蛋白质语言建模?伯克利RoshanRao157页博士论文《训练,评估和理解蛋白质序列的进化模型》
最近,伯克利大学Roshan Rao 157页博士论文介绍了在通用基准上训练和评估蛋白质语言模型的方法。随后,研究了模型缩放、数据预处理和训练超参数对transformer在无监督的情况下学习蛋白质接触能力的影响,然后提出了一种在MSA上操作而不是在单个序列上操作的新方法,并证明了该方法在多个下游任务上实现了最优的性能。最后,讨论了所有这些方法在蛋白质设计中的应用。
作者介绍:

Meta AI的一名研究科学家,研究蛋白质序列的神经进化模型。之前,我在加州大学伯克利分校攻读博士学位,在那里我得到了John Canny和Pieter Abbeel的指导!
https://rmrao.github.io/作者发表的文章
训练,评估和理解蛋白质序列的进化模型Training, Evaluating, and Understanding Evolutionary Models for Protein Sequences
视频:

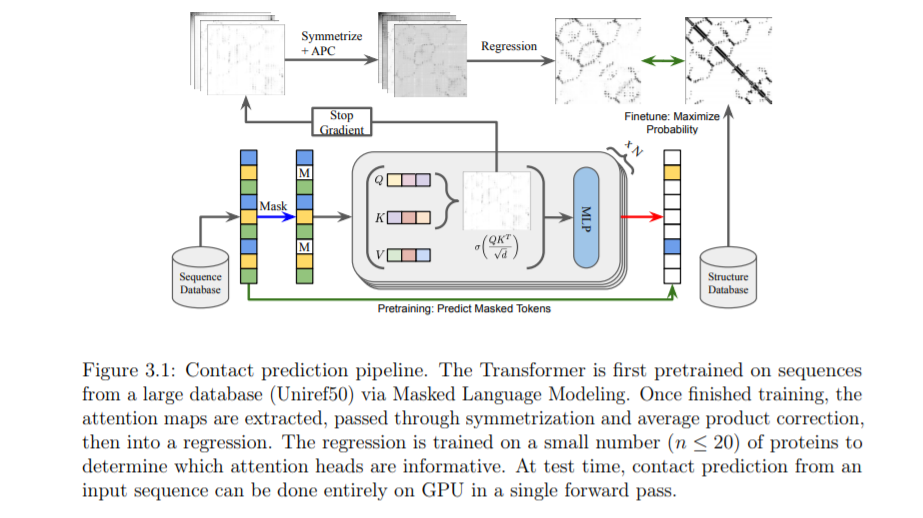
新的蛋白质序列通过突变产生。这些突变可能是有害的,有益的,或中性的;突变对生物体进化适应性的影响反映在生物体存活的时间是否足够长,使其蛋白质能够被采样并储存在序列数据库中。长期以来,生物信息学一直寻求利用这种进化信号,通常以多重序列比对(MSAs)的形式,来推断新蛋白质的结构和功能。随着神经网络和自监督预训练的出现,一种不同的方法出现了,使用语言建模目标对大规模神经网络进行预训练,从输入的蛋白质序列自动生成信息特征。
本文介绍了在一个通用基准上训练和评估蛋白质语言模型的方法。随后,研究了增加模型扩展、数据集预处理和超参数训练对transformers 在没有监督的情况下学习蛋白质接触能力的影响。一种新的方法操作在MSAs而不是单一序列,然后提出,并显示在几个下游任务达到最先进的性能。最后,讨论了这些方法在蛋白质设计中的应用。
本论文试图回答关于蛋白质序列语言建模的三个关键问题:
1. NLP中非监督学习的标准方法是否能学习生物学相关的特征?
2. 我们如何定制用于训练蛋白质的无监督模型的数据、模型和任务?
3. 蛋白质序列的大规模无监督模型能用于蛋白质设计吗?
专知便捷查看
便捷下载,请关注专知公众号(点击上方蓝色专知关注)
后台回复“EMPS” 就可以获取《蛋白质语言建模?伯克利RoshanRao157页博士论文《训练,评估和理解蛋白质序列的进化模型》》专知下载链接

请扫码加入专知人工智能群(长按二维码),或者加专知小助手微信(zhuanzhi02),加入专知主题群(请备注主题类型:AI、NLP、CV、 KG、论文等)交流~




