将文本转语音速度提高38倍,这个FastSpeech真的很fast
选自arXiv
作者:Yi Ren、Yangjun Ruan、Xu Tan、Tao Qin、Sheng Zhao、Zhou Zhao、Tie-Yan Liu
机器之心编译
参与:胡曦月、张倩
基于神经网络的端到端文本语音转换(TTS)显著改善了合成语音的质量,但存在推理速度慢、合成语音不稳健等问题。在本文中,来自浙大和微软的研究者提出了一种基于 Transformer 的新型前馈网络,用于为 TTS 并行生成梅尔频谱。在 LJSpeech 数据集上的实验表明,本文的并行模型在语音质量方面达到了自回归模型的水平,而且与自回归 Transformer TTS 相比,本文的模型可以将梅尔频谱生成速度提高 270 倍,将端到端语音合成速度提高 38 倍。
基于神经网络的端到端文本语音转换(TTS)显著改善了合成语音的质量。一些主要方法(如 Tacotron 2)通常首先从文本生成梅尔频谱(mel-spectrogram),然后使用诸如 WaveNet 的声码器从梅尔频谱合成语音。
与基于连接和统计参数的传统方法相比,基于神经网络的端到端模型有一些不足之处,包括推理速度较慢,合成语音不稳健(即某些词被跳过或重复),且缺乏可控性(语音速度或韵律控制)。
本文提出了一种基于 Transformer 的新型前馈网络,用于为 TTS 并行生成梅尔频谱。具体来说就是,从基于编码器-解码器的教师模型中提取注意力对齐(attention alignments),用于做音素(phoneme)持续时间预测。长度调节器利用这一预测来扩展源音素序列,以匹配目标梅尔频谱序列的长度,从而并行生成梅尔频谱。
在 LJSpeech 数据集上的实验表明,本文的并行模型在语音质量方面达到了自回归模型的水平,基本上消除了复杂情况下的单词跳过和重复的问题,并且可以平滑地调整语音速度。最重要的是,与自回归 Transformer TTS 相比,本文的模型可以将梅尔频谱生成速度提高 270 倍,因此,研究者将该模型命名为 FastSpeech 模型。代码将在论文发表后发布于 GitHub 上。

基于神经网络的端到端 TTS 模型存在哪些问题?
当前基于神经网络的 TTS 系统中,梅尔频谱是自回归地生成的。由于梅尔频谱的长序列和自回归性质,这些系统面临着如下挑战:
产生梅尔频谱的推理速度慢。虽然 CNN 和基于 Transformer 的 TTS 可以加速对 RNN 模型的训练,但所有模型都以先前生成的梅尔频谱为条件来生成新的梅尔频谱,并且由于梅尔频谱序列长度成百上千,推理速度会因此变慢。
合成语音不稳健。由于自回归生成时的误差传播以及文本和语音之间错误的注意力对齐,所生成的梅尔频谱往往存在单词跳过和重复的问题。
合成语音缺乏可控性。以前的自回归模型会自动逐个生成梅尔频谱,而不会明确地利用文本和语音之间的对齐。因此,通常很难直接控制自回归生成中的语音速度和韵律。
本文解决方案
考虑到文本和语音之间的单调对齐,为了加速生成梅尔频谱,本文提出的新模型 FastSpeech 采用基于 Transformer 和一维卷积中自注意力机制的前馈网络,以文本(音素)序列作为输入,生成非自回归的梅尔频谱。
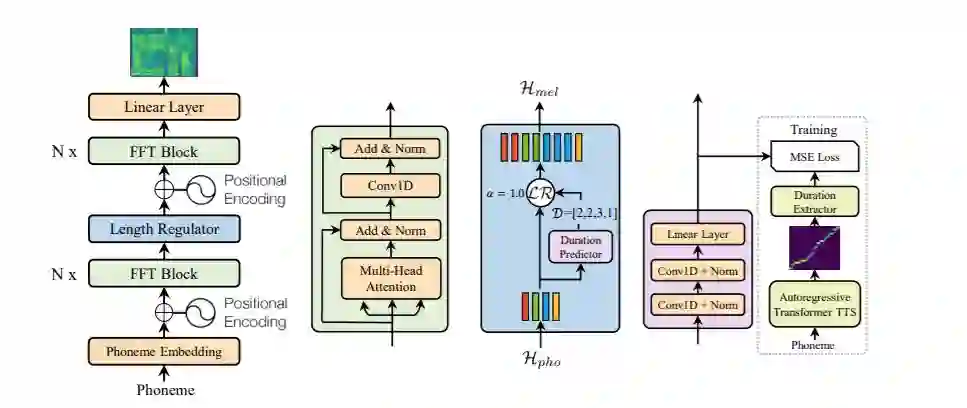
图 1:FastSpeech 的整体架构。a. 前馈 Transformer。b. 前馈 Transformer 模块。c. 长度调节器。d. 持续时间预测器。MSE 损失表示仅存在于训练过程中的预测和提取持续时间之间的损失。
本文提出的 FastSpeech 可以解决上述三个挑战:
通过并行生成梅尔频谱,FastSpeech 大大加快了合成过程。
与自回归模型中的自动注意力软对齐非常不同的是,音素持续时间预测器确保音素与其梅尔频谱之间的硬对齐,从而可以使 FastSpeech 避免错误传播和错误注意对齐的问题,减少单词跳过和重复单词的比例。
长度调节器可以通过延长或缩短音素持续时间来轻松调节语音速度,以确定生成的梅尔频谱的长度,此外还可以通过在相邻音素之间添加间隔来控制部分韵律。
FastSpeech 模型在 LJSpeech 数据集上进行的实验结果表明,在语音质量方面,FastSpeech 几乎达到了自回归 Transformer 模型的水平。此外,与自回归 Transformer TTS 模型相比,FastSpeech 在梅尔频谱生成时速度提高 270 倍,在最终语音合成时速度提高 38 倍,几乎消除了单词跳过和重复的问题,并且可以平滑地调整语音速度。
前馈 Transformer
如图 1a 所示,FastSpeech 的架构是基于 Transformer 和一维卷积中自注意力机制的前馈结构,称之为为前馈 Transformer(FFT)。前馈 Transformer 将多个 FFT 块堆叠以进行音素到梅尔频谱的变换,其中音素侧有 N 个块,梅尔频谱侧有 N 个块,长度调节器(将在下一小节中介绍)介于两者之间,用于弥合音素和梅尔频谱序列之间的长度差距。如图 1b 所示,每个 FFT 块由一个自注意力结构和一个一维卷积网络组成。自注意力网络由多头注意力提取交叉位置信息。与 Transformer 中的 2 层密集网络不同,由于在语音任务中的字符/音素和梅尔频谱序列中,相邻的隐藏状态更紧密相关,因此本文使用具有 ReLU 激活函数的 2 层一维卷积网络。文章在实验部分评估了一维卷积网络的有效性。在 Transformer 之后,分别在自注意力网络和一维卷积网络之后添加了残差连接、层归一化和 dropout。
长度调节器
长度调节器(图 1c)用于解决前馈 Transformer 中音素和频谱图序列之间长度不匹配的问题,此外还可以用于控制语音速度和韵律。音素序列长度通常小于其梅尔频谱序列的长度,并且每个音素对应于多个梅尔频谱。本文将对应于某音素的梅尔频谱长度称为音素持续时间(论文将在下一小节中描述如何预测音素持续时间)。基于音素持续时间 d,长度调节器将音素序列的隐藏状态扩展 d 倍,从而使得隐藏状态的总长度等于梅尔频谱的长度。将音素序列的隐藏状态表示为 Hpho = [h_1,h_2,...,h_n],其中 n 是序列的长度。将音素持续时间序列表示为 D = [d_1,d_2,...,d_n],其中 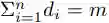

其中,α 是一个用于确定扩展序列 Hmel 长度的超参数,从而控制语音速度。
持续时间预测器
音素持续时间预测对于长度调节器很重要。如图 1d 所示,持续时间预测器由具有 ReLU 激活函数的 2 层一维卷积网络组成,每个网络后都加上层归一化、dropout,以及用于输出标量的额外线性层,该标量正是预测的音素持续时间。请注意,此模块堆叠在音素侧的 FFT 块之上,并使用均方误差损失(MSE)与 FastSpeech 模型共同训练,以预测每个音素的梅尔频谱的长度。研究者在对数域中预测长度,使其更加符合高斯分布,并且更容易训练。请注意,训练好的持续时间预测器仅用于 TTS 推理阶段,因为我们可以直接使用从训练中的自回归教师模型中提取的音素持续时间(参见下面的讨论)。如图 1d 所示,为了训练持续时间预测器,本文从自回归教师 TTS 模型中提取真实音素持续时间。
实验设置
训练和推理
研究者首先在 4 个 NVIDIA V100 GPU 上训练自回归 Transformer TTS 模型,其中每个 GPU 上运行一个 batch,每个 batch 包含 16 个句子。本文使用 Adam 优化,其中β_1= 0.9,β_2= 0.98,ε= 10^(-9),学习率与[22]相同。训练至收敛需要 80k 步。然后再次将训练集中的文本-语音对输入模型以获得用于训练持续时间预测器的编码器 - 解码器注意力对齐。此外,本文还利用 5 个序列级知识精馏,在将知识从教师模型转移到学生模型的非自回归机器翻译中取得了良好的表现。对于每个源文本序列,本文使用自回归 Transformer TTS 模型生成梅尔频谱,并将源文本和生成的梅尔频谱作为 FastSpeech 模型训练的成对训练数据。
本文将 FastSpeech 模型与持续时间预测器一起训练,其优化器选择和其他超参数与自回归 Transformer TTS 模型相同。为了加快训练过程并提高性能,研究者从自回归 Transformer TTS 模型初始化了部分权重:1)初始化自回归 Transformer TTS 模型的音素嵌入; 2)由于共享相同的架构,研究者使用自回归 Transformer TTS 模型的编码器在音素侧初始化 FFT 块。在 4 个 NVIDIA V100 GPU 上训练 FastSpeech 模型大约需要 80k 步。在推理过程中,使用预训练的 WaveGlow 将 FastSpeech 模型的输出梅尔频谱转换为音频样本。
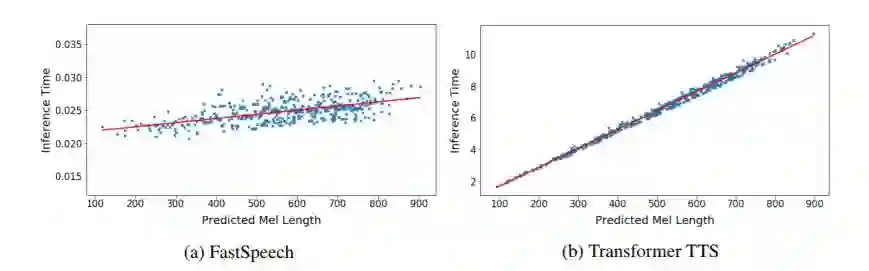
图 2:FastSpeech 和 Transformer TTS 的推理时间(秒)与梅尔频谱长度对比。
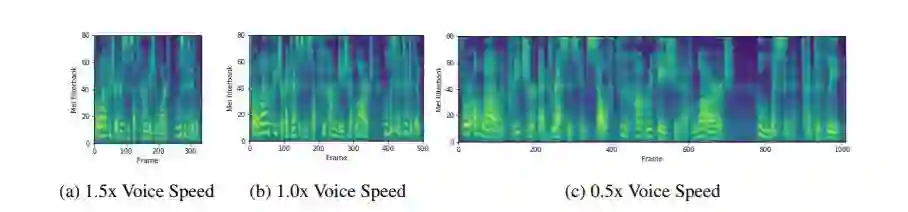
图 3:分别为 1.5x、1.0x 和 0.5x 倍速的语音梅尔频谱。输入文本是「For a while the preacher addresses himself to the congregation at large, who listen attentively」。
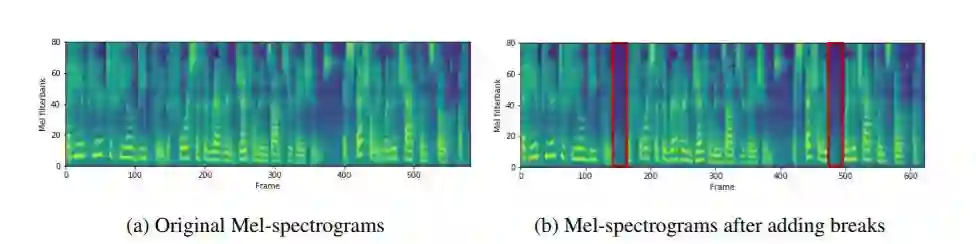
图 4:在单词之间添加中断之前和之后的梅尔频谱。对应的文本是「that he appeared to feel deeply the force of the reverend gentleman』s observations, especially when the chaplain spoke of」。在「deeply」和「especially」之后添加了中断以改善韵律。图 4b 中的红色框对应于添加的中断。

表 3:FastSpeech 和 Transformer TTS 在 50 个特别难的句子上的稳健性比较。每种单词错误在一个句子中最多计算一次。

论文链接:https://arxiv.org/pdf/1905.09263.pdf
本文为机器之心编译,转载请联系本公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者 / 实习生):hr@jiqizhixin.com
投稿或寻求报道:content@jiqizhixin.com
广告 & 商务合作:bd@jiqizhixin.com




