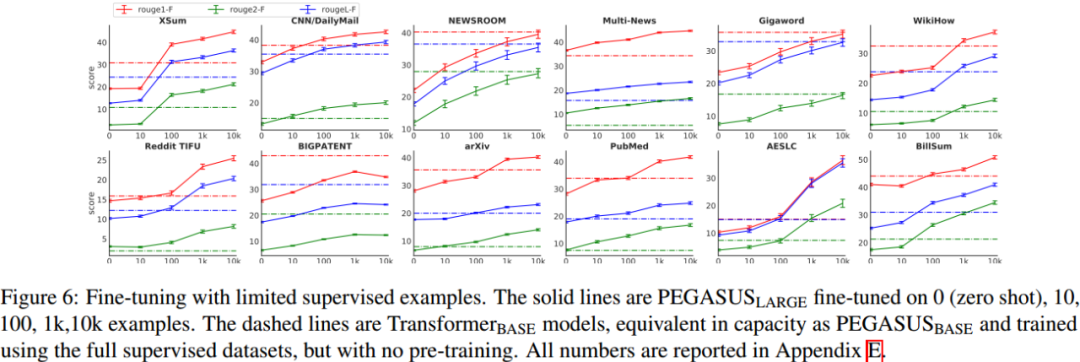
在 C4 语料上预训练出的最好 PEGASUS 模型,参数只有 568M,但在 12 个评测数据集上评测能够比肩此前最优结果,甚至超越它们刷新纪录。另外,本文为进一步提升最先进结果,引入了一个新收集的文本语料库,该语料库由新闻类文章组成包括 XSum 和 CNN/DailyMail 摘要数据集,统称为 HugeNews。此外,将本文的模型应用了低资源文本摘要任务上时,实验结果表明本文的模型能够非常快速适用于少量监督对的微调,并仅以 1000 个样本即在 6 个数据集中斩获桂冠。最后,还将文本模型的结果与人工摘要结果做对比,结果表明本文的模型可以达到与人工摘要相媲美的效果。
总结下本文的贡献:
(3)对于低资源任务数据集,通过微调 PEGASUS 模型,可以在广泛的领域实现良好的抽象摘要效果。在多个任务上,仅需 1000 个样本就超过了以前的最先进的结果。
(4)对模型结果进行人工评估,结果表明在 XSum, CNN/DailyMail 和 Reddit TIFU 上的摘要效果与人工摘要比肩。
模型
本文假设预训练自监督的目标越接近最终的任务则结果性能越好。在 PEGASUS 预训练中,将文件里的几个完整句子删除,而模型的目标就是要恢复这些句子,换句话说,用来预训练的输入是有缺失部分句子的文档,而输出则是缺失句子的串连。这是一项难以置信的艰巨任务,甚至对人人类来说也是不可能的,我们并不期望模型能完美地解决它。然而,这样一个具有挑战性的任务促使模型学习到关于语言的知识和这个世界的一般事实,以及如何从整个文档中提取信息,以便生成类似于微调摘要任务的输出。这种自监督的优点是,可以创建与文档一样多的示例,而不需要任何人工注释,而这通常是纯监督系统的阿喀琉斯之踵。
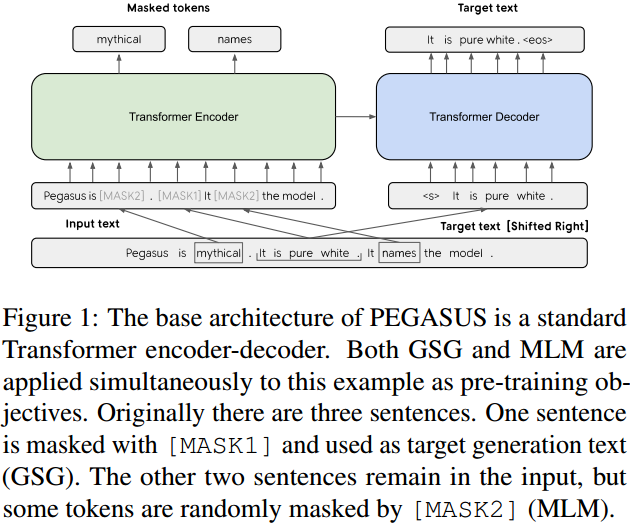

预训练的语料具体如下:
(2)HugeNews,这是本文新引入的
下游任务具体如下:
实验结果
PEGASUS_{large}版:
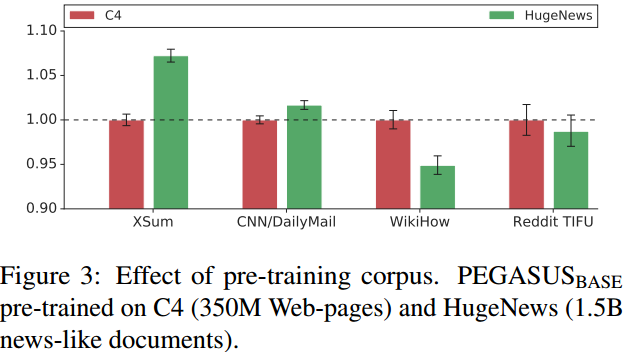
预训练语料的影响如 Figure 3 所示:
预训练目标的影响如 Figure 4 所示:
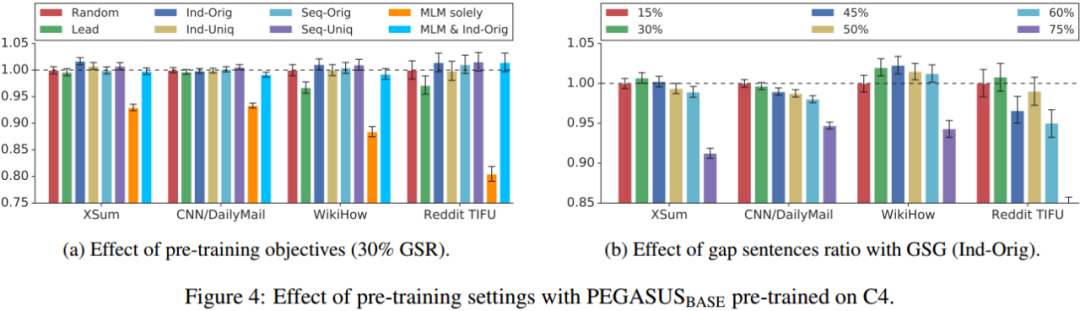
Figure 5 展示了词典大小的影响:
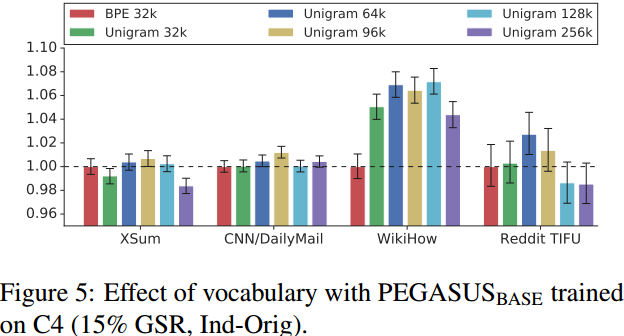
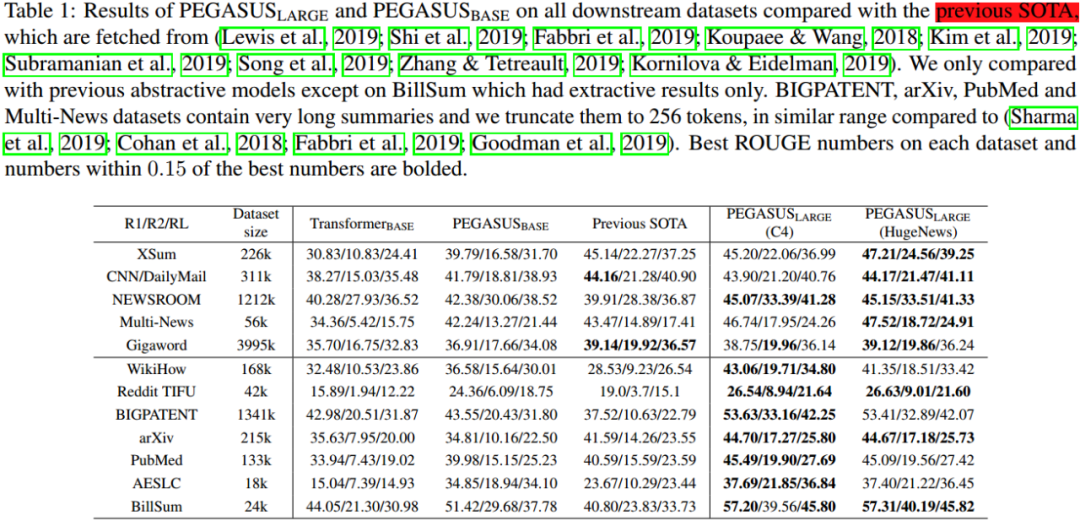
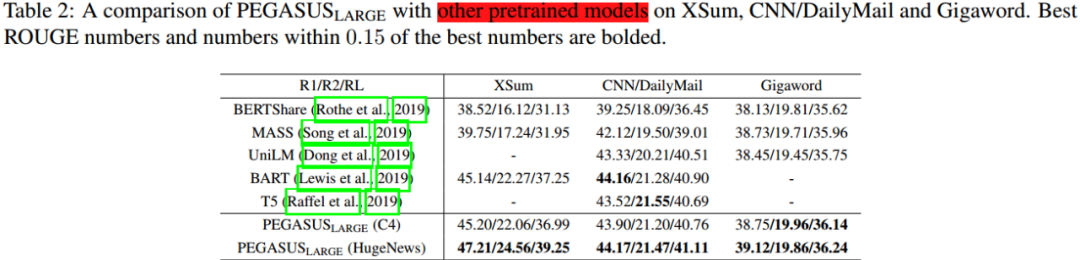
Table 1和 Table 2展示了 PEGASUS_{BASE} 和 PEGASUS_{LARGE}在下游任务上的表现。PEGASUS_{BASE}在多项任务上超过当前最优结果,PEGASUS_{LARGE} 则在全部下游任务超越当下最优结果。
4、人工评测

总结

ACL 2020原定于2020年7月5日至10日在美国华盛顿西雅图举行,因新冠肺炎疫情改为线上会议。为促进学术交流,方便国内师生提早了解自然语言处理(NLP)前沿研究,AI 科技评论将推出「ACL 实验室系列论文解读」内容,同时欢迎更多实验室参与分享,敬请期待!
![]()
点击"阅读原文",直达“ACL 交流小组”了解更多会议信息。

登录查看更多
相关内容
专知会员服务
43+阅读 · 2020年1月28日
Arxiv
17+阅读 · 2020年6月2日
Arxiv
15+阅读 · 2020年2月28日

相关VIP内容
专知会员服务
43+阅读 · 2020年1月28日
相关资讯
相关论文
Arxiv
17+阅读 · 2020年6月2日
Arxiv
15+阅读 · 2020年2月28日