造假色情视频PK“保护老实人”的原谅宝:谁赢?
▲点击上方 雷锋网 关注


“原谅宝”有多少功力不好说,但 Deepfake 的假视频确实可以被揪出来。
文 | 李勤
第一件事是,自从 AI 换脸神器 Deepfake 走红后, 有一种声音是,如果你讨厌一个人,就收集他的照片,用 Deepfake 技术与色情片演员换脸,伪造色情视频传播,印度记者 Rana Ayyub 就因为揭露了印度古吉拉特暴乱中官员的黑幕而被“色情复仇”。
第二件事是,微博用户@将记忆深埋表示,自己通过半年时间,比对了国内外色情网站和社交媒体的数据,在全球范围内成功识别了 10 多万从事不可描述行业的小姐姐。查询系统可以对美颜、 Deepfake 换脸等有效对抗,并加上步态分析、声纹识别和其他身体特征,识别率达到 99%。
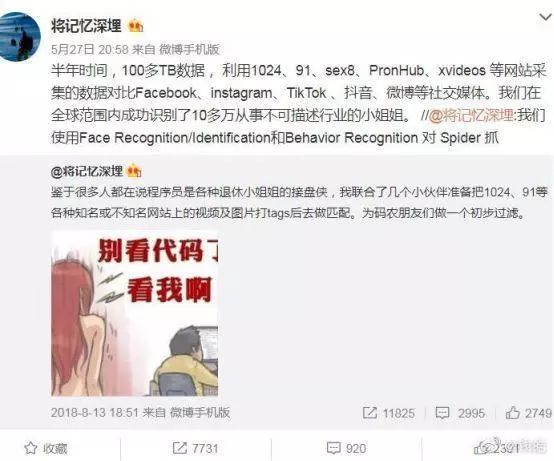
该微博用户后来在网友的声讨下表示不会开放 API 或查询页面,也不公布论文或开源算法,并删除了整个项目和数据库。
这两起事件放在一起看,有点细思恐极。
虽然这个被网友戏称为“原谅宝”的“准商业产品”已经凉凉,也有人辟谣称这种产品其实无法达到比对的准确率——99%(视频)和100%(声纹),但是宅客频道还是关心两个问题。
第一,这种“产品”打造的门槛高吗?
第二,“原谅宝”真的可以对抗 Deepfake 吗?
说起来这个原谅宝的运行路径很简单,一般先用爬虫不停发现色情网站上的新链接,对公开图片和视频进行爬取。然后进行人脸检测,抽取其中带有人脸的图片,抽取人脸相关的特征,并建立索引。如果是视频的话,则需要抽取关键帧再进行特征抽取和索引。在用户提交图片进行搜索时,对所提交的图片同样进行人脸检测、特征抽取,将特征在预先建立的索引中进行搜索排序。
于是,编辑找到了两位关键专家:某大厂 AI 安全专家 Dou 以及提供反爬虫业务的邦盛科技公司网络自动化攻防专家许俊杰。
首先,上述新浪微博用户爬到的“100 多 TB 的数据”获取似乎真的很容易。简单来说,“只要你公开持有,我就能爬到”。
许俊杰说,这些数据应该就是爬网页得到,只要人可以看到,爬虫就能爬到,特别是那些页面是简单的分页,直接一页页爬取,非常方便。但是,对于数据库,一般人是爬不到的,除非攻击者利用黑客手段攻破了网站服务器。
Dou 表示,获取数据后,比对图片、视频很简单,目前开源的 OpenCV 都可以胜任这个工作。
有人提出,有很多偷拍的色情视频比较模糊,识别起来有点困难。
确实,不仅是视频,对于模糊的照片,人脸识别软件也会遭遇困难。但是在 Dou 看来,该微博用户提到的目标网站中的色情视频质量其实尚可,而且人脸识别并比对时,主流算法是被人脸提取特征后形成一百到几百维的向量,“图像质量不用太好”。
相对而言,识别换脸则复杂一些,需要积累数据,训练模型。
这就来到了第二个问题,原谅宝真的可以对抗 Deepfake 吗?
毕竟 Deepfake 换脸后,相似度 86% 的假尼古拉斯凯奇和 70.5% 的假美国总统居然都骗过了亚马逊和微软的人脸识别服务。

简单粗暴地先下一个结论:“原谅宝”有多少功力不好说,但 Deepfake 的假视频确实可以被揪出来。
5 月底,在那场盛大的世界著名极客大会DEF CON CHINA 1.0 上,一名来自百度的安全研究员Wangyang介绍了 AI 换脸检测的方法。
先来看看 Deepfake 的 AI 换脸视频是怎样制作的?
出人意料的是,它并不是利用 A 图像整体替换 B 图像,而是将视频抽取每一帧,找到目标人脸换脸,再放回到人脸原来的位置,它所伪造的人脸是人脸的中心区域。
Deepfake 有两组自动编码器,每组含有一个编码器和一个解码器,自动编码器会将图片降维表示,解码器会对图片进行解码,恢复到原图。在训练过程中,需要保持输入的图片和输出的图片差异尽量小。这两组编码器分别对两个人进行编码和解码,这两组自动编码器的编码器共享权重。
“在训练过程中,我们需要这两个人的多张图片分别训练两组编码器。这样在转换时,A 人脸可以通过B 的编码器还原成 B 人脸,同样,B 人脸也可以被解码成 A 人脸。在转换的过程中,先使用人脸检测系统找到对应的人脸,输入到编码器,然后通过另一组解码器得到伪造的人脸,再放回原图,然后进行融合。”Wangyang 说。
研究人员提出了两种检测方法。
第一种检测基于卷积神经网络(CNN)达成。
通过 CNN 分类是目前进行图片分类的一种主流方式,研究人员使用了一种浅层的 CNN,试图让它抓住比较低层次的图像特征。目前来看,Deepfake 产生的假脸会有一些容易被发现的痕迹,比如边缘生硬,视频中人脸会有抖动、人脸扭曲、颜色不均等。
利用人脸检测器找到人脸的核心区域,然后进行外延,这样输入的模型就包含了融合边缘的信息,一辩知真假。
Wangyang 称:“我们的数据集是开源的,从视频中提取了六万多张假脸图片和六万多张真脸图片,图片质量参差不齐。用人脸检测找到人脸的核心区域之后,可以得到 1.5 倍的人脸框图。训练时,我们还进行了数据增强,将它进行缩放等,识别准确率能达到 99%,真脸很少会被识别成假脸。”
第二种方法则基于人脸识别模型识别。
FaceNet 是目前是最流行的开源人脸识别框架之一。它是一个典型的深度 CNN,FaceNet 会对输入的人脸进行映射,把输入图片映射为 512 维的向量。FaceNet 在进行两张人脸比对时,实际上是计算这两个人脸对应向量的距离,比如数值越少,这两张脸越相似。
这个方法使用的数据集和刚才介绍的方法类似,区别在于,研究人员使用的图片仅是人脸的核心区域。通过 FaceNet 提取的向量作为训练模型的特征,用 SVM 作为二分类器,FaceNet 作为特征提取器,“这种利用更高层次的抽象人脸比对的方法准确率能达到 94%”。
◆ ◆ ◆
推荐阅读
谷歌游说美政府解除华为Android禁令;搜狐加入社交大战推出狐友;库克:中国封杀苹果事件不会发生
智能手表eSIM化,走向独立人格的第一步
解读 | 苹果推出 iPadOS 的真正用意是什么?
10件5G能实现但4G不能做的事情
5G商用牌照将正式发放;中国邮政与华为合作;苹果在华成立首个App设计开发加速器
CCF-GAIR 2019
由中国计算机学会主办、雷锋网和香港中文大学(深圳)联合承办的 2019 全球人工智能与机器人峰会,将于 2019 年 7 月 12 日至 14 日在深圳举行。届时,诺贝尔奖得主JamesJ. Heckman、中外院士、世界顶会主席、知名Fellow,多位重磅嘉宾将亲自坐阵,一起探讨人工智能和机器人领域学、产、投等复杂的生存态势。