第一次接触 Kaggle 入门经典项目泰坦尼克号就斩获前 1%,他做了什么?




* Photo by Willian Justen de Vasconcellos on Unsplash
你不需要重新发明轮子,你需要知道如何使用现有的轮子更好地完成你想做的事情。
由 Kaggle 主办的泰坦尼克号挑战赛是一场比赛,其目标是根据一组描述某位乘客的变量(如年龄、性别或船上乘客等级)来预测该乘客的生死。
我玩泰坦尼克号的数据已经有一段时间了。在写这篇文章的时候,我在 11002 名参与者中排名第 113 位。
你一定想知道我是怎么做到的。所以我们就直接切入主题吧。
泰坦尼克号的沉没是历史上最著名的沉船事件之一。1912 年 4 月 15 日,泰坦尼克号在处女航中与冰山相撞后沉没,2224 名乘客和船员中有 1502 人遇难。这一耸人听闻的悲剧震惊了国际社会。
沉船事故导致如此多人丧生的原因之一是没有足够的救生艇供乘客和船员使用。虽然在沉船事件中幸存下来有一些运气因素,但有些人比其他人,更有可能幸存下来,如妇女、儿童和上层阶级。
-
scikit-learn
numpy
pandas
matplotlib
seaborn
数据集可以从 kaggle 网站下载到(https://www.kaggle.com/c/titanic/data)。
关于 github 的完整项目可以在这里找到。
以下是数据集中提供的特征。
-
Passenger Id:船上每位旅客的身份编号
-
Pclass:客舱等级,它有三个可能的值:1,2,3(一等、二等、三等)
-
The Name of the passenger :乘客姓名
-
Sex:性别
-
Age:年龄
-
SibSp:与乘客同行的兄弟姐妹和配偶人数
-
Parch:与乘客同行的父母和儿童人数
-
The ticket number :票号
-
The ticket fare:票价
-
The cabin number :船舱号
-
The embarkation:这描述了泰坦尼克号上三个区域,人们从这些区域出发。其三个可能值为 S,C,Q
我从导入所有库和依赖项开始。
接下来我加载了包含所有细节的 csv 文件。

这可能是机器学习工作流中最重要的部分。由于算法完全取决于我们如何输入数据,因此特征工程应该是每个机器学习项目的首要任务。
特征工程是将原始数据转换为能更好地将潜在问题表示为预测模型特征的过程,从而提高模型对未知数据预测的精度。
减少过拟合:更少的冗余数据意味着做出基于噪音的决策的概率更小。
提高准确性:更少的误导性数据意味着建模精度提高。
减少训练时间:更少的数据点降低算法复杂度,使得算法训练更快。
我创建了一些特征,用于判断乘客是否有客舱,计算家庭规模,以及判断一个人是否独自旅行。另外,我做了一些数据清洗,比如从数据集中删除空值。
我继续进行特征工程,创建一个函数来获得一个人的头衔。此外,我把所有不常用的列数据归为一组。然后我根据以下几个特征对人们进行了分类——sex, title, embarked, fare 和 age。
然后我删除了一些列,如 PassengerId, name, ticket, cabin, sibSp,因为这些值对我们的预测看起来并不重要。
接下来,我制作了一个混淆矩阵来可视化不同特征之间的相互关系。
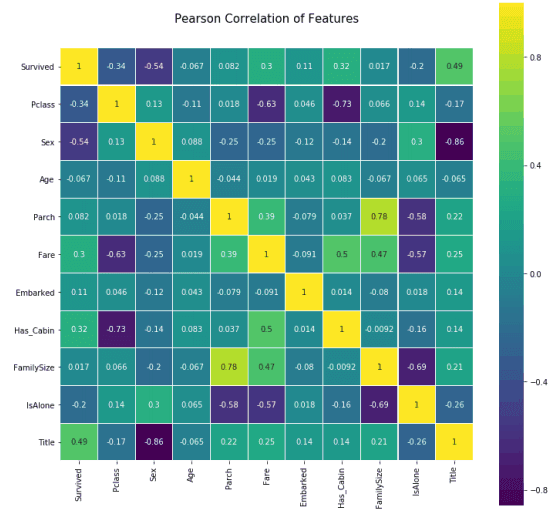
混淆矩阵
到现在为止,一直都还不错。我继续创建一个名为 title 的特征。另外,我将 Sex 映射为一个二进制特征,并创建了一个按标题分组的 Sex 分布表。
我使用决策树作为机器学习模型。我使用一个自定义的特征计算了基尼不纯度分数,以优化树节点。这个自定义特征被定义为幸存的人数在总登船人数中的占比。
我用这个超参数玩了一段时间,直到得到满意的结果。
在最后一部分,我使用了十个切分的 k-fold 交叉验证模型。在 k 重交叉验证中,数据被划分为 k 个子集。现在,holdout 方法被重复 k 次,这样每次其中一个 k 子集被用作验证集,而另一个 k-1 子集被组合在一起形成训练集。当我们使用大多数数据进行拟合时,会显著地减少偏差,同时也显著地减少方差,因为大多数数据也在验证集中使用。
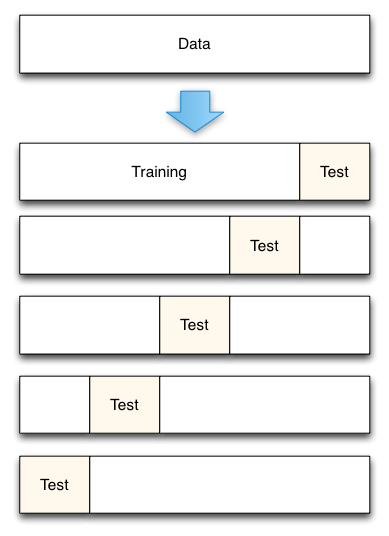
当K=5时,进行交叉验证
此步骤用于检查模型是否过拟合。过拟合是指对训练集上的数据建模得太好的模型。这种模型不适用于新数据,过拟合会对模型的泛化能力产生负面影响。
过拟合就像学校里的学生记忆概念而加理解。
最后,在决策树中的深度是不同的,让我们看看模型的准确性。
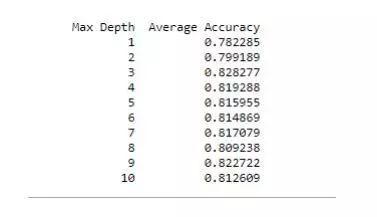
我认为,对于一个正在踏上数据科学/机器学习之旅的人来说,这场比赛是一个很好的起点。一个人可以玩不同的分类模型,如 logistic 回归,随机森林,朴素贝叶斯,支持向量机等。这场比赛应该是一个很好的试验台,你还可以尝试一些更复杂的算法,如 xgboost,自动编码,梯度增强,神经网络或以上算法的集合。
相应的源代码可以在这里找到:
https://github.com/abhinavsagar/Kaggle-Titanic-Solution

当然,如果同学们已经学过这个经典项目了,需要进一步提高怎么办?为满足大家的需求,AI 研习社最新上线了一个有趣的比赛——英文垃圾信息分类挑战赛!
参赛地址:https://god.yanxishe.com/11
扫码即可报名参赛,PC访问更佳!



大赛简介
数据集
本次比赛数据来源于 SMS Spam Collection(http://www.dt.fee.unicamp.br/~tiago//smsspamcollection/),感谢新加坡国立大学靳民彦教授对本次比赛提供的支持!
在这个数据集中,训练集共3450条数据,测试集1672。
数据集下载链接:https://dwz.cn/NaPIpNg7 。
比赛任务
正确识别测试集样本数是否为垃圾信息(0是正常短信,1是垃圾短信)。
比赛奖金
本次比赛共设置3种奖项,奖金将在比赛后提现时发放到微信零钱。
金额:占总奖金的30%;
获奖人数:所有人(每人仅能获得一次参与奖);
获奖条件:提交结果大于标准分,标准分=90;
R为得分区间系数,R1(0.45)、R2(0.2)、R3(0.15)、R4(0.12)、R5(0.08);
money为已经发放的参与奖奖金;
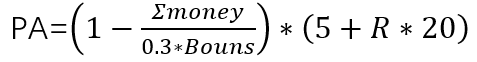
2.突破奖(Prizes)
金额:占总奖金20%;
获奖人数:所有人;
score为参数选手得分,N表示第N次更新排行榜;Prizes_N-1表示:排行榜更新后已发放的突破奖金。
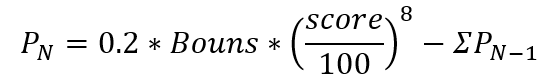
3.排名奖(Ranking Award)
金额:占总奖金50%;
获奖人数:得分前5名
T为奖金时间系数,比赛上线第一周、一个月,T(周)=0.5,T(月)=0.5;
K为排名奖金分配系数,前5名分配系数分别为0.45、0.2、0.15、0.12、0.08;
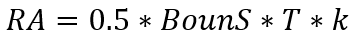
评审标准
我们将会对比选手提交的csv文件,确认正确识别短信数据:
True:模型分类正确数量
Total :测试集样本总数量
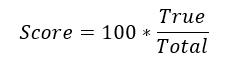
参赛条件
欢迎所有在校学生、在职工程师和AI爱好者参赛!欢迎扫码或点击底部 阅读原文 访问相关页面,查看比赛详情~
编译来源:https://towardsdatascience.com/how-i-scored-in-the-top-1-of-kaggles-titanic-machine-learning-challenge-7716386ba298

 扫码查看收藏
扫码查看收藏







