谷歌开源Embedding可视化工具

作者信息
Elesdspline
目前从事NLP与知识图谱相关工作。
谷歌开源Embedding可视化工具
导读
目前,在深度学习中可以利用多种方法或工具将特征信息转换为低维稠密的向量表示(Embedding),且Embedding在自然语言处理、知识图谱、推荐搜索、机器翻译、智能问答等领域应用广泛。Embedding 中虽然包含了丰富的信息表达,但是肉眼看上去是数不胜数的数字,无法看出其内在的信息关联,因此,将Embedding的信息可视化到肉眼可见的空间是非常重要的工作。
本文主要介绍谷歌2016年开源的一款 Embedding 可视化工具及其使用方法,这款工具是一款用于交互式可视化和高维数据分析的网页工具 Embedding Projector。
一、可视化工具介绍
Embedding Projector 是一款用于交互式可视化和高维数据分析的可视化工具,它是 TensorFlow 的一部分,但是谷歌开放了一个可以单独使用的版本,无需安装和运行 TensorFlow 便可以对 Embedding 进行可视化。
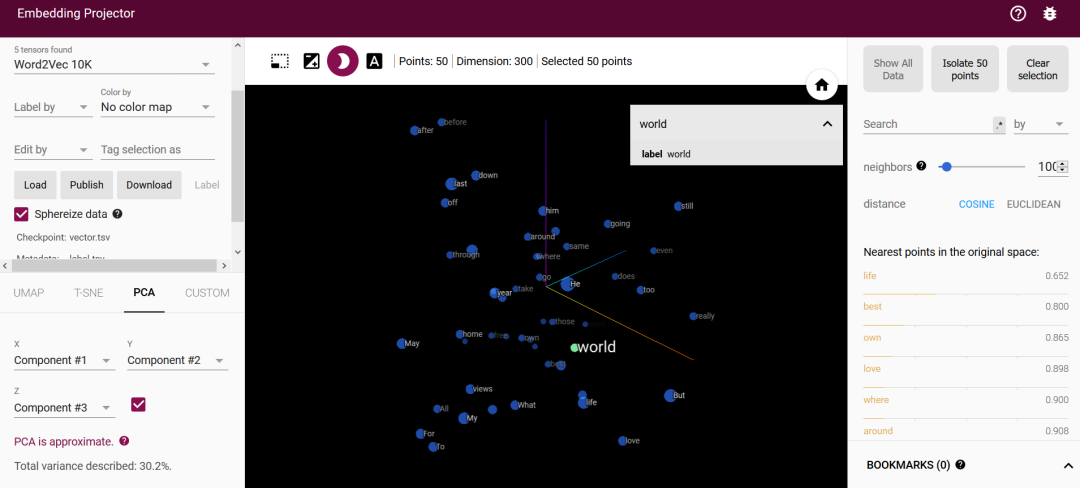
下图是 Embedding Projector 的页面,是不是有点酷炫的feel,分为左中右三部分:
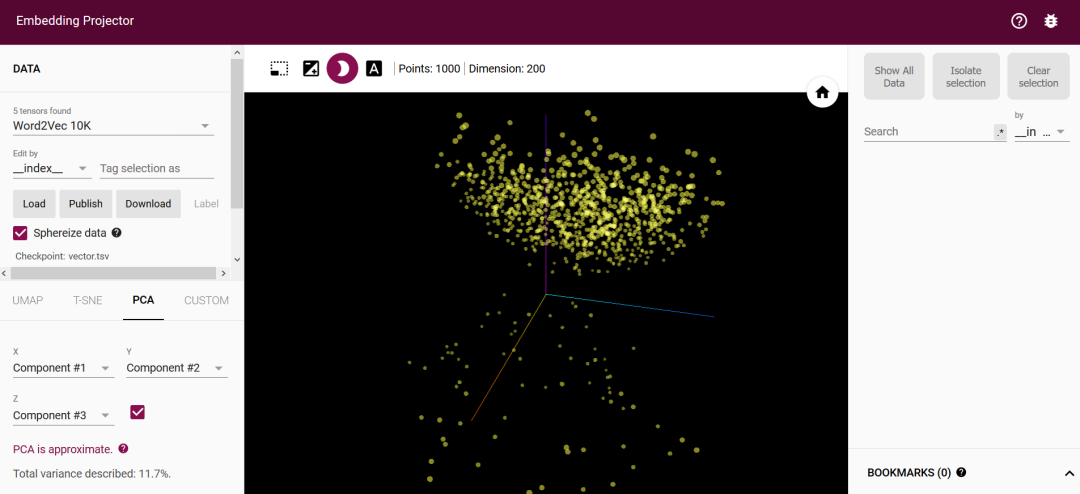
-
中间部分为可视化部分,可以3D显示立体空间,以及一些工具栏。 -
左侧是一些高维数据的降维方法以及可以Embedding的文件,高维数据降维的方法包括UMAP、T-SNE、PCA、CUSTOM,工具提供了5种可尝试的Embedding,包括 Word2Vce All、Mnist with images、Word2Vec 10k、GNMT Interlingua、Iris,另外可以上传自己的 Embedding 文件,一会详细说明怎么使用。 -
右侧是词的一些空间邻近词,有不同的计算方法得到的,包括 COSINE、EUCLIDEAN。
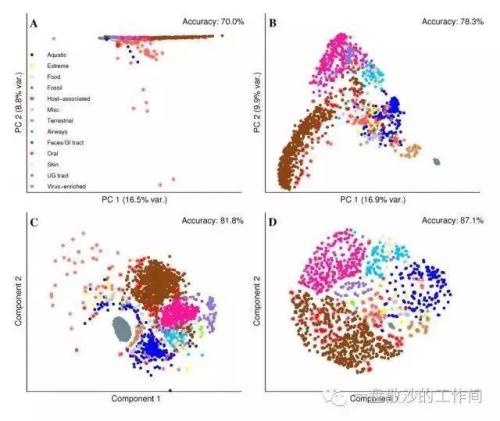
看一下PCA降维生成的酷炫图:
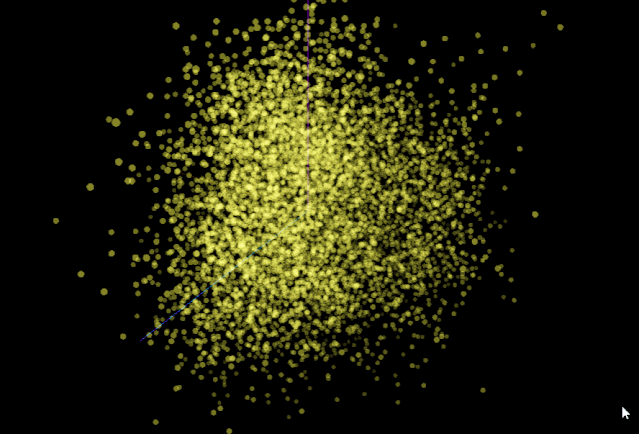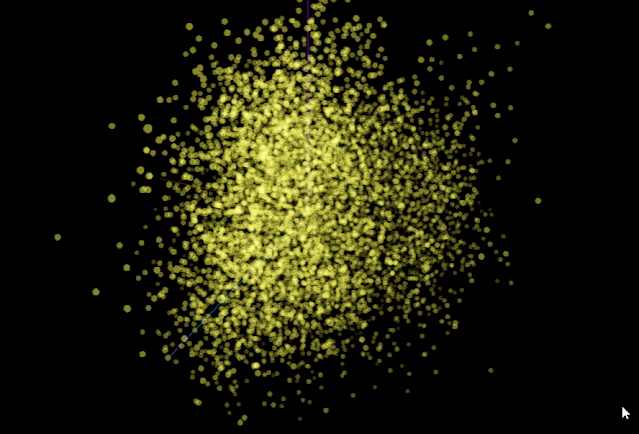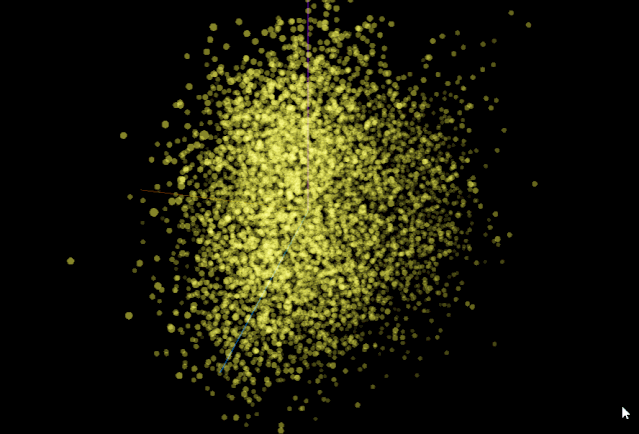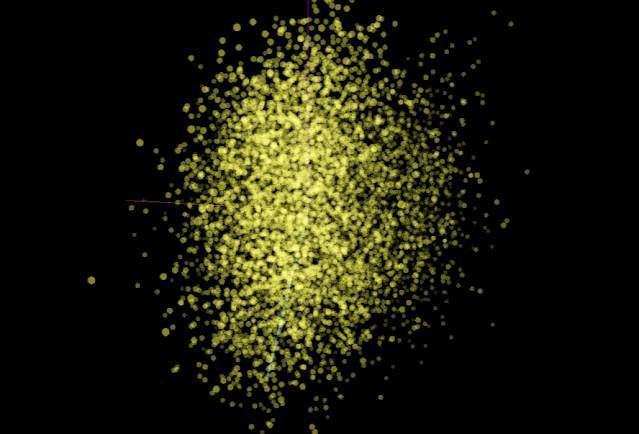
简述几种降维方法
-
PCA 可以探索 Embedding 的内在信息空间结构,探索不同的信息维度。 -
T-SNE 可用于探索局部近邻值(local neighborhoods)和聚类(cluster),比如相近的词语聚类到一起,或者图谱知识表示中的关系向量,正向与反向的关系向量聚成两个簇。 -
UMAP(Uniform Manifold Approximation and Projection) 是加拿大研究员18年提出的一种方法,是一种类似 T-SNE 的高维数据降维算法,UMAP 相对于 T-SNE 能反映全局结构且在计算大样本数据时,运行速度快,占用内存少。 -
CUSTOM 是自定义线性投影,可以帮助发现数据集中有意义的方向(direction),比如图谱中正向关系与反向关系、情感中喜欢与厌恶等。
可视化地址 :http://projector.tensorflow.org/
二、如何使用自己的文件
Embedding Projector 除了提供的5中尝试的文件,还可以使用自己的 Embedding 文件,但是需要转换成工具需要的 tsv 格式文件,下图是上传文件的步骤,点击 load 会出现右边的框,第一个文件是只有向量的文件,第二个 label 文件。
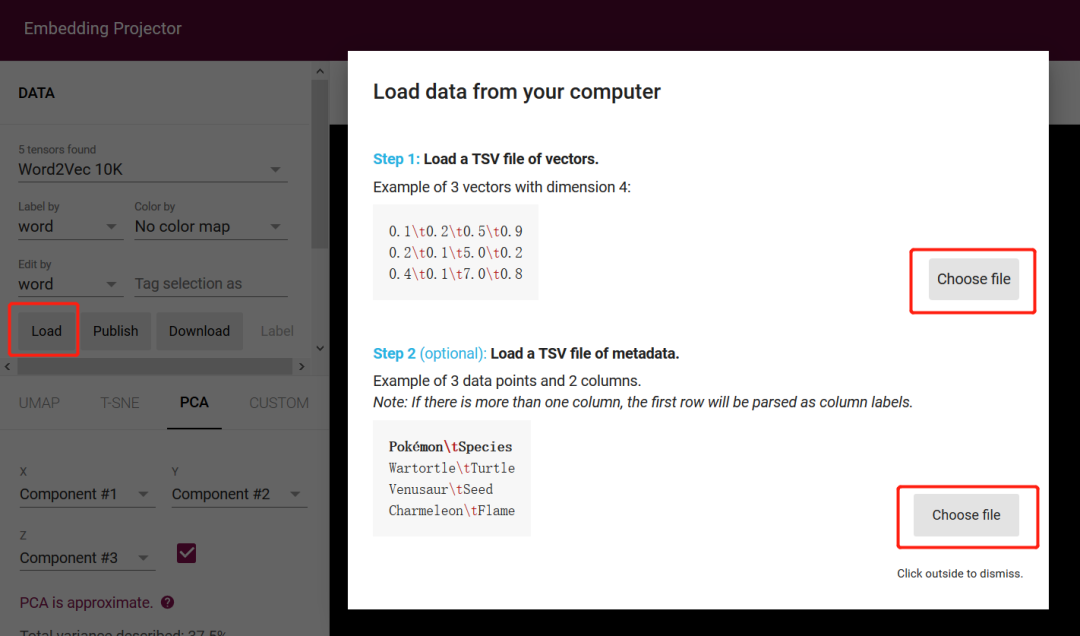
如何根据我们的 Embedding 文件获取工具所需的 tsv 文件,下面是一段转换代码。
输入文件格式如下
import os
import sys
import json
import numpy as np
import pandas as pd
def get_tsv(path):
"""
:param path:
:return:
"""
label_list = []
vec_list = []
with open(path, encoding="utf-8") as file:
for line in file.readlines():
line = line.strip()
line = line.split()
label_list.append(line[0])
vec_list.append(list(map(float, line[1:])))
label_array = np.array(label_list)
vec_array = np.array(vec_list)
label_df = pd.DataFrame(label_array)
vec_df = pd.DataFrame(vec_array)
label_path = "./label.tsv"
if os.path.exists(label_path):
os.remove(label_path)
with open(label_path, 'w') as write_tsv:
write_tsv.write(label_df.to_csv(sep='\t', index=False, header=False))
vec_path = "./vector.tsv"
if os.path.exists(vec_path):
os.remove(vec_path)
with open(vec_path, 'w') as write_tsv:
write_tsv.write(vec_df.to_csv(sep='\t', index=False, header=False))
print("Finished.")
if __name__ == "__main__":
path = "./glove_sentiment.txt"
get_tsv(path)
最终得到两份文件 vector.tsv 和 label.tsv,逐个上传即可。
上传后效果图:
三、总结
本文主要介绍谷歌2016年开源的Embedding Projector, Embedding 可视化工具及其使用方法。
Embedding Projector工具地址 :http://projector.tensorflow.org/
参考文献
-
Smilkov D, Thorat N, Nicholson C, et al. Embedding projector: Interactive visualization and interpretation of embeddings[J]. arXiv preprint arXiv:1611.05469, 2016. -
https://zhuanlan.zhihu.com/p/24252690
由于微信平台算法改版,公号内容将不再以时间排序展示,如果大家想第一时间看到我们的推送,强烈建议星标我们和给我们多点点【在看】。星标具体步骤为:
(1)点击页面最上方"AINLP",进入公众号主页。
(2)点击右上角的小点点,在弹出页面点击“设为星标”,就可以啦。
感谢支持,比心

推荐阅读
征稿启示| 200元稿费+5000DBC(价值20个小时GPU算力)
完结撒花!李宏毅老师深度学习与人类语言处理课程视频及课件(附下载)
模型压缩实践系列之——bert-of-theseus,一个非常亲民的bert压缩方法
文本自动摘要任务的“不完全”心得总结番外篇——submodular函数优化
斯坦福大学NLP组Python深度学习自然语言处理工具Stanza试用
关于AINLP
AINLP 是一个有趣有AI的自然语言处理社区,专注于 AI、NLP、机器学习、深度学习、推荐算法等相关技术的分享,主题包括文本摘要、智能问答、聊天机器人、机器翻译、自动生成、知识图谱、预训练模型、推荐系统、计算广告、招聘信息、求职经验分享等,欢迎关注!加技术交流群请添加AINLPer(id:ainlper),备注工作/研究方向+加群目的。

阅读至此了,分享、点赞、在看三选一吧🙏