将离策略评估看作「分类」问题,谷歌提出新型强化学习模型选择方法OPC
选自Google AI Blog
作者:Alex Irpan
机器之心编译
参与:Geek AI、路
完全的离策略强化学习可以基于之前智能体收集到的数据训练多个模型,但它无法在没有真实机器人的情况下进行模型评估。而离策略评估「off-policy evaluation,OPE」可以帮助研究人员选择最有潜力的模型,进而在真实环境中评估。谷歌最近提出一种新型离策略评估方法——离策略分类,将评估视为一个分类任务,根据过去的数据评估智能体的性能,其中智能体的动作「action」被标注为「可能导致成功」或「一定导致失败」。OPC 可以扩展到更广泛的任务,包括现实世界中基于视觉的机器人抓取任务。
强化学习(RL)是一种让智能体根据经验学习决策的框架。离策略强化学习是众多强化学习变体中的一种,其中每个智能体使用由其它智能体收集到的数据(离策略数据)以及它自己收集到的数据进行训练,从而学习「机器人行走和抓取」等可泛化技能。
另一方面,完全的离策略强化学习中,智能体完全根据旧的数据进行学习,这非常有吸引力,因为它让模型可以在不需要实体机器人的情况下进行迭代。通过完全的离策略强化学习,我们可以使用之前的智能体收集到的同样固定数据集来训练多个模型,然后从中选取最佳模型。
然而,完全的离策略强化学习也带来了一个问题:尽管可以在没有真实机器人的情况下进行训练,但是并不能进行模型的评估。此外,使用实体机器人进行真值(ground truth)评估的效率实在是太低了,无法测试需要对大量模型进行评估的有潜力的方法(例如使用 AutoML 进行自动化神经网络架构搜索)。
这一挑战推动了离策略评估(OPE)的发展,OPE 即使用其它智能体收集到的数据研究新智能体质量的技术。通过 OPE 的排序,我们可以有选择性地在真实机器人上测试最有潜力的模型,这可以在同样的真实机器人预算下显著地扩展实验规模。
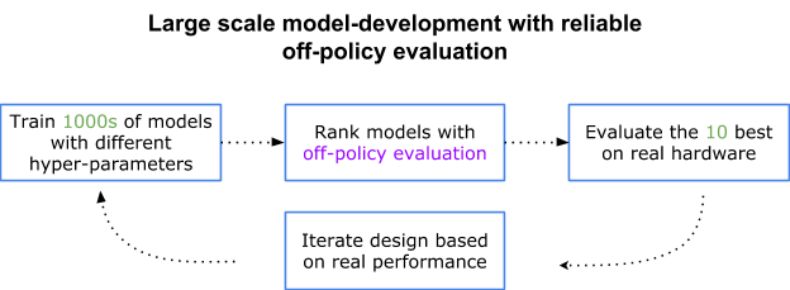
开发真实世界模型的示意图。假设我们每天可以评估 10 个模型,在没有离策略评估的情况下,我们将需要 100 倍的时间来进行模型评估。
尽管 OPE 框架非常有发展前景,但是它假设我们拥有一种基于旧数据对模型性能进行准确排序的离策略评估方法。然而,收集过去经验的智能体可能与新学得的智能体在行为方式上存在很大差别,这使得我们很难得到良好的性能评估。
在论文「Off-Policy Evaluation via Off-Policy Classification」中,谷歌提出了一种叫作「离策略分类」(Off-policy classification,OPC)的新型离策略评估方法。该方法将评估视为一个分类任务,根据过去的数据评估智能体的性能,其中智能体的动作(action)被标注为「可能导致成功」或「一定导致失败」。
该方法适用于图像(相机)输入,而且不需要通过重要性采样或使用目标环境的准确模型(这两种方法在之前工作中经常被使用)重新调整数据权重。这项研究表明,OPC 可以扩展到更大的任务,包括现实世界中基于视觉的机器人抓取任务。
OPC 是如何工作的?
OPC 建立在两个假设之上:1)最终的任务具有确定性动态(deterministic dynamics),即状态的变化不存在随机性;2)在每次试验结束时,智能体要么成功要么失败。对于很多任务(例如拾取物体、走迷宫、赢得游戏等),第二个假设是很自然的。由于每次试验要么成功要么失败,因此我们可以为每个动作打上一个二分类标签。如果某个动作可以导致成功,我们就将其称为「有效的」(effective);而如果某个动作一定会导致失败,我们就将其称为「灾难性的」(catastrophic)。
OPC 使用到了一个 Q 函数,它通过 Q 学习算法学得。如果智能体选择在当前状态下采取某个动作,则 Q 函数会估计未来的总奖励(reward)。接着,智能体会选择具有最大总奖励估计值的动作。谷歌研究人员在论文中证明了,智能体的性能是根据它所选择的动作「有效」的频率来衡量的,这取决于「Q 函数」进行动作分类的准确率。而该分类准确率被作为离策略评估分数。
然而,以往的试验所得到的数据只进行了部分的标注。例如,如果一个之前的试验失败了,由于我们不知道哪个动作是「灾难性」的,我们不会得到负标签。为了解决这个问题,谷歌研究人员利用半监督学习中的技术 PU 学习(positive-unlabeled learning),根据部分标注数据得到对分类准确率的估计。这里的准确率就是 OPC 得分。
对 Sim-to-Real Learning 的离策略评估
在机器人学中,经常使用仿真数据和迁移学习技术来降低学习机器人技能的样本复杂度。这种做法非常实用,但是针对真实世界机器人调整这些 sim-to-real 技术是非常具有挑战性的。这很像不使用真实机器人训练的离策略强化学习,它也是在仿真环境中训练的,但是对于这种策略的评估仍然需要使用一个真实机器人。
在这里,离策略评估可以再次发挥作用,我们可以采用一种仅仅在仿真环境下训练的策略,然后使用之前的真实世界数据来评估它,从而衡量它迁移到真实机器人上的性能。谷歌在完全的离策略强化学习和 sim-to-real 强化学习两种场景下测试了 OPC。
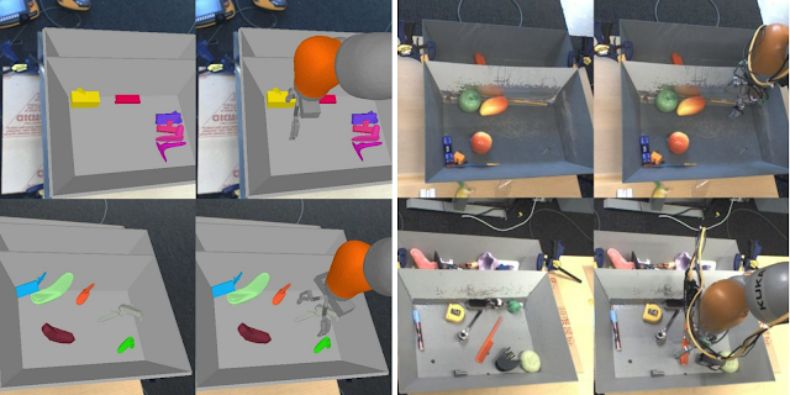
仿真经验与真实世界经验的区别示例。这里,仿真图像(左图)比真实世界图像(右图)的视觉复杂度低。
实验结果
研究人员首先设置了一个机器人抓取任务的仿真版本,方便研究者轻松训练和评估多个模型,从而对离策略评估进行基准对比测试。这些模型都是通过完全的离策略强化学习训练的,然后通过离策略评估方法来评估。研究人员发现,在多个机器人任务中,一种被称为「SoftOPC」的 OPC 变体在预测最终成功率时取得了最佳性能。
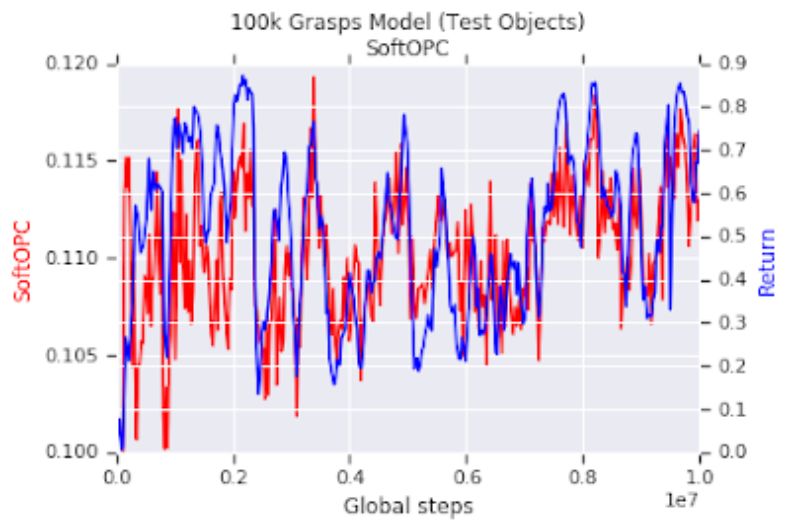
在仿真的抓取任务中的实验结果。红色曲线是在训练过程中记录的无量纲 SoftOPC 得分(基于旧数据评估)。蓝色曲线是仿真环境下的抓取成功率。我们可以看到,在仿真器中,基于旧数据的 SoftOPC 与模型的成功抓取密切相关。
在仿真环境下取得成功后,研究人员在真实世界任务中尝试使用 SoftOPC。他们选取了 15 个模型,经过训练这些模型对仿真和真实环境的差异有不同程度的鲁棒性。在这些模型中,有 7 个仅在仿真环境下进行训练,其余 8 个模型则在仿真和真实世界数据混合的环境下进行训练。
对于每个模型,研究者基于离策略真实世界数据评估 SoftOPC,然后对真实世界中的成功抓取进行评估,看看 SoftOPC 预测这些模型性能的能力如何。结果表明,在真实数据上,SoftOPC 确实会得到与真正的成功抓取相关的得分,所以我们可以使用过去的真实经验对 sim-to-real 技术进行排序。

三种不同 sim-to-real 方法的 SoftOPC 得分和真实性能:基线仿真、具备随机纹理和光照的仿真,以及使用 RCAN 训练的模型。以上三种模型都使用非真实数据训练,然后在一组真实数据验证集上使用离策略评估方法进行评估。结果表明,SoftOPC 得分的顺序与真实成功抓取的顺序相符。
下图是根据所有 15 个模型的结果绘制的散点图。每个点代表每个模型的离策略评估得分和真实世界成功抓取情况。研究者将不同的打分函数与其最终成功抓取情况的相关性进行了对比。SoftOPC 并不完全与真实的成功抓取相关联,但是其得分要明显地比时序差分误差(TD error,一种标准的 Q 学习损失)等基线方法更可靠。
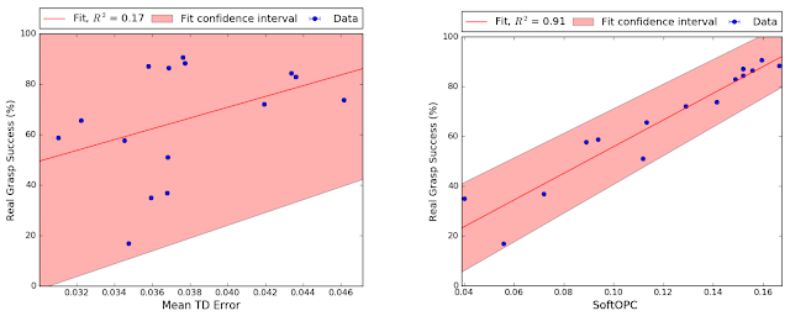
sim-to-real 评估实验的结果。左图是基线,模型的时序差分误差。右图是 SoftOPC。阴影区域是 95% 置信区间。SoftOPC 的相关性明显要更强。
未来的工作
未来工作的一个有前景的方向是:能否放宽对该任务的假设,从而支持在动态方面具有更多噪声的任务,即对是否成功只能得到部分信度。
原文链接:https://ai.googleblog.com/2019/06/off-policy-classification-new.html
本文为机器之心编译,转载请联系本公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者 / 实习生):hr@jiqizhixin.com
投稿或寻求报道:content@jiqizhixin.com
广告 & 商务合作:bd@jiqizhixin.com


