分析海量视频中的违规内容,七牛如何构建弹性深度学习计算平台

我是七牛云人工智能实验室的负责人彭垚,我们七牛云人工实验室是去年 6 月份创立的。我先介绍一下七牛为什么在这个时间点开始做人工智能。
今天演讲的主要内容包括人工智能实验室的前因后果,现在在做的深度学习主要是机器视觉方面研发的成果和近况,以及深度学习计算平台的框架架构。大家可以在会后跟我深度沟通,因为这一块我们才做了大概不到一年的时间。
七牛是云存储起家,服务移动互联网已经五六年的时间了。这几年移动互联网变成了一个富媒体的时代。从社交网站上的图片开始到短视频,今年短视频又开始复苏,包括去年非常火的直播。我们七牛一直跟着这股风潮在服务我们平台上广大的用户。
前面这五六年我们一直在做一件事情,我们把这件事情统一地叫做一个词“Connect”,就是连接。我们连接主要做的事情,最早做的是数据存储,就是让大家把各自 APP 上用户上传的图像、视频、音频内容存放在七牛云存储上。我们基于云存储又做了一些富媒体的编解码、图像处理和其他数据处理等,之后我们又给大家做了 CDN,使大家得到更好的用户体验,能够更好地访问这些数据、浏览这些数据。
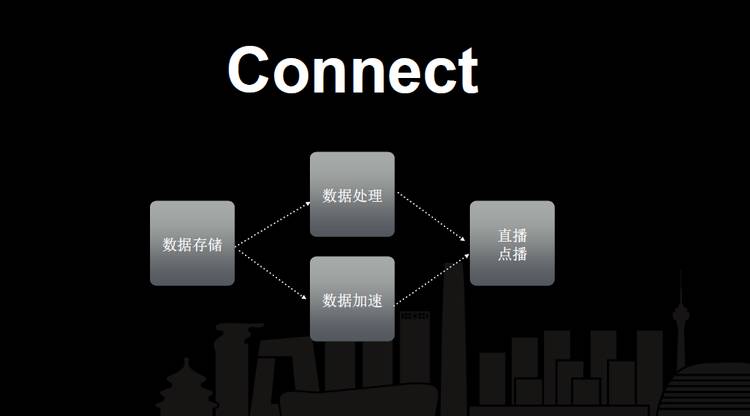
去年我们又给大家提供了直播和点播云。我们一直在做的关键的事情,就是让用户和用户连接起来。那么怎样把用户体验做好,我们这么多年一直在做的事情就是用户体验,这个用户体验体验在什么地方?就是我们把人跟人之间的连接,把基础服务提供给 APP,提供给我们的客户,这是我们这么多年一直在做的事。
后来我们发现每天用户上传的数据非常多,每天用户上传的图像超过 10 亿张,有超过万亿小时的视频在云存储上。我们存储了海量的内容,大部分的存储数据都是图像、视频和音频。

我们问自己,这么多客户在我们的云存储上存了这么多内容,我们接下来该如何给用户提供更好的用户体验。于是我们去问客户需不需要知道这三种内容具体是什么,就是图像、视频、音频的具体内容。你的客户通过 APP 上传,每天在浏览,在分享的内容到底是什么,所以我们就开始思考这个问题,然后发现有这么几件事情,其实他们自己已经在做了。

第一件事是很多 APP 有自己专门的内容审核团队,审核客户上传的东西内容是不是合法,有没有涉黄、涉及反政府的信息在传播。
其次,对这些图像、视频、音频的内容,已经有客户有自己的数据运营团队去分析 APP 客户上传的具体内容,可能用抽样的方法,或者机器学习的方法去分析。
内容分析说起来很简单,就是你上传一个图像具体是什么,但是实际上又很复杂,很难说清楚,内容是什么?
比如我拿出一张图片,每个人描述一张图片里面有什么东西,这个叫图片描述。每个人的描述可能都不一样。主要问题是我们在看到东西,听到东西的时候,我们做出的反应,做出的事情跟我们大脑处理的任务相关。所以内容总结起来其实是跟内容最后的目的相关的。
我们怎么理解这个内容。首先我们可以去把内容解析成很多目的。第一个是分类,分类是基本内容的解析,比如判别这个图片是不是黄色图片。第二个就是检测,比如检测这个视频里面有没有人脸,这些人脸是谁,里面出现了哪些物体,有没有车,车的型号是什么。还有分割,比如说一个画面里面,这个人的形状是怎样的,他跟背景的界限在哪里,这就是一个很简单的分割问题。然后就是跟踪,比如说一个视频中,我们有人脸在走动,这就是一个跟踪问题。以及一个视频的描述,一个视频每一段里出现了什么事件,每一段里面有多少人物,这些是一个描述。还有搜索,我看了很多图片之后搜关键的信息出来,再之上可能就是分析,还可能做很多的处理。

其实我们去解读 content,最关键的是内容的目的。我们首先会去看对这些内容需要做哪一些事情,我罗列的就是我们经常做的一些项目的相关内容。
我们从去年开始做了一个很大的转变,我们从连接基础服务的提供商,变成去给客户做智能的提供商,也就是说我们希望帮助客户去做智能,去提供一些智能的解决方案,让客户去做一些更智能、更互动性的,更了解自己内容的一些行为。这就是我们提出要把我们的连接生意做成智能的生意。我们现在有海量的数据,而图像和视频的泛化能力是很强的,我们通过平台上的数据跟用户一起共建,一起训练,就可以得到很多有价值、有意思的东西出来。

现在这个时代经常提人工智能,智能这个词语到底是什么意思?其实很久以前图灵机的时候就已经有智能这件事情了,而到现在大家对智能还没有一个准确真实的答案,怎么样算是一个智能,我个人理解的智能是类似于人一样直觉型地思考反馈很多的东西,这可能就是最基本初级的智能。

其实我们现在做人工智能,要具备泛化的能力。比如要用深度学习解决像机器视觉这样的问题,首先要解决的最重要的两个问题,一个是大数据的问题,还有一个就是深度学习,也就是机器学习算法的问题。每天我们平台上传处理的图像非常多,可能超过 10 亿,我们不可能把所有的上传图像都拿来学习一次,所以大数据的处理能力非常重要。其次就是我们不可能把所有图像都拿去人工做标注,这个工程量非常大。所以我们会结合很多算法做一些半监督的机器学习,再加上标注,再加上深度的神经网络取得最终的结果。也就是说人工智能实验室在解决两个问题:一个是大数据,另外一个是机器学习的问题。

图中是我们去年成立的实验室 Ataraxia AI Lab。这个名称来源于一个古希腊的哲学学派,这个学派是个怀疑论的,Ataraxia 是指人对世界的认知是有缺陷的,你永远不可能了解事物的本质,就像我刚才提出来智能这个问题,其实每一个阶段都有人提出智能的含义,图灵认为智能能用机器制作出来,后面有希尔乐等等人反驳了他,其实智能这些东西跟用机器模仿出来的东西完全不一样。
我们做人工智能、做认知这件事情,我们一直在质疑自己,最终想达到的境界就是 Ataraxia 的境界,一直在不停地追求永远达不到的一个境界,这个就是古希腊文翻译出来的一个哲学的单词。
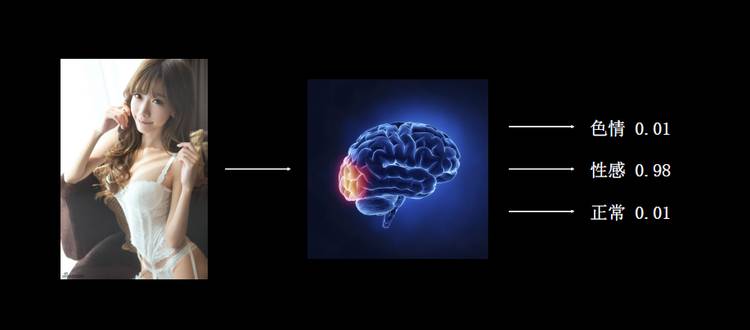
接下来介绍一些我们之前做的事情。我们做的第一件事情就是把一张图片扔进 CNN 的网络,识别这张照片是色情、性感还是正常的。如果这有搞机器视觉的朋友就会觉得这是一个非常常见、非常基础的一个分类问题。但是这个分类问题,它其实不那么好解决。因为会有各种各样的图像表述它是色情的,是性感的,所以模型需要去学习、去标注的内容非常多。我们在去年刚建实验室的时候,有很多实习生在实验室每天标注这些色情内容。当然现在已经少了,因为我们每天会有半监督打标的迭代过程,我们一直在优化鉴别色情暴恐的系统。如果大家有兴趣可以去我们实验室看一下,我们一直固定有人在做图像标注。包括有一些兼职的,在学校里面在帮我们做的,我们自己做了一套网络上的标注系统。
我们线上已经有超过 700 万的样本一直在滚动,每天新增的数据就有一两万,一直往样本中添加,还需要做大量的评估,以及过滤掉大量不需要打标学习的数据。我们对算法的要求已经固化了,算法基本停止了迭代,但是数据还在不停地迭代,鉴黄项目是一个数据量很大,要滚动起来自动迭代的一个项目。
第二个是识别图片具体内容的项目,就是人脸识别。需要对人脸提取特征,然后对大量的图片进行人脸聚类。比如说标注它是 id1 类的人,可以做一些特征的分类,像戴不戴眼镜、年龄、性别、颜值。后面就是场景识别,场景识别现在支持 300 多类场景的识别。户外的场景识别准确率非常高,室内会有很多误判,比如说教室和办公室等等。因为如果学习一个单一任务,可能会有疏漏,比如如果一张图片里有学生,场景是教室的概率就会非常高,成为 Office 的概率就会非常低。现在基本的分类算法,如果要提升背景的准确率,图像里面的人物内容都要结合学习。
还有就是审查,我们能够审查判定图像内容是非色情、非暴力、很健康的。

还有一些跟图像描述相关,就是通过 CNN 提取特征,通过 RNN 去做图像和视频描述相关的内容,比如我们在跟广电相关的一部分工程上做尝试,对一些球赛做分析,会学习很多名人的人脸,大概有 5000 多类名人的人脸。我们一直在搜集、迭代这些数据库以及对球赛的动作去做学习和描述,这就是我前面提到的描述。

第三个就是视频,视频的识别涉及到场景的概念。什么叫场景?你可以想象我们在拍电影,大家就会非常容易理解镜头,就是 Shot 这种概念。比如我们在拍摄这几个人在说话做事情,突然切了一个场景大家在户外开摩托,这就是场景的变化。它最根本的是对人脸和物体的跟踪,如果突然发现这些东西没了,那就说明场景切换了,这就是基本的场景识别。我们会把视频根据场景先切开,切开以后会把场景中的事件 1、事件 2 列出来,比如说有人在打棒球,有人在开摩托车这样的事件罗列出来。

之后会检测视频里的人脸,做一些人脸的识别加跟踪。视频是每帧图像之上持续的表述,一般会用 CNN 识别图像特征,图像特征之上会用 RNN 网络做时序学习。
前面我提到,今天我的主题是讲深度学习和计算平台,接下来跟大家介绍一下计算平台。计算平台同时在解决两个问题,一个是大数据,一个是深度学习算法,抽象来讲计算平台在做一些什么事情呢。首先有一些用户的行为,这些用户的行为会产生很多上传的图像、视频,包括调整相册这些动作,会告诉抽样整理模块,这些图像标注的信息是什么,或者说系统需要搜集这些信息,而抽样整理模块是分布式的富媒体处理模块,会不停地处理抽样和调整的工作,抽样调整完了之后就可以生成目标样本集。通过抽样整理不停地迭代整个样本,得到这个样本集之后我们就会继续上传到训练集群里。
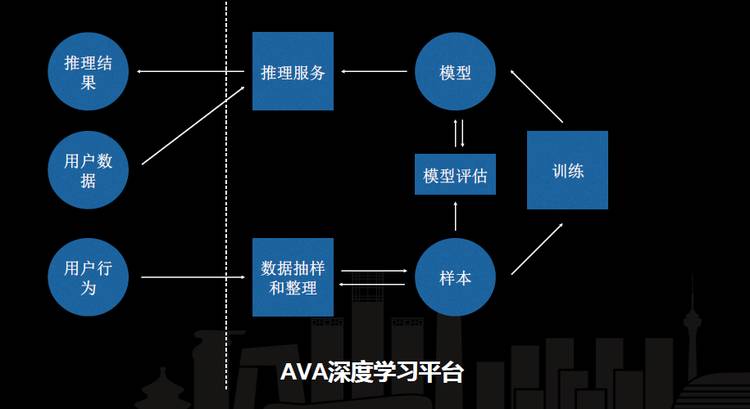
训练集群完成后会生成线上的模型,我们的样本集也会有一部分持续投到模型评估的模块里,模型会根据一套 API 生成器自动上线到推理服务上。最后利用用户数据去访问推理服务,会得到相应的推理结果,这是比较简单的 AVA 的一个基本逻辑。
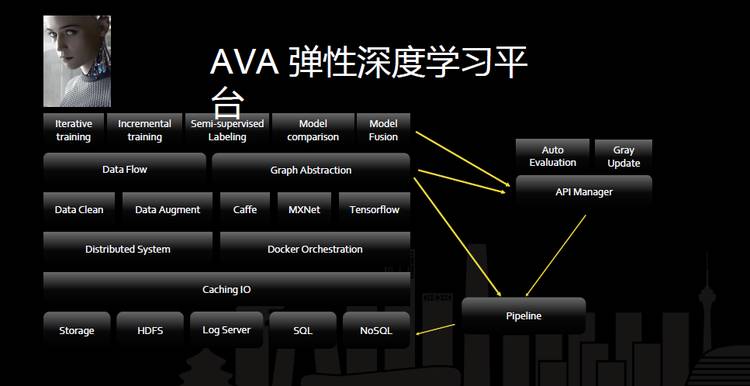
这是我们现在 AVA 整体的架构图。最底层通过七牛云存储了大量线上的图像、视频、音频的数据,这些数据会通过统一的 IO 接口做统一读写管理,这之上我们有两套系统。一套系统专门用于数据抽样和数据整理。Data Flow 里会做数据的清洗,以及数据的放大,数据放大是指对图像的二次加工,通过把同一张图像做裁剪、旋转等操作增加数据样本。
另一套是基于 Docker 的编排系统,这套编排系统与 Kubernetes 有点像,也是七牛很早之前在做的事情,和 Kubernetes 出来的时间差不多,七牛很多线上的图像处理一直在用。Docker 编排系统支撑的是 DataFlow 大数据分布式系统以及支撑了 Caffe、MXnet 、TensorFlow 三个主要的机器视觉框架。模型训练结束以后会自动通过 API Manager 的自动代码生成器生成线上的 Inference API,Inference API 生成自动评估模块以及做自动化的灰度发布。
最上一层我们基于下面的基础系统做了几个 APP 应用系统,第一个就是自动迭代的训练系统,这套自动迭代系统主要用于持续学习的项目。我们每天会有很多新增数据投到训练数据池中。我们会定期地,比如到上一个模型迭代周期结束之后,把这些数据自动化投进训练池中重新清洗,清洗之后重新训练,这就是迭代系统。
还有一个自增长数据集系统。比如鉴黄系统,针对每天都会增长的数据,我们会采取流式的深度学习训练模式,系统在某一个 snapshot 的时候引进一个新的数据集,然后会用这批新的数据再去学习。这个系统可以解决一些对训练出模型频率要求比较高的问题,比如最近比较热的黄色信息。
另外是做了一个半监督打标的系统,这套系统跟我们的打标软件连接。我们用一些轻量的模型,甚至 svm 这种小的分类器先做自动的图像预标注,跟我们的分类器的中心做比较,比较出来之后,拿出一部分的数据再去学习,投入到我们应该要学习的样本中。这其实也是模型融合的一点。
我们做了大量的模型融合。我们会选不同的 CNN 网络,在一些大一点的和小一点的不同的情况下做模型的融合。
模型融合确实比较有效,但是它比较费资源,费人力,所以我们就把这个单独做成一个 APP 自动化地运行,有时候在一些特定的场景还是需要模型融合的方法才能把准确率优化到能达到商用。
训练的过程还有一块是 Pipeline,这个 Pipeline 其实是对日志做迭代收集,做 transform,到不同的存储结构上,这些可能是一些图像的标签,视频的标签这些内容,这就是我们整体的 AVA 平台的架构。
这里我没有提到 multi task。实际上它的处理比较复杂,不像鉴黄那么简单,大部分问题都不会这么简单。举个特别简单的例子,比如说人脸聚类,也有三个小模型,首先要检测到图像里人脸的位置,其次要用机器学习抽取图片的人脸特征,之后利用这些特征做聚类。至少需要三个模型。
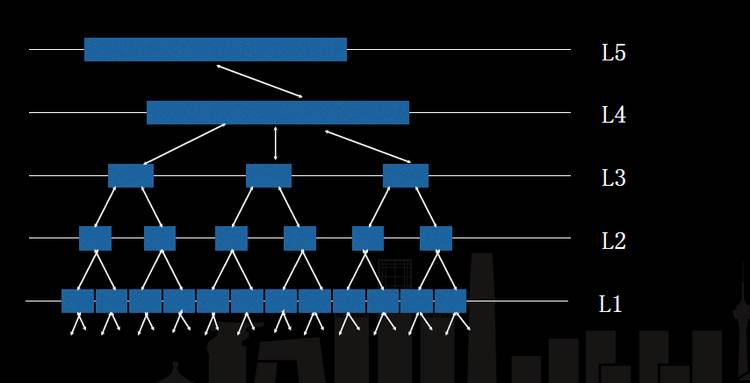
这个其实和人脑也很像,人脑解决问题是像这样的图。图中有 L1 到 L5,大脑皮层每一层都是这么处理问题的。信息从最底层扔给几个基础的模型,去做一些抽象、完成一些任务,到第二层的时候再去解决更高维的一些任务,比如像聚类这样感知型的任务,再上面做一些更具体的任务,比如搜索、判别这类事情。最高维就是在做一些预警,一些业务层的事情。已有的 AVA 只能解决单一的问题,不能满足整个人工智能的设计框架。所以我们做了一套 Argus 系统,实际上就是 API 的整体网状管理系统,它支持 Pipeline,也支持并行处理。可以直接用 Pipeline 的语义解决这种事情。
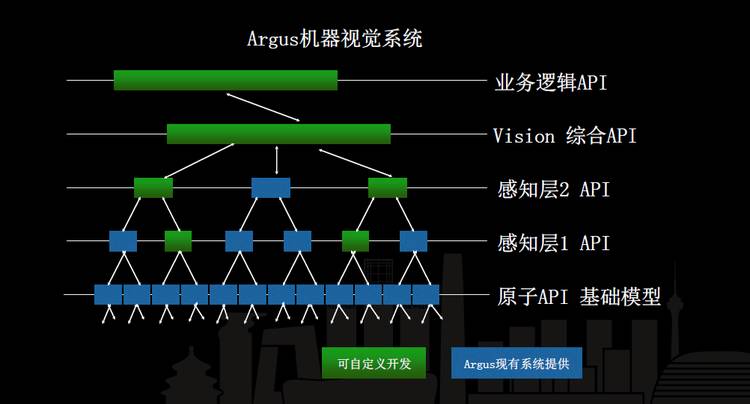
Argus 系统最底层是通过 AVA 训练出来的原子 API,有了原子的 API 之后上层是感知层,感知层会做基于原子 API 的抽象做一些复杂任务,比如聚类。再之上是一些高级的任务,最后是一些与视觉相关的综合 API,再往上是业务逻辑大数据分析,在 Vision 层我已经不管了,我把这个东西扔到抽象层结构化数据,或者说 vision 跟语言相关的加了一些 RNN 把语意描述出来之后就扔给业务逻辑处理了。所以现在 API 的 framework 整体设计成这个样子。设计成这套系统后,有很多是我们新研发的,Argus 系统现有的是蓝色的,原子 API 是通过 AVA 训练出来的,AVA 还没有公开,原子的基础视觉 API 都是我们自己研发的。我们希望之后跟大家公开用 AVA 训练出来的特定的一些识别模型。我们也在尝试性地找一些想做这个事情的长期合作伙伴。
上面业务层的 API 客户可以独立开发应用,包括像感知层、综合的整体业务逻辑的 API,直接可以通过我们 user-defined 图像处理模块,直接写一些简单的 docker 处理镜像 load 进来参与到 Argus 的机器视觉系统里。也就是说高层的业务层或者说智能的大数据分析能力是开放给客户的。
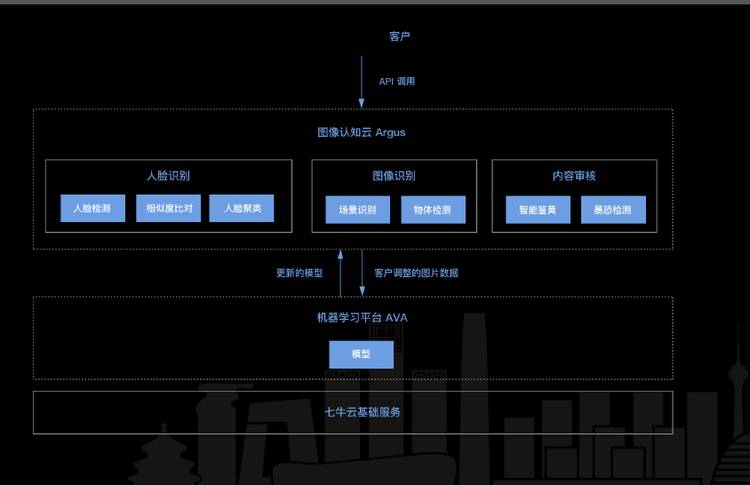
这是我们现在整体上 Argus 的图像认知,有很多基础服务,包括一些业务层的比如人脸检测、相似度比对、人脸聚类、鉴黄、暴恐,这些基础的模型之下,有一个一直在迭代运算的 AVA 深度学习平台,它一直不停地产出一些基础的原子 API 给 Argus 系统,Argus 系统跟客户走得更近,让客户可以自己在 Argus 上编 Docker 镜像,load 上来,一起完成智能的任务。
最后我想说 time to be an AI company,希望七牛之前的合作伙伴以及将来大家愿意跟我一起合作,可以一起在 Argus 系统上添砖加瓦,做很多有意思的机器视觉系统。
彭垚,七牛云技术总监,人工智能实验室发起人和负责人,主导了七牛云人工智能和机器学习云的架构和发展,在分布式计算存储,富媒体海量数据分析与深度学习领域有超过 10 年的产品研发经验,曾担任 IBM 系统与科技实验室研发架构和管理工作多年,在美国、法国发表数篇专业领域发明专利。
关注 AI 前线公众账号(直接识别下图二维码),点击自动回复中的链接,按照提示进行就可以啦!还可以在公众号主页点击下方菜单“加入社群”获得入群方法~AI 前线,期待你的加入!

【仅剩 2 个座】想学 TensorFlow?不如看看 StuQ《TensorFlow 实战——基础班+Capstone 项目班》。硅谷大牛郑泽宇直接带,还开创国内首个“顶点项目”(Capstone Project:风靡美国,指教育里最后、最颠峰的学习经验),带你从上到下掌握 TF。原价 5599 元,早鸟价 3999 元,仅剩 2 个名额,预购从速~

报名地址请戳【阅读原文】





