伯克利Roshan Rao 157页博士论文:训练,评估和理解蛋白质序列的进化模型
最近,伯克利大学Roshan Rao 157页博士论文介绍了在通用基准上训练和评估蛋白质语言模型的方法。随后,研究了模型缩放、数据预处理和训练超参数对transformer在无监督的情况下学习蛋白质接触能力的影响,然后提出了一种在MSA上操作而不是在单个序列上操作的新方法,并证明了该方法在多个下游任务上实现了最优的性能。最后,讨论了所有这些方法在蛋白质设计中的应用。

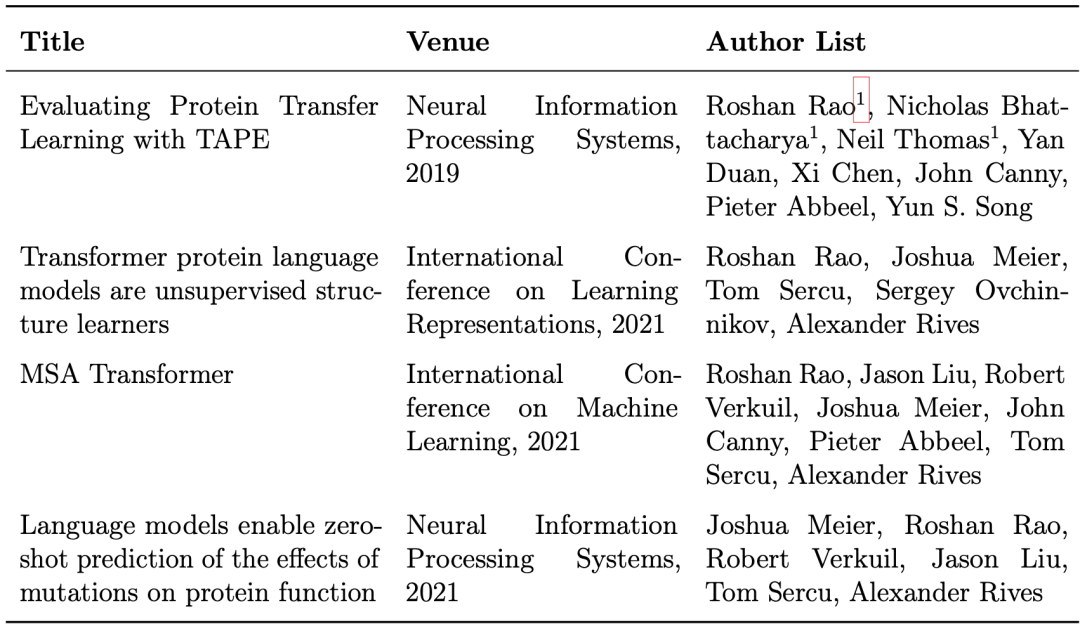
作者在蛋白质序列模型方面做了很多工作:
油管视频:
作者博士论文试图回答了以下三个问题:
在NLP中标准的无监督学习方法是否可以学习到生物学相关特征?
第二章“评估TAPE蛋白质语言模型”试图回答这个问题,为熟悉机器学习的读者介绍了多序列比对和典型的蛋白质建模任务,同时介绍基本的深度学习框架(如Transformer),也比较了语言模型与独立位点模型(independent-sites models),独立位点模型在基于结构预测的任务中表现出明显更好的特性。
如何定制用于训练蛋白质无监督模型的数据、模型和任务?
第三章“Transformer 蛋白质语言模型是无监督结构学习者”与第二章都在试图解释和验证这个问题。第三章从transformer attention特征图中提取表征,表明这些表征可以揭示大量关于蛋白质结构的信息,尽管没有明确的监督信息来预测结构。此外,还探索了模型尺度和超参数对特征的影响。
第四章“MSA Transformer“将多序列比对(MSA)作为输入,调整语言模型,进一步深入到这个问题中,讨论了在使用MSA时对模型体系结构、训练、推理进行的必要的更改。
蛋白质序列的大规模无监督模型能否用于蛋白质设计?
第五章“语言模型小样本预测突变对蛋白质功能的影响“回答了这个问题,特别是在预测单个突变的影响方面。研究了训练数据、模型融合和MSA选择的作用。


作者的贡献
1 构建了评估相同任务中不同蛋白质语言模型的基准数据集
这是一套5项生物学相关的下游任务,可用于公平的竞争环境中评估不同蛋白质语言模型。这些数据集以多种易于下载的格式免费提供。
2 实现了多种蛋白语言模型的公共可用库
在pytorch中实现了多个蛋白质语言模型使用HuggingFace风格的API。
3 构建了一种几乎不需要监督信息的通过预训练的语言模型预测蛋白质接触的方法
4 学习MSA表示的新架构
5 从单个序列或MSA预测突变的影响
部分蛋白质预训练模型地址:
ESM-b1:https://github.com/facebookresearch/esm
TAPE:https://github.com/songlab-cal/tape#citation-guidelines
ProtBert-BFD/Protrans:https://github.com/agemagician/ProtTrans
这个是学习基于transformer的蛋白质预训练模型最好的资料。
后台回复pretrain,即可获得这份资料。

