近日,百度在多模态语义理解领域取得突破,提出知识增强视觉-语言预训练模型 ERNIE-ViL,首次将场景图(Scene Graph)知识融入多模态预训练,在 5 项多模态任务上刷新世界最好效果,并在多模态领域权威榜单 VCR 上超越微软、谷歌、Facebook 等机构,登顶榜首。此次突破充分借助飞桨深度学习平台分布式训练领先优势。
据机器之心了解,基于飞桨实现的 ERNIE-ViL 模型也将于近期开源。
多模态语义理解是人工智能领域重要研究方向之一,如何让机器像人类一样具备理解和思考的能力,需要融合语言、语音、视觉等多模态的信息。
近年来,视觉、语言、语音等单模态语义理解技术取得了重大进展。但更多的人工智能真实场景实质上同时涉及到多个模态的信息。例如,理想的人工智能助手需要根据语言、语音、动作等多模态的信息与人类进行交流,这就要求机器具备多模态语义理解能力。
近日,百度在该领域取得突破,提出业界首个融合场景图知识的多模态预训练模型 ERNIE-ViL。百度研究者将场景图知识融入到视觉-语言模型的预训练过程,学习场景语义的联合表示,显著增强了跨模态的语义理解能力。ERNIE-ViL 还在包括视觉常识推理、视觉问答、引用表达式理解、跨模态图像检索、跨模态文本检索等 5 项典型多模态任务中刷新了世界最好效果。并在多模态领域权威榜单视觉常识推理任务(VCR)上登顶榜首。
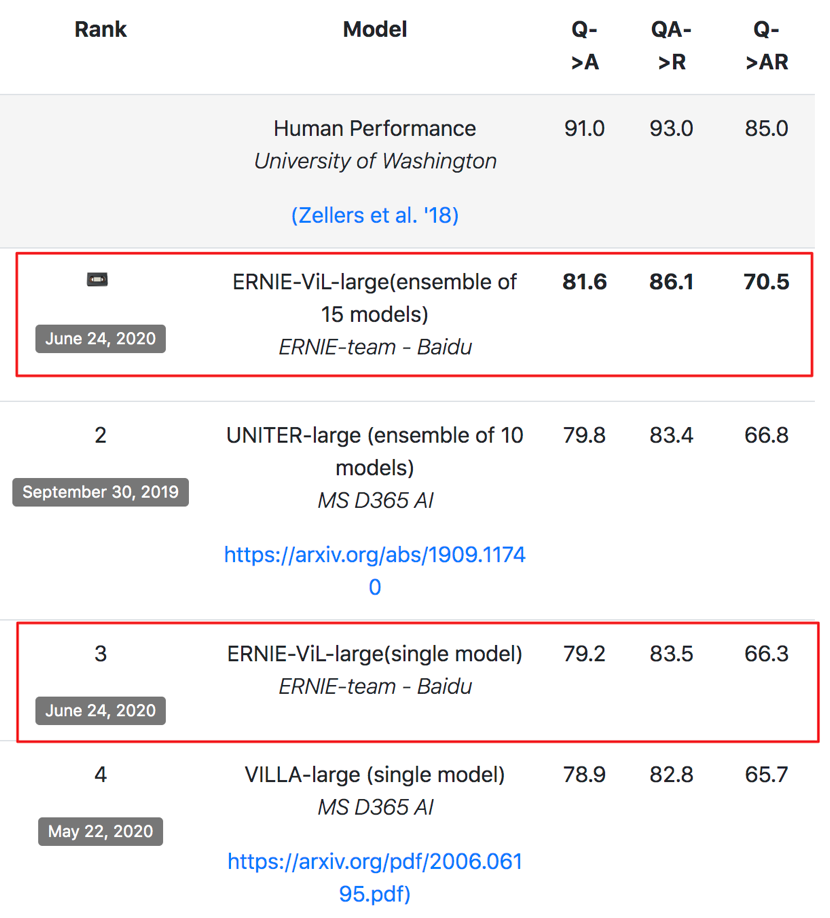
![]()
VCR Leaderboard 最新版。子任务一:Q->A(Question Answering)。子任务二:QA→R(Answer Justification)。综合得分:Q→AR:模型的综合表现(两个子任务都对才得分)。
上小学的时候,“看图说话”在语文试卷中常年占据着一席之地。比如给出下面这张图,让我们描述图里的人物在干什么、想什么、有着怎样的心情。
![]()
同样,在人工智能领域,机器也需要具备“看图说话” 的能力。
如下边这张图,出题人问:“右边的那个人是如何获得她面前的钱的?”进一步还要回答 “你为什么做出这样的推断?” 也就是说,模型不仅需要识别出图像中的物体 “人”、“乐器”、“硬币”,还需要对它们的关系 “人演奏乐器” 等进行理解,并通过 “街头表演挣钱” 这样的常识进行推理。
![]()
VCR(Visual Commonsense Reasoning,视觉常识推理)就是由十几万这样的图片和问题组成的数据集。该数据集由华盛顿大学和艾伦人工智能研究所的研究者联合创建,考查的是模型的多模态语义理解与推理能力。
微软、谷歌、Facebook 等科技公司及 UCLA、佐治亚理工学院等顶尖高校都对该任务发起了挑战。
6 月 24 号,该榜单被再次刷新,来自百度 ERNIE 团队的 ERNIE-ViL 在单模型效果和多模型效果上都取得了第一的成绩,并在联合任务上以准确率领先榜单第二名 3.7 个百分点的成绩登顶,超越了微软、谷歌、Facebook 等机构。
![]()
当人们看到上面这张图的时候,首先会关注图中的物体(Objects)以及特点属性(Attributes)和期间的关系(Relationships)。如:“车”、 “人”、“猫”、“房屋” 等物体构成了图片场景中的基本元素;而物体的属性,如:“猫是白的”,“汽车是棕色的” 则对物体做了更精细的刻画;物体间的位置和语义关系,如:“猫在车上”,“车在房屋前” 等,建立了场景中的物体的关联。因此,物体、属性和关系共同构成了描述视觉场景的细粒度语义(Detailed Semantics)。
基于此观察,百度的研究者将包含场景先验知识的场景图(Scene Graph)融入到多模态预训练过程中,建模了视觉-语言模态之间的细粒度语义关联,学习到包含细粒度语义对齐信息的联合表示。
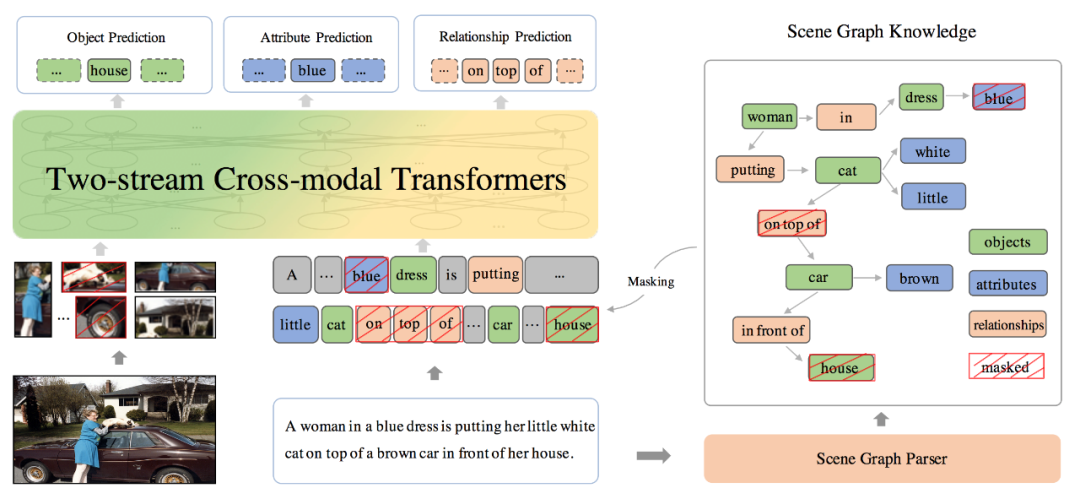
如下图所示,基于文本中解析出的场景图,ERNIE-ViL 提出了三个多模态预训练的场景图预测(Scene Graph Prediction)任务:物体预测(Object Prediction)、属性预测(Attribute Prediction)、关系预测(Relationship Prediction)。
物体预测:随机选取图中的一部分物体,如图中的“house”,对其在句子中对应的词进行掩码,模型根据文本上下文和图片对被掩码的部分进行预测;
属性预测:对于场景图中的属性 - 物体对,如图中的“<dress, blue>”,随机选取一部分词对其中的属性进行掩码,根据物体和上下文和图片对其进行预测;
关系预测:随机选取一部分 “物体 - 关系 - 物体” 三元组,如图的“<cat, on top of, car >”,然后对其中的关系进行掩码,模型根据对应的物体和上下文和图片对其进行预测。
![]()
通过场景图预测任务,ERNIE-ViL 学习到跨模态之间的细粒度语义对齐,如将语言中 “猫”、“车是棕色的”、“猫在车上” 等语义信息对应到图像中相应的区域。
除以上提出的场景图预测的任务外,ERNIE-ViL 的预训练还使用了掩码语言模型(Masked Language Modelling)、掩码图像区域预测(Masked Region Prediction)、图文对齐(Image-Text Matching)等任务。
研究者通过视觉常识推理、视觉问答等多模态下游任务,对 ERNIE-ViL 的模型能力进行了验证。
除了在视觉常识推理任务上取得 SOTA 之外,ERNIE-ViL 在视觉问答、跨模态图片检索、跨模态文本检索、引用表达式理解等任务上也刷新了 SOTA 结果。
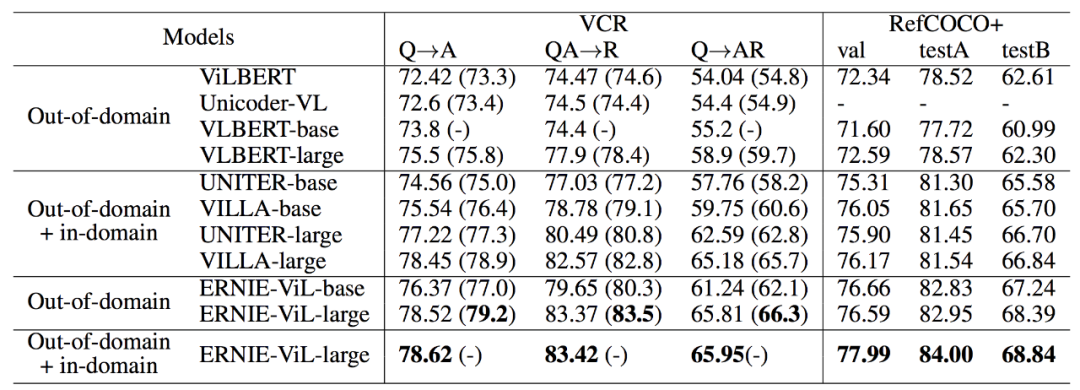
引用表达式理解
(Referring Expressions Comprehension, RefCOCO+)任务是给定一段自然语言描述,图像中定位到相关的区域,该任务涉及到细粒度的跨模态语义对齐(自然语言短语与图像区域),因此更加考查联合表示对语义刻画的精细程度,ERNIE-ViL 在该任务的两个测试集上(testA、testB)对比当前最优效果均提升了 2.0 个百分点以上。
![]()
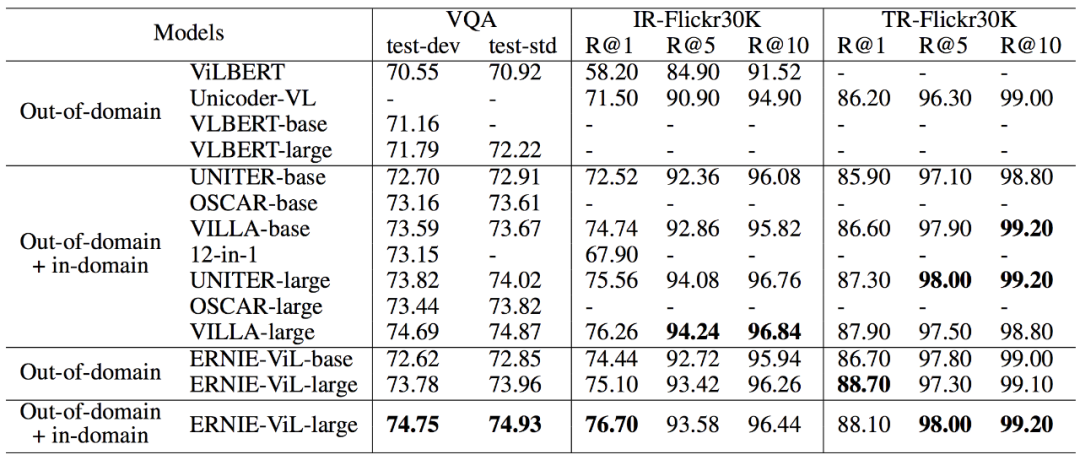
视觉问答
(Visual Question Answering,VQA)任务是给定一个图片以及文本描述的问题,要求模型给出答案。该任务需要对文本和图像进行更深入的理解和推理,同时该任务里的问题涉及细粒度的语义(物体、物体属性、物体间关系),能够检验模型对于场景的理解深度。ERNIE-ViL 在该任务上以 74.93% 的得分取得了单模型的最好成绩。
跨模态图像 & 文本检索
(Cross-modal Image-Retrieval,IR; Cross-modal Text-Retrieval,TR)任务是多模态领域的经典任务,给定图像检索相关的文本以及给定文本检索相关的图像。该任务实质上是计算图像模态和文本模态在语义上的相似度,要求模型同时兼顾整体语义和细粒度语义。ERNIE-ViL 在这两个任务上分别以 R@1 提升 0.56 个百分点和 0.2 个百分点的结果刷新了 SOTA。
![]()
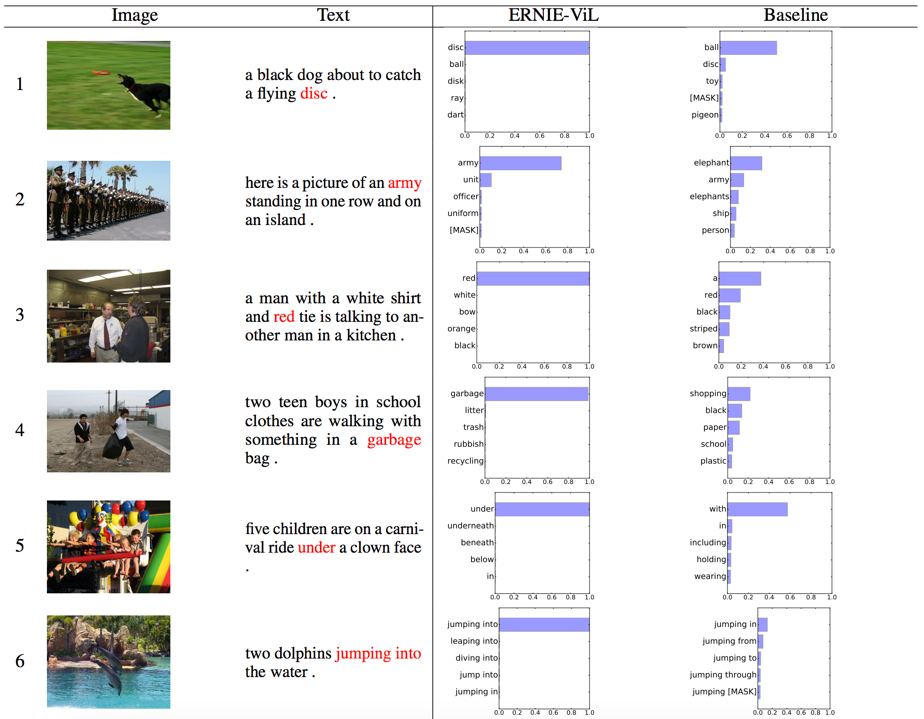
百度研究者通过构建多模态完形填空测试实验,验证了 ERNIE-ViL 更强的跨模态知识推断能力:给定一组图片 - 文本对齐数据,分别将文本中的物体、关系或属性词掩码,让模型根据上下文和图片进行预测。实验表明,在对文中表述细粒度语义的词(物体、属性、关系)进行预测时,ERNIE-ViL 表现更为优越,准确率分别提升 2.12%、1.31% 和 6.00%。
![]()
同时,论文中给出了完形填空测试的若干实例,从下图中可以看出,ERNIE-ViL 往往能够更精确地预测出被掩码的物体、属性和关系,而基线模型往往只能预测出原有词的词性,但是很难准确预测出具体的词。
![]()
听懂、看懂、理解环境是人工智能的重要目标之一,实现该目标的首要任务是让机器具备多模态语义理解能力。此次百度提出的知识增强多模态模型 ERNIE-ViL,首次将场景图知识融入多模态模型的预训练过程,在视觉问答、视觉常识推理等 5 个任务上刷新纪录,为多模态语义理解领域研究提供了新的思路。除了上述公开数据集效果突破外,ERNIE-ViL 技术也逐步在真实工业应用场景中落地。未来百度将在该领域进行更深入的研究和应用,使其发挥更大的商业和社会价值。
7月11日09:00-12:00,机器之心联合百度在WAIC 2020云端峰会上组织「开发者日百度公开课」,为广大开发者提供 3 小时极致学习机会,从 NLP、CV 到零门槛 AI 开发平台 EasyDL,助力开发者掌握人工智能开发技能。扫描图中二维码,加机器之心小助手微信邀您入群。
![]()