当CV碰上无人机:ICCV 2019 VisDrone挑战赛冠军解决方案解读
机器之心发布
作者:罗志鹏
近日,在 ICCV 2019 Workshop 举办的 Vision Meets Drone: A Challenge(简称:VisDrone2019) 挑战赛公布了最终结果,来自深兰科技北京 AI 研发中心的 DeepBlueAI 团队斩获了「视频目标检测」和「多目标追踪」两项冠军。我们可以通过这篇文章来了解一下 DeepBlueAI 团队的解决方案。

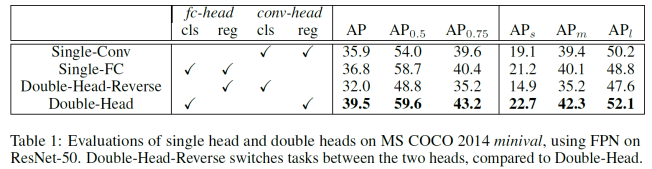
任务 1:图像中的目标检测。任务旨在从无人机拍摄的单个图像中检测预定义类别的对象(例如,汽车和行人);
任务 2:视频中的目标检测。该任务与任务 1 相似,不同之处在于需要从视频中检测对象;
任务 3:单目标跟踪挑战。任务旨在估计后续视频帧中第一个帧中指示的目标状态;
任务 4:多目标跟踪挑战。该任务旨在恢复每个视频帧中对象的轨迹。
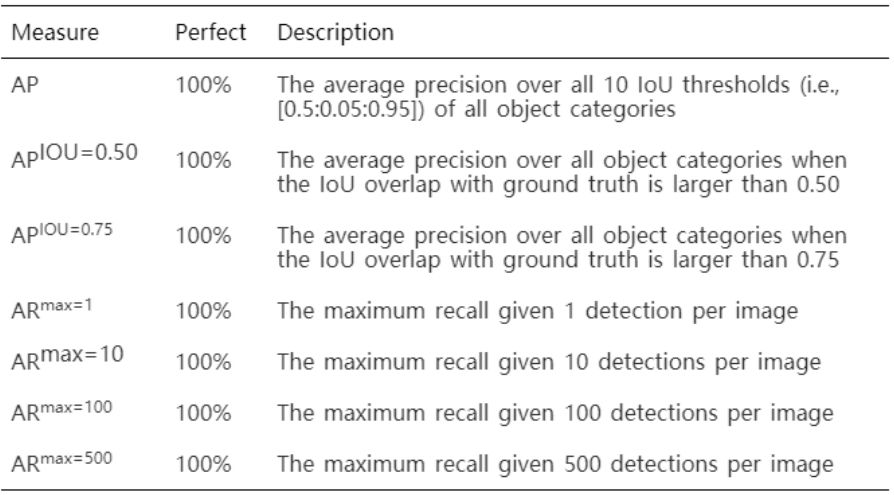

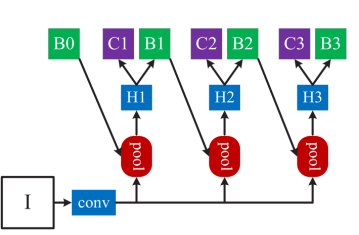
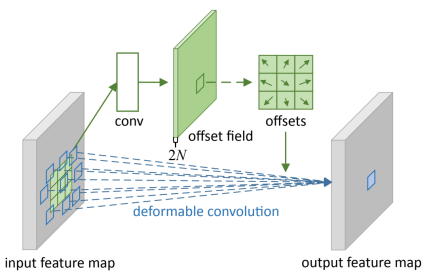
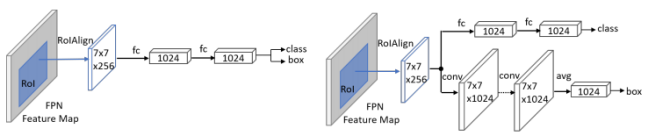
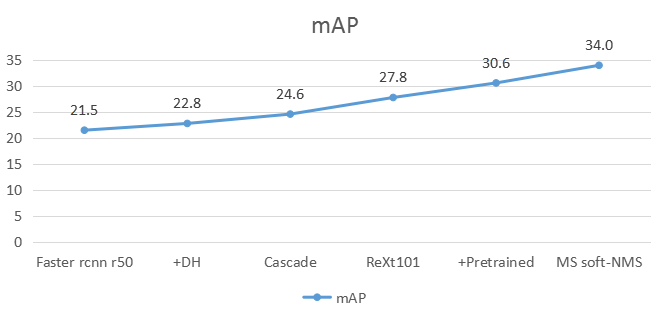

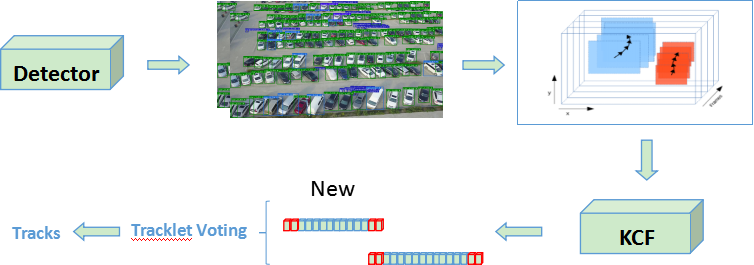
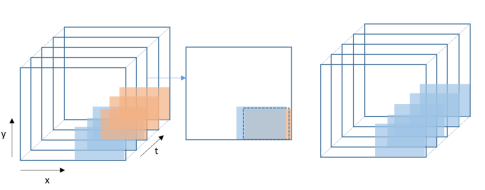
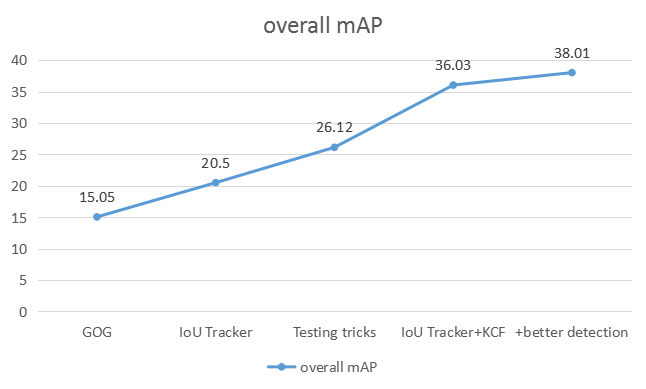
使用不需要图片信息,仅根据检测结果的相邻帧的 iou 进行计算;
iou-tracker 对检测结果有着较高的要求,我们对自己的检测结果有信心;
运行速度极快,不涉及到神经网络,节省时间和 GPU 资源。
登录查看更多
相关内容

Arxiv
10+阅读 · 2018年5月16日
Arxiv
3+阅读 · 2018年3月26日




相关VIP内容
相关资讯
相关论文
Arxiv
10+阅读 · 2018年5月16日
Arxiv
3+阅读 · 2018年3月26日