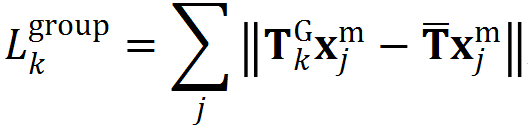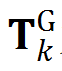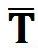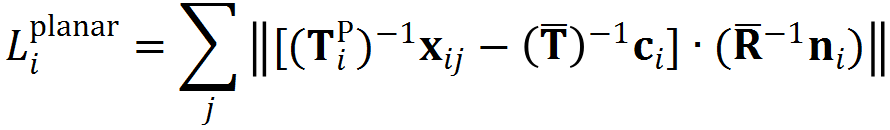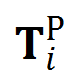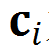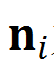物体6D姿态估计是机器人抓取、虚拟现实等任务中的核心研究问题。近些年来,随着深度学习技术和图像卷积神经网络的快速发展,在提取物体的几何特征方面出现了许多需要改善的问题。国防科技大学的研究人员致力于通过将几何稳定性概念引入物体 6D 姿态估计的方法来解决问题。
物体 6D 姿态估计的目的是确定物体从模型坐标系到相机坐标系的刚性变换矩阵。现有方法通常通过求解观测物体与物体三维模板模型的对应关系或使用深度神经网络回归的方法计算物体位姿。得益于图像卷积神经网络的发展,现有位姿估计方法大多依赖于对物体图像特征的提取,而忽略了物体的几何特征。当处理无纹理物体或者物体的纹理特征不够显著时,问题图像特征的提取往往非常困难,这也导致基于 RGB 特征的方法不能够处理无纹理、弱纹理物体的位姿估计问题。值得注意的是,在人类对三维物体的感知过程中,通常优先关注物体的几何形状。例如,在抓握物体时,人类往往只关注物体的形状,而忽略物体的纹理和颜色。使用物体的几何形状特征实现物体位姿估计,有望减少或消除物体纹理带来的影响,提升对无纹理物体的位姿估计算法性能。
近些年来,随着深度传感技术的快速发展,以 PPF 特征匹配算法为代表非学习方法和以 3DMatch 为代表的深度学习几何特征提取方法逐渐在位姿估计问题中崭露头角。这些方法虽然在多个公开数据集中取得了不错的效果,但是没有显式地约束几何特征提取和物体位姿的关系,因此制约了方法的可解释性和泛化性。
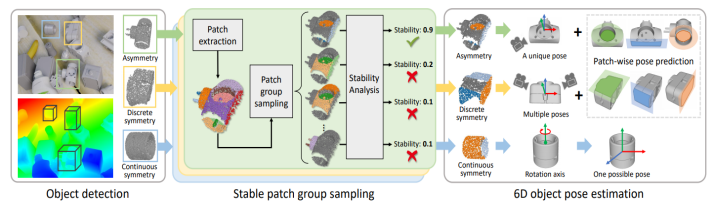
针对这一问题,国防科技大学的研究人员将几何稳定性概念引入了物体 6D 姿态估计,并提出了利用物体表面几何稳定(Geometrically stable)的面片组合(Patch group)预测物体姿态的方法 StablePose。StablePose 物体位姿估计模块的输入只有物体的深度信息,不包括 RGB 图像,能够有效处理无纹理、弱纹理物体的位姿估计问题。实验表明,StablePose 在多个实例位姿估计和类别位姿估计数据集上取得了最佳性能,能够处理物体间遮挡,具有良好的泛化性。论文的主要创新点包括:
![]()
论文地址: https://arxiv.org/abs/2102.09334
在现有工作中,几何稳定性分析主要被用于三维物体分割和三维点云配准。在三维点云配准任务中,几何稳定性分析旨在选择具有代表性的点云子集,这个子集可被用于实现快速、稳定的 ICP(Iterative closest point)点云配准。受到该思想的启发,StablePose 将几何稳定性引入物体 6D 位姿估计任务,其核心是提取物体表面几何稳定的面片组合。
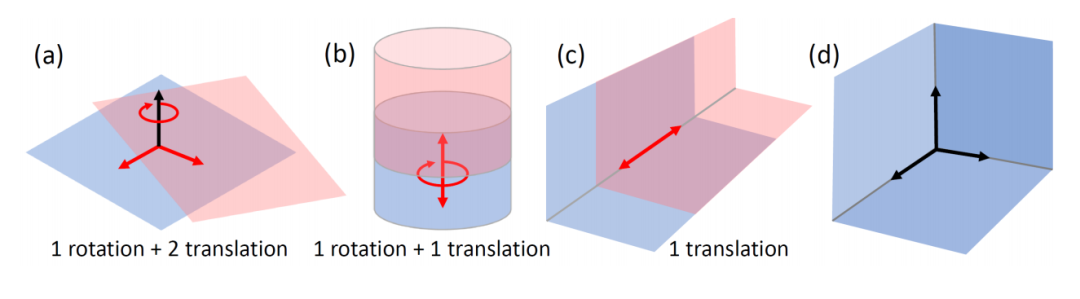
几何稳定的面片组合是能够确定全部六个自由度物体位姿的面片集合,通常由三个以上面片构成。StablePose 位姿估计问题中的面片通过对观测点云数据平面和圆柱提取得到。根据几何稳定性分析理论,三个及三个以上满足一定空间关系的平面或圆柱面片能够确定物体位姿的全部六个自由度,因此在几何上是稳定的。
![]()
如图所示,(d)中由三个互相垂直的平面组合能够确定物体位姿的全部六个自由度,构成几何稳定的面片组合,而(a)、(b)、(c)中的平面组合能够在某些自由度上滑动,在几何上不稳定,不能构成几何稳定的面片组合。利用几何稳定的面片组合进行物体姿态估计的目的非常直观:首先,面片是介于单个空间点和完整物体之间的几何模型,既包括局部几何特征,也包括全局语义特征,具有很好的表达能力;其次,几何稳定的面片组合在包括用于确定物体位姿全部自由度有效信息的同时,也去除了次要信息的影响,构成了对三维模型的精简表示。这样做不仅能够实现网络的快速训练,也能够提高方法的抗遮挡能力。为了估计物体的位姿,除了确定几何稳定的面片组合,还需计算观测面片与三维模型面片之间的对应关系。StablePose 使用深度网络学习这一对应关系并估计物体位姿。
![]()
StablePose 的计算流程如图所示。给定单视图 RGB-D 图像,StablePose 首先检测和分割其中的物体,然后使用相机内参得到目标物体的三维点云模型。使用 CAPE 算法对物体点云进行过分割处理,提取平面和圆柱面片。接着从平面和圆柱面片中筛选得到一系列几何稳定的面片组合。
![]()
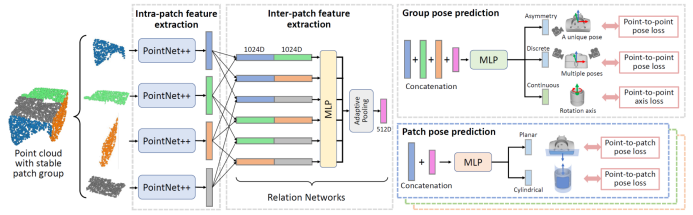
如 StablePose 网络结构图所示,对于每个几何稳定面片组合,使用三维卷积神经网络提取特征并进行位姿估计。StablePose 使用的三维卷积神经网络以 PointNet++ 作为 backbone 提取面片的特征,并采用 Relation networks 进一步提取面片组合的全局特征。网络预测模块分成两个子任务:
Group pose prediction:将各面片特征和面片组合全局特征进行拼接,预测物体的位姿,损失函数(Point-to-point pose loss)约束物体位姿的全部自由度,具体形式为: ![]() ,其中,
,其中,![]() 为预测位姿,
为预测位姿,![]() 为位姿真值,
为位姿真值,![]() 为物体三维模型表面采样点;
为物体三维模型表面采样点;
Patch pose prediction:将每一个面片特征分别单独与面片组合全局特征进行拼接,预测物体的位姿,损失函数(Point-to-patch pose loss)只约束物体位姿的部分自由度。以平面面片为例,其损失函数为:![]() ,其中,
,其中,![]() 为预测位姿,
为预测位姿,![]() 为位姿真值,
为位姿真值,![]() 为面片中心点,
为面片中心点,![]() 为面片法向量。
为面片法向量。
该损失函数的含义是:不要求物体位姿的全部6个自由度都被预测正确,只要求当前面片分别按照预测位姿矩阵变换与位姿矩阵真值变换后的两个面片“共面”。
在上述方法中,子任务 2 是子任务 1 的辅助任务,可以提升网络的收敛速度和方法性能。此外,针对解决反射和旋转对称物体位姿不唯一的问题,StablePose 采用三类不同的损失函数分别对无对称物体、反射对称物体和旋转对称物体进行优化。这样做可以解决物体对称性带来的最优解不唯一的问题。
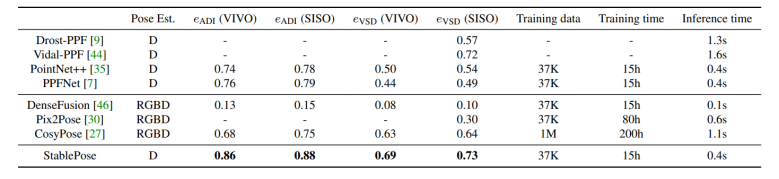
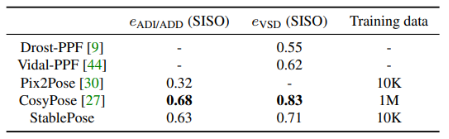
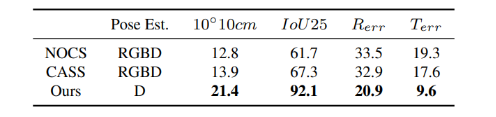
为了验证 StablePose 的性能,文章分别在两个实例级位姿估计数据集 T-LESS、LineMod-O 和两个类别级位姿估计数据集 NOCS-REAL275、ShapeNetPose 上进行测试。实验结果表明,在无纹理数据集 T-LESS 上,StablePose 不仅达到了最佳性能,而且使用的训练数据量较之前 SOTA 方法更少,训练时间更短,推理时间更快。在遮挡较为严重的 LineMod-O 数据集上,相比于现有算法,StablePose 在使用最少量训练数据的情况下取得了次佳性能。,StablePose 不仅能在实例级的数据集上表现优异,也能够实现跨实例的位姿预测,StablePose 在 NOCS-REAL275 和作者提出的大型合成数据集 ShapeNetPose 上获得最佳性能,这得益于几何稳定面片组合带来的方法泛化性能的提升。
![]()
![]()
![]()
![]()
基于 RGB 的物体位姿估计最常见的解决方案是从 RGB 图像检测并匹配关键点并求解 PnP。近些年来,这种方法已经被大量工作研究,并取得了较好的效果。但是当处理无纹理、弱纹理物体时,物体表面关键点难以被检测和匹配,因此性能较差。
基于物体几何形状的位姿估计方法大体包括以下几种:利用物体点云信息,使用 ICP 算法对初始估计位姿进行优化;将深度图或点云作为位姿估计深度网络的额外输入通道,将几何形状特征与颜色问题特征融合共同估计位姿;直接从深度图、点云或者体素提取几何形状特征,通过关键点匹配、投票算法或者使用深度网络估计位姿。
几何稳定性分析也被称作滑移性分析,是分析物体形状的经典工具。几何稳定性分析可被用于从一个点集中提取子集,以提高 ICP 算法的稳定性和有效性。这是通过过滤掉多余的点,同时为每个对齐自由度保留足够的点实现的。几何稳定性分析的另一个应用是从物体表面提取可滑动部件,以实现物体分割和物体特征提取。
建新·见智 —— 2021亚马逊云科技 AI 在线大会
4月22日 14:00 - 18:00
大会包括主题演讲和六大分会场。内容涵盖亚马逊机器学习实践揭秘、人工智能赋能企业数字化转型、大规模机器学习实现之道、AI 服务助力互联网快速创新、开源开放与前沿趋势、合作共赢的智能生态等诸多话题。
亚马逊云科技技术专家以及各个行业合作伙伴将现身说法,讲解 AI/ML 在实现组织高效运行过程中的巨大作用。每个热爱技术创新的 AI/ML 的爱好者及实践者都不容错过。
识别二维码或点击阅读原文,免费报名看直播。
![]()
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:content@jiqizhixin.com