eBay 基于 Apache Kyuubi 构建统一 Serverless Spark 网关的实践

首先介绍一下 Kyuubi。Kyuubi 是一个分布式的 Thrift JDBC/ODBC server,支持多租户和分布式等特性,可以满足企业内诸如 ETL、BI 报表等大数据场景的应用。项目由网易数帆发起,已经进入 Apache 基金会孵化,目前的主要方向是依托本身的架构设计,围绕各类主流计算引擎,打造一个 Serverless SQL on Lakehouse 服务,目前支持的引擎有 Spark、Flink、Trino(也就是 Presto)。我今天的主题是围绕 Kyuubi 和 Spark, 关于其它计算引擎这里不再展开。
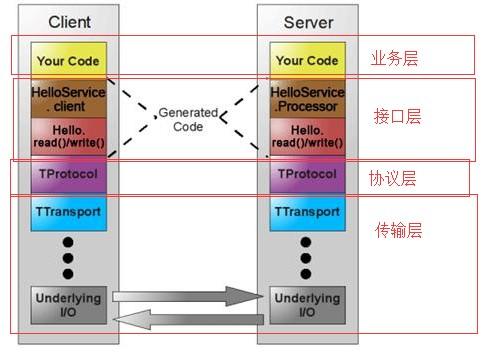
对于 Spark,Kyuubi 有 HiveServer2 的 API,支持 Spark 多租户,然后以 Serverless 的方式运行。HiveServer2 是一个经典的 JDBC 服务,Spark 社区也有一个类似的服务叫做 Spark Thrift Server。这里介绍一下 Spark Thrift Server 和 Kyuubi 的对比。
Spark Thrift Server 可以理解为一个独立运行的 Spark app,负责接收用户的 SQL 请求, SQL 的编译以及执行都会在这个 app 里面去运行,当用户的规模达到一定的级别,可能会有一个单点瓶颈。
对于 Kyuubi,我们可以看右边这张图,有一个红色的用户和一个蓝色的用户,他们分别有一个红色的 Spark app 和一个蓝色的 Spark app,他们的 SQL 请求进来之后,SQL 的编译和执行都是在对应的 app 之上进行的,就是说 Kyuubi Server 只进行一次 SQL 请求的中转,把 SQL 直接发送给背后的 Spark app。
对于 Spark Thrift Server 来讲,它需要保存结果以及状态信息,是有状态的,所以不能支持 HA 和 LB。而 Kyuubi 不保存结果,几乎是一个无状态的服务,所以 Kyuubi 支持 HA 和 LB,我们可以增加 Kyuubi Server 的个数来满足企业的需求。所以说 Kyuubi 是一个更好的 Spark SQL Gateway。
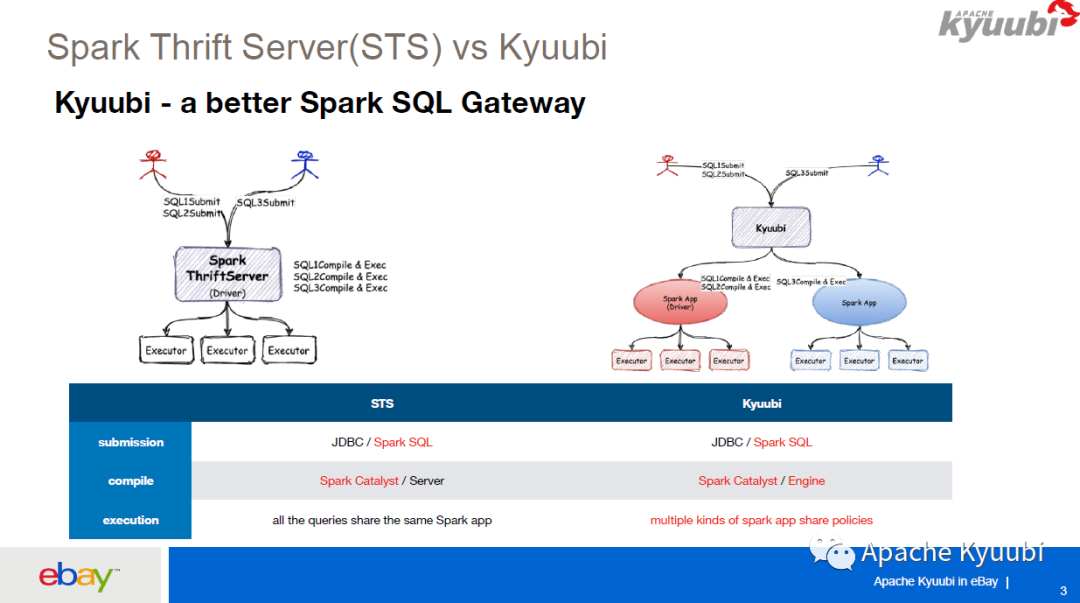
Kyuubi 的架构分为两层,一层是 Server 层,一层是 Engine 层。Server 层和 Engine 层都有一个服务发现层,Kyuubi Server 层的服务发现层用于随机选择一个 Kyuubi Server,Kyuubi Server 对于所有用户来共享的。Kyuubi Engine 层的服务发现层对用户来说是不可见的,它是用于 Kyuubi Server 去选择对应的用户的 Spark Engine,当一条用户的请求进来之后,它会随机选择一个 Kyuubi Server,Kyuubi Server 会去 Engine 的服务发现层选择一个 Engine,如果 Engine 不存在,它就会创建一个 Spark Engine,这个 Engine 启动之后会向 Engine 的服务发现层去注册,然后 Kyuubi Server 和 Engine 之间的再进行一个 Internal 的连接,所以说 Kyuubi Server 是所有用户共享,Kyuubi Engine 是用户之间资源隔离。
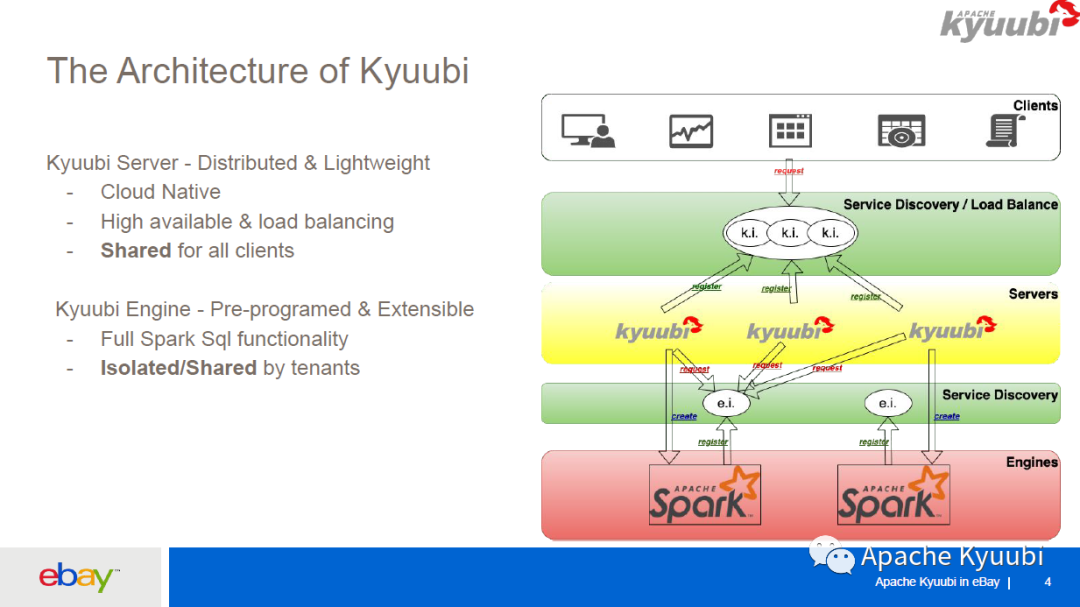
Kyuubi 支持一些 Engine 的共享级别,它是基于隔离和资源之间的平衡。在 eBay 我们主要使用到了 USER 和 CONNECTION 级别。首先对于 CONNECTION 级别,对于用户的每次连接都会创造一个新的 app,也就是一个 Kyuubi Engine,适用于 ETL 场景,ETL 的 workload 比较高,需要一个独立的 app 去执行;对于 USER 级别,我们可以看到这里有两个 user,一个叫 Tom,一个叫 Jerry,Tom 的两个 client 连接 Kyuubi Server,会连接到同一个属于 Tom 的 Kyuubi Engine,USER 级别适用于 ad-hoc 场景,就是对于同一个用户所有的连接都会到同一个 Kyuubi Engine 去执行,而对 Jerry 的所有请求都会到 Jerry 的 Kyuubi Engine 去执行。
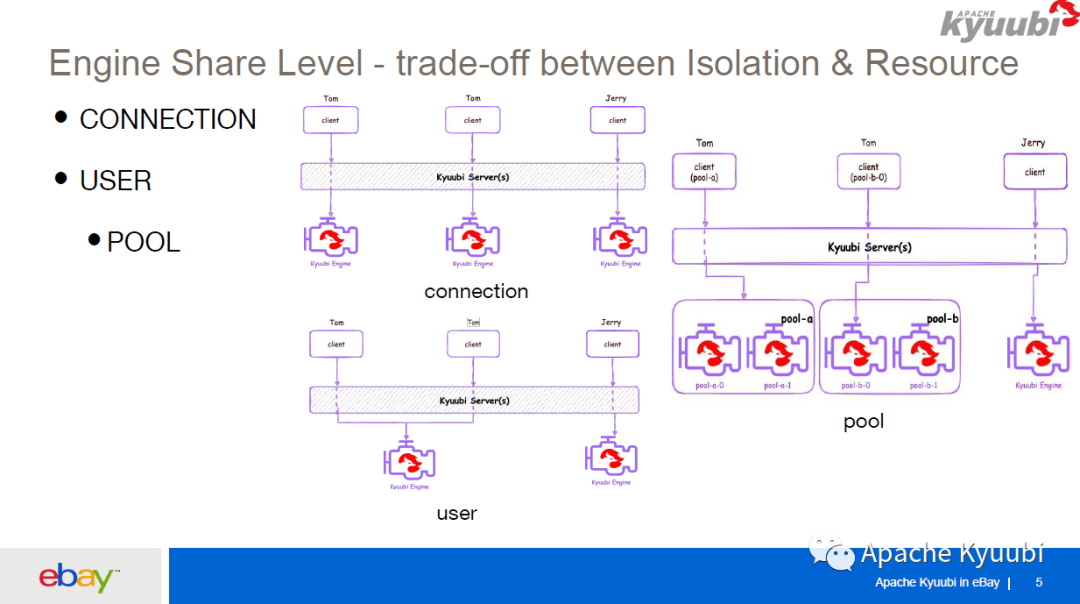
对 USER 共享级别 Kyuubi 做了一些加强,引入了一个 Engine POOL 的概念,就像编程里面的线程池一样,我们可以创建一个 Engine 的 pool,pool 里面有编号,比如说这里 Tom 创建了两个 pool,叫做 pool-a 和 pool-b,编号为 pool-a-0,pool-a-1,如果说在客户端请求的时候直接指定这个 pool 的名字,Kyuubi server 会从这个 pool 里面去随机选择一台 Engine 执行;如果 Tom 在请求的时候不仅指定 pool 的名字,还指定了这个 Engine 在 pool 里面的索引,比如说这里指定 pool-b-0,Kyuubi Server 会从这个 pool-b 里面选择编号为 0 的 Engine 去做计算。对应的参数为kyuubi.engine.share.level.subdomain.
这在 eBay 里面为 BI 工具集成提供了很大的便利,因为 eBay,每个分析师团队可能用同一个账号去执行数据分析,BI 工具会根据用户的 IP 去创建一个 Kyuubi Engine,因为每个分析师需要的参数配置可能是不一样的,比如说他们的内存的配置是不一样的,BI 工具就可以创建一个这样的 engine pool,然后保存用户的 IP 和所创建 Engine 索引的一个 mapping,然后在这个用户的请求过来的时候,根据 BI 工具保存的 IP 映射关系,去找到该用户所创建的 Engine,或者是说一个团队里面很多人使用一个 pool,可以预创建许多 Spark app,让这一个组里面的人可以随机选择一个 Engine 去做执行,这样可以加大并发度。同时也可以作为 USER 共享级别下面的一个标签用于标注该引擎的用途,比如说我们可以给 beeline 场景和 java JDBC 应用使用场景创建 USER 共享级别下的不同 engine pool, 在不同使用场景下使用不同的 engine pool, 互相隔离。
前面提到了不同的 Engine 共享级别,有的是为每个连接创建一个 Spark App,有的是为一个用户创建一个或者多个 Kyuubi Engine,你可能会担心资源浪费,这里讲一下 Kyuubi Engine 对资源的动态管理。首先,一个 Kyuubi Engine,也就是一个 Spark app,分为 Spark driver 和 Spark executor,对于 executor,Spark 本身就有一个 executor dynamic allocation 机制,它会根据当前 Spark job 的负载来决定是否向集群申请更多的资源,或者是说将目前已申请的资源返还给集群。所说我们在 Kyuubi Server 层加一些限制,比如强制打开这个 executor dynamic allocation,并且把在空闲时候最小的 executor 数量设为 0,也就是说当一个 app 非常空闲的时候只有一个 driver 带运行,避免浪费资源。除了 executor 层的动态回收机制,Kyuubi 为 driver 层也加了资源回收机制。对于 CONNECTION 分享级别,Kyuubi Engine 只有在当前连接才使用,当连接关闭的时候 Spark driver 会直接被回收掉。对 USER 级别的共享,Kyuubi 有一个参数kyuubi.session.engine.idle.timeout
来控制 engine 的最长空闲时间,比如说我们将空闲时间设置为 12 小时,如果 12 个小时之内都没有请求连接到这个 Spark app 上,这个 Spark app 就会自动结束,避免资源浪费。
下面讲一下 Use Case。目前 Kyuubi 支持了 SQL 语言和 Scala 语言的执行,也可以把 SQL 和 Scala 写在一起去跑。因为 SQL 是一种非常用户友好的语言,它可以让你不用了解 Spark 内部的原理,就可以使用简单的 SQL 语句去查询数据,但是它也有一定的局限性;而 Scala 语言需要一定的门槛,但它非常的灵活,我们可以去写代码或者去操纵一些 Spark DataFrame API。
举一个例子,就是可以在一个 SQL 文件或者一个 notebook 里面去混合编程。首先用 SQL 语句创建了一张训练的数据表,在创建表之后通过 SET 语句把语言模式设为 Scala,然后开始用 Scala 去写代码,这里是用一个 kMeans 把训练数据进行处理,处理完之后把输出保存在一张表里面,再把语言模式切换到 SQL,继续用 SQL 去处理。这样非常方便,我们可以结合 SQL、Scala 的优点,基本上可以解决数据分析里面的大部分的 case。我们也在 Kyuubi JDBC 里面提供了一个非常友好的接口,可以直接调用KyuubiStatement::ExecuteScala去执行 Scala 语句。

我们 Hadoop team 管理了很多个 Hadoop 集群,这些集群分布在不同的数据中心,有不同的用途,有一套统一的基于 KDC 和 LDAP 的权限校验。
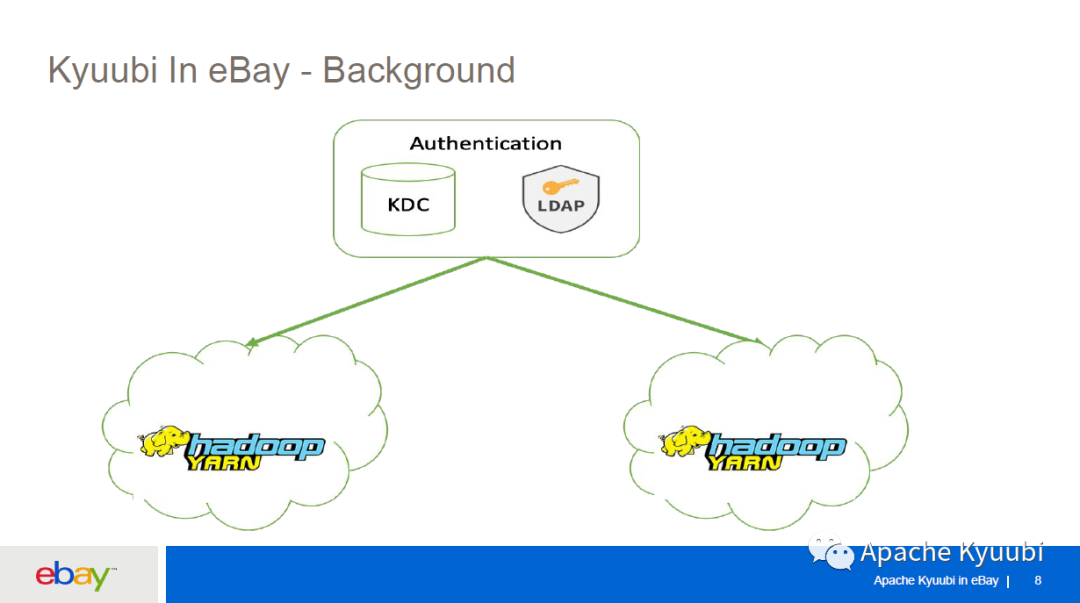
刚开始引入 Kyuubi 的时候,我们就在想要为每个集群都部署一个 Kyuubi 服务吗?如果这样我们可能要部署三四个 Kyuubi 服务,在升级的时候需要进行重复操作,管理起来很不方便,所以我们就想是否能够用一套 Kyuubi 来服务多个 Hadoop 集群。
下图就是我们为这个需求所做的一些增强。首先,因为我们是支持 KDC 和 LDAP 认证的,我们就让 Kyuubi 同时支持 Kerberos 和 Plain 类型的权限认证,并对 Kyuubi Engine 的启动、Kyuubi 的 Beeline 做了些优化,然后我们扩展了一些 Kyuubi 的 thrift API 支持上传下载数据。针对前面说的要用一个 Kyuubi 去访问多个 Hadoop 集群,我们加了一个 cluster selector 的概念,可以在连接的时候指定参数,让请求路由到对应的集群。还有就是我们也在完善 RESTfull API,已经为 Kyuubi 支持了 SPNEGO 和 BASIC 的 RESTfull API 权限认证。此外我们也在做 RESTfull API 去跑 SQL Query 和 Batch job 的一些工作。图中打编号的是已经回馈社区的一些 PR。

这里讲一下 2、3、4,对 Kyuubi 的 Thrift RPC 的一些优化。首先因为 Thrift RPC 本身是针对 HiveServer2 来设计的,HiveServer2/Spark Thriftserver2 里面建立一个连接是非常快的。而在 Kyuubi 里面建立一个连接的话,首先要连接到 Kyuubi Server,Kyuubi Server 要等到和远端的 Kyuubi Engine 建立连接完成之后,才能把结果返回给客户端。
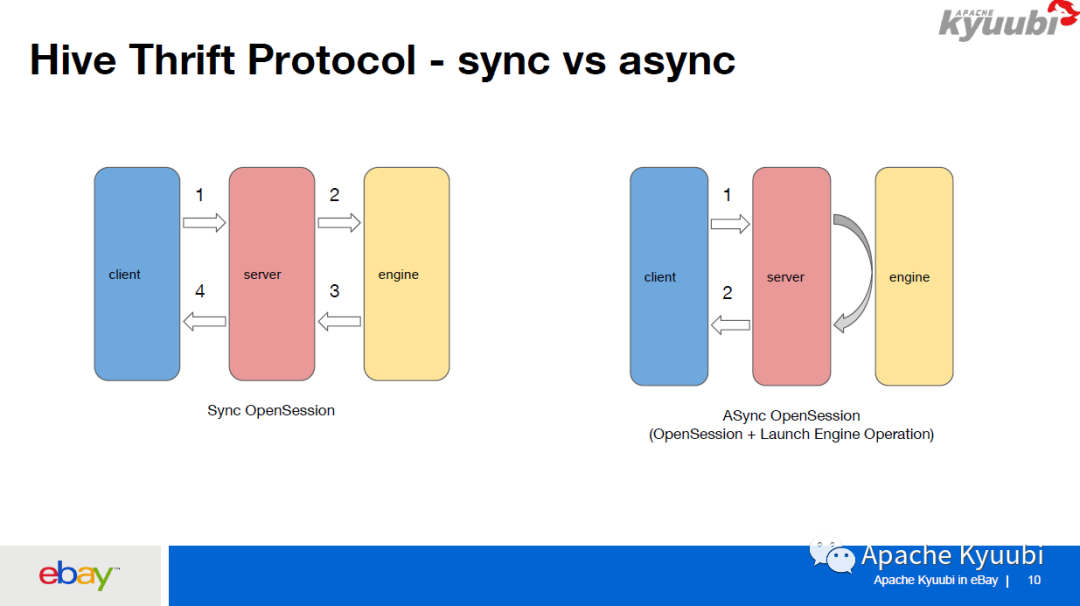
如果 Kyuubi Engine 一开始不存在,而且在启动 Kyuubi Engine 的时候由于资源问题,或者是有一些参数设置不对,比如说他设置了无效的spark.yarn.queu,导致出现错误的话,中间可能会有一分钟或者说几十秒的延迟,客户端要一直等,在等的过程中也没有任何的 log 返回给客户端。我们就针对这个做了一些异步的 OpenSession,将 OpenSession 分为两部分,第一步是连接到 Kyuubi Server,Kyuubi Server 再异步启动一个 LaunchEngine Operation,之后立即把 Kyuubi Server 连接给客户端,这样客户端可以做到一秒钟就可以连接到 Kyuubi Server。但是他的下条语句以及进来之后,会一直等到这个 Engine 初始化好之后才开始运行。其实这也是我们的 PM 的一个需求,即使第一条语句运行时间长一点也没关系,但是连接是一定要很快,所以我们就做了这样一个工作。
因为 Hive Thrift RPC 是一个广泛应用而且非常用户友好的 RPC,所以我们在不破坏它的兼容性的情况下基于 Thrift RPC 做了一些扩展。首先对于 ExecuteStatement 这种请求及返回结果,它会在 API 里面返回一个 OperationHandle,再根据 OperationHandle 获取当前 Operation 的状态和日志。因为我们前面已经把 OpenSession 拆成了 OpenSession 加上一个 LaunchEngine Operation,所以我们想把 LaunchEngine Operation 的一些信息,通过 OpenSession request 这个 configuration map 把它返回去,我们是把一个 OperationHandler 分为两部分,一部分是 guid,另一部分是 secret,放到 OpenSessionResp 的 configuration Map 里面。

然后在拿到 OpenSessionResp 之后就可以根据这个 configuration 拼出 Launch Engine Operation 对应的 OperationHandler,然后再根据它去拿这个 LaunchEngine 的日志和状态。
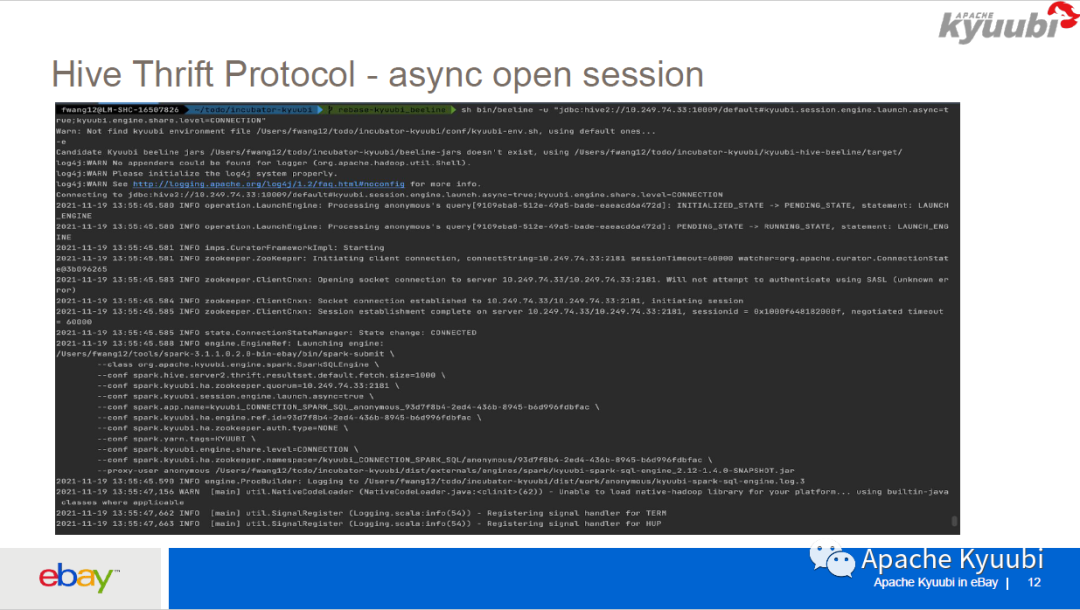
下面是一个效果,我们在建立 Kyuubi 连接的时候可以实时知道spark-submit的过程中到底发生了什么。比如说用户将 spark.yarn.queue 设置错了,或者说由于资源问题一直在等待,都可以清楚的知道这中间发生了什么,不需要找平台维护人员去看日志,这样既让用户感到极为友好,也减少了平台维护人员的 efforts。
前面说到要用一个 Kyuubi 服务来服务多个集群,我们就基于 Kyuubi 构建了一个 Unified & Serverless Spark Gateway。Unified 是说我们只有一个 endpoint,我们是部署在 Kubernetes 之上的,使用 Kubernetes 的 LB 作为 Kyuubi Server 的服务发现,endpoint 的形式就是一个 Kubernetes 的 LB 加上一个端口,比如说kyuubi.k8s-lb.ebay.com:10009,要服务多个集群,我们只需要在 JDBC URL 里面加上一个参数kyuubi.session.cluster,指定 cluster name,就可以让他的请求到指定的集群去执行。关于权限校验我们也是用 Unified 的,同时支持 Kerberos 和 LDAP 权限校验。关于 functions(功能)也是 Unified 的,同时支持 Spark-SQL、Spark-Scala 以及 ETL Spark Job 的提交。
关于 Serverless, Kyuubi Server 部署在 Kubernetes 之上,是 Cloud-native 的,而且 Kyuubi Server 支持 HA 和 LB,Kyuubi Engine 支持多租户,所以对于平台维护人员来说成本非常低。
这是我们大概的一个部署,对于多集群我们引入了 Cluster Selector 的概念,为每个集群都配了一个 Kubernetes ConfigMap 文件,在这个文件里面有这个集群所独有的一些配置,比如这个集群的 ZooKeeper 的配置,集群的环境变量,会在启动 Kyuubi Engine 的时候注入到启动的进程里面。
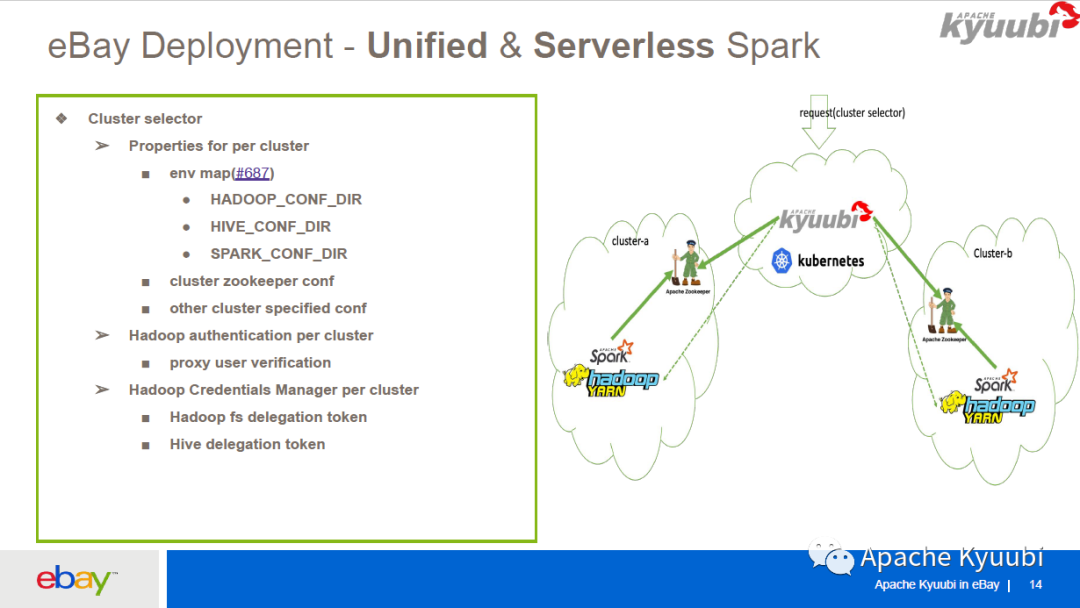
每个集群的 super user 的配置也是不一样的,所以我们也支持了对各个集群进行 super user 的校验。目前 Kyuubi 支持 HadoopFSDelegation token 和 HiveDelegation token 的刷新,可以让 Spark Engine 在没有 keytab 的情况下去长运行,而不用担心 token 过期的问题。我们也让这个功能支持了多集群。
用户一个请求进来的过程是这样的:首先他要指定一个 Cluster Selector,Kyuubi Server(on Kubernetes)根据这个 Selector 去找到对应的集群,连接集群的 ZooKeeper,然后查找在 ZooKeeper 里面有没有对应的 Spark app, 如果没有就提交一个 app 到 YARN 上面(Spark on YARN),Engine 在启动之后会向 ZooKeeper 注册,Kyuubi Server 和 Kyuubi Engine 通过 ZooKeeper 找到 Host 和 Port 并创建连接。
Kyuubi 从一开始就支持 Thrift/JDBC/ODBC API, 目前社区也在完善 RESTFul API. eBay 也在做一些完善 RESTFul API 的工作,我们给 RESTful API 加了权限校验的支持,同时支持 SPNEGO(Kerberos) 和 BASIC(基于密码) 的权限校验。我们计划给 Kyuubi 增加更多的 RESTful API。目前已有的是关于 sessions 的 API,比如可以关掉 session,主要用于来管理 Kyuubi 的 sessions。我们准备加一些针对 SQL 以及 Batch Job 的 API。关于 SQL 就是可以直接通 RESTful API 提交一条 SQL Query,然后可以拿到它的结果以及 log。关于 Batch Job 就是可以通过 RESTful API 提交一个普通的使用 JAR 来运行的 Spark app,然后可以拿到 Spark app 的 ApplicationId,还有 spark-submit 的 log,这样可以让用户更加方便地使用 Kyuubi 完成各种常用的 Spark 操作。
对用户来说,他们能够非常方便地使用 Spark 服务,可以使用 Thrift、JDBC、ODBC、RESTful 的接口,它也是非常轻量的,不需要去安装 Hadoop/Spark binary,也不需要管理 Hadoop 和 Spark 的 Conf,只需要用 RESTful 或者 Beeline/JDBC 的形式去连接就好。
对我们平台开发团队来说,我们有了一个中心化的 Spark 服务,可以提供 SQL、Scala 的服务,也可以提供 spark-submit 的服务,我们可以方便地管理 Spark 版本,不需要将 Spark 安装包分发给用户去使用,可以更好地完成灰度升级,让 Spark 版本对于用户透明化,让整个集群使用最新的 Spark,也节省集群的资源,节省公司的成本。此外,平台的维护也是比较方便的,成本很低,因为我们只需要维护一个 Kyuubi 服务来服务多个 Hadoop 集群。
目前,除了 eBay,不仅国内有很多公司在使用 Kyuubi,国外也有公司在使用这个项目。

作者:
王斐,eBay 软件工程师,Apache Kyuubi PPMC Member
附视频回放及 PPT 下载:
https://www.slidestalk.com/SeaTunnel/Apache_Kyuubi_____eBay__________________?video
延伸阅读:
Kyuubi 主页:
https://kyuubi.apache.org/
Kyuubi 仓库:
https://github.com/apache/incubator-kyuubi
互联网企业给被裁员工发“毕业须知”;孟晚舟担任华为轮值董事长;腾讯员工被曝偷看创业公司工作文档 | Q资讯
腾讯回应裁员;小米辞退绩效考核分数低员工终审败诉;GitHub 频繁宕机原因:MySQL 负载过重 | Q资讯
活动推荐
长期征集|寻找中国卓越技术团队
2022 年第一季《中国卓越技术团队访谈录》即将上线,本期精选了包括腾讯云鼎实验室、优麒麟、PingCAP、西门子 Mendix、火山引擎 ByteHouse、搜狗输入法无障碍产品在内的优秀团队,敬请关注。同时,访谈录现开放长期报名通道,如果你身处传统企业经历了数字化转型变革,或者正在互联网公司进行创新技术的研发,并希望 InfoQ 可以关注和采访你所在的技术团队,就请抓住机会吧!

点个在看少个 bug 👇