创建模型,从停止死记硬背开始

一、序曲
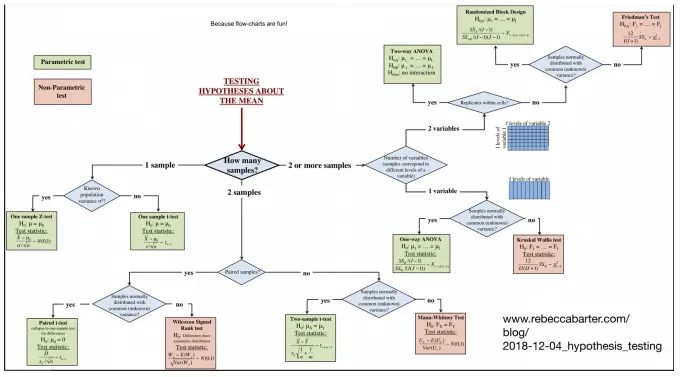
二、快速温习下线性回归
在线性回归中,我们建立特征x和响应变量y之间关系的线性模型。
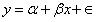
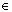 被设为随机参数。
被设为随机参数。
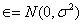
所有模型都是错的,但其中有一些是有用的。 (All models are wrong, but some are useful)
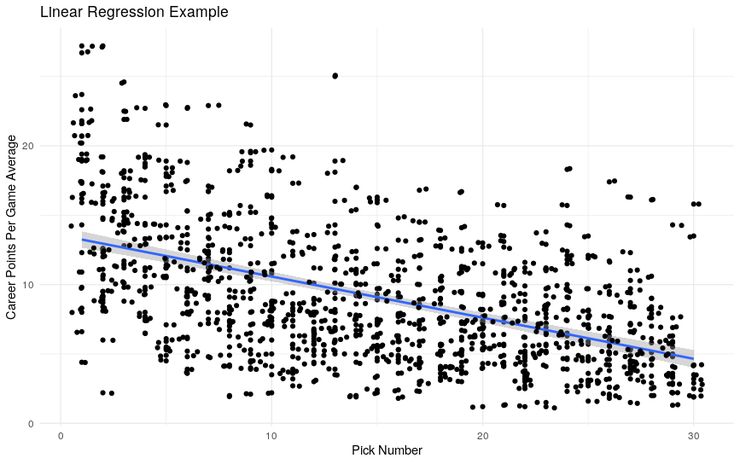
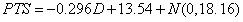
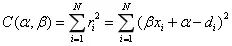
三、分类变量回归
我们也可以对本质上是分类的特征进行回归,这里的诀窍是对分类变量进行所谓的独热编码,其思想是将分类级别转换为指标变量(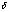
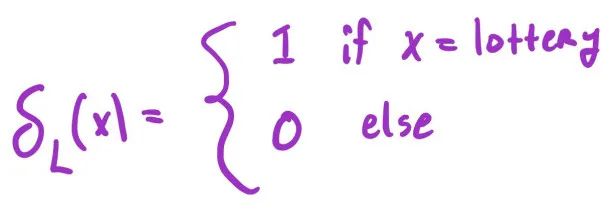
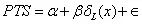
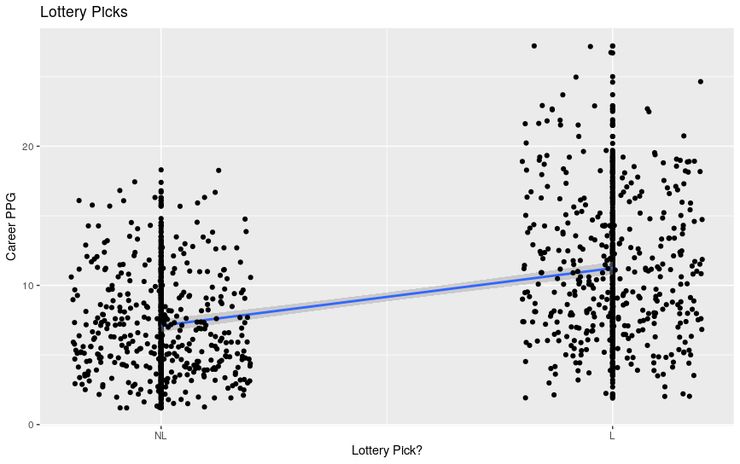
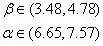
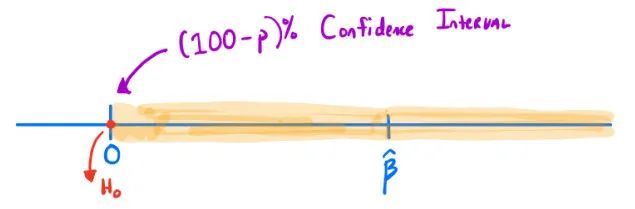
四、双样本 t 检验
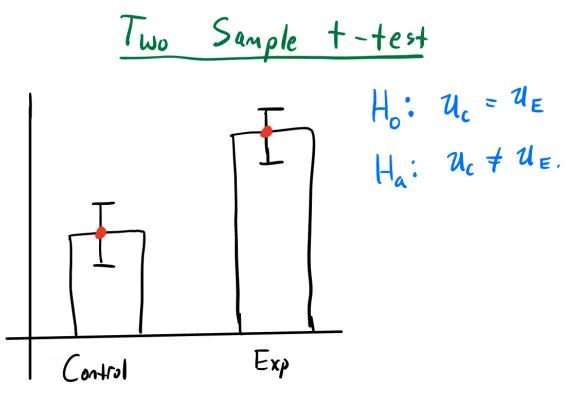

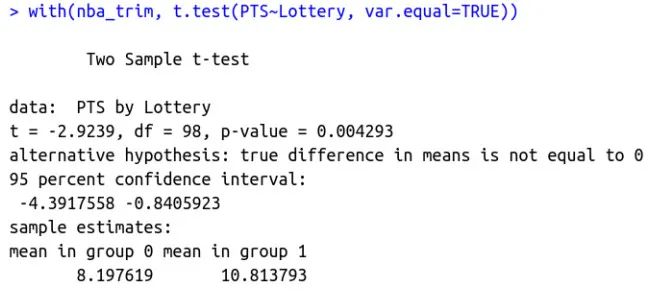
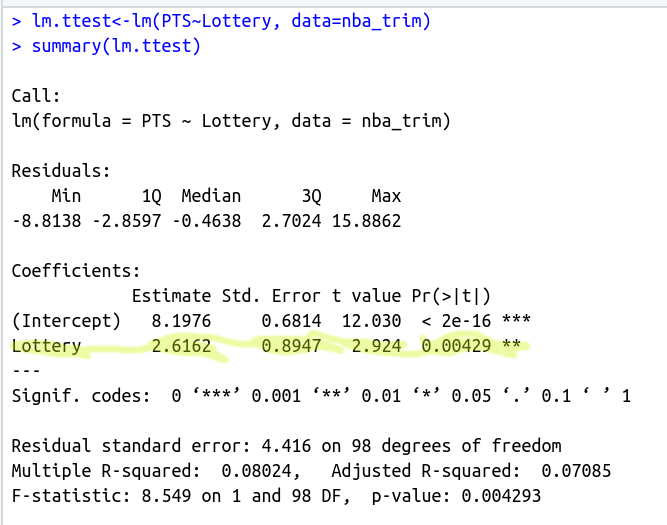
五、方差分析与多元回归
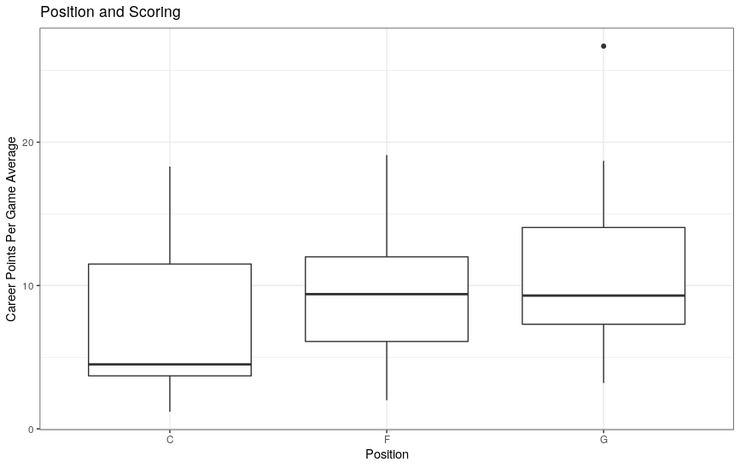
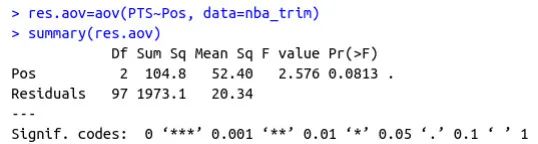
假设我们想评估球员位置对他们职业平均得分的影响。首先,我们应该清理数据集中位置列的级别。
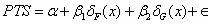
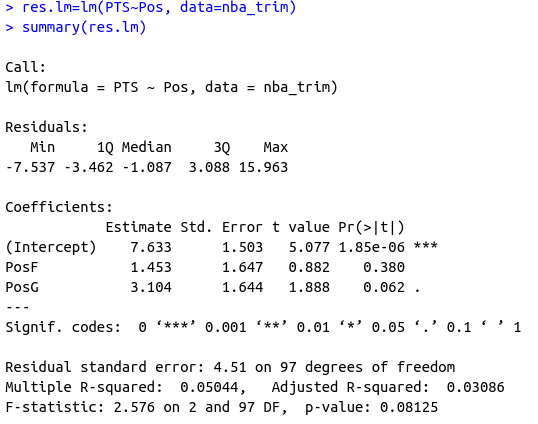
六、双因素方差分析

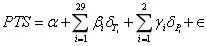

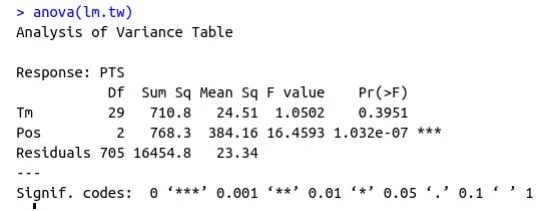
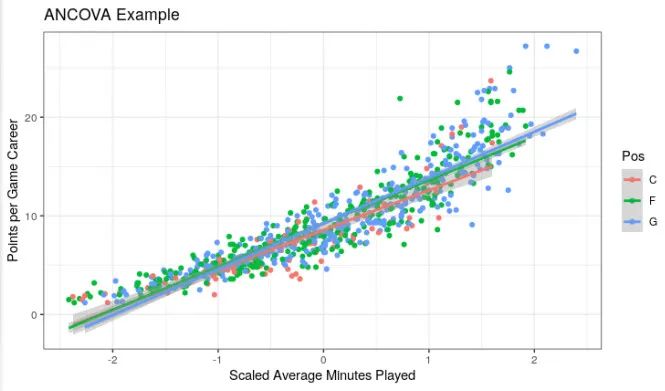
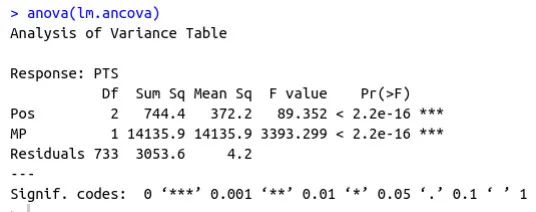
七、协方差分析


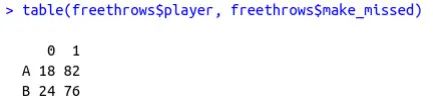
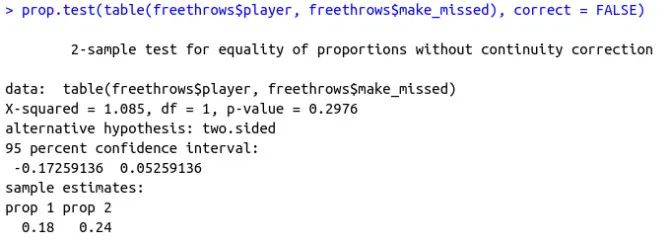
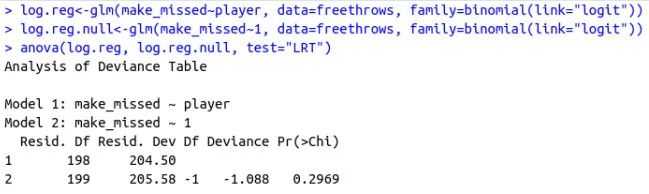
八、比例和广义线性模型

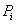 。
。
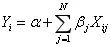
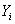 应该给出给定
应该给出给定
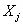 特征时
取值是1的概率。如上所述,我们会有疑问,因为模型的右侧输出
特征时
取值是1的概率。如上所述,我们会有疑问,因为模型的右侧输出
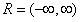 范围的值,而左侧应该位于[0,1]范围内。
范围的值,而左侧应该位于[0,1]范围内。
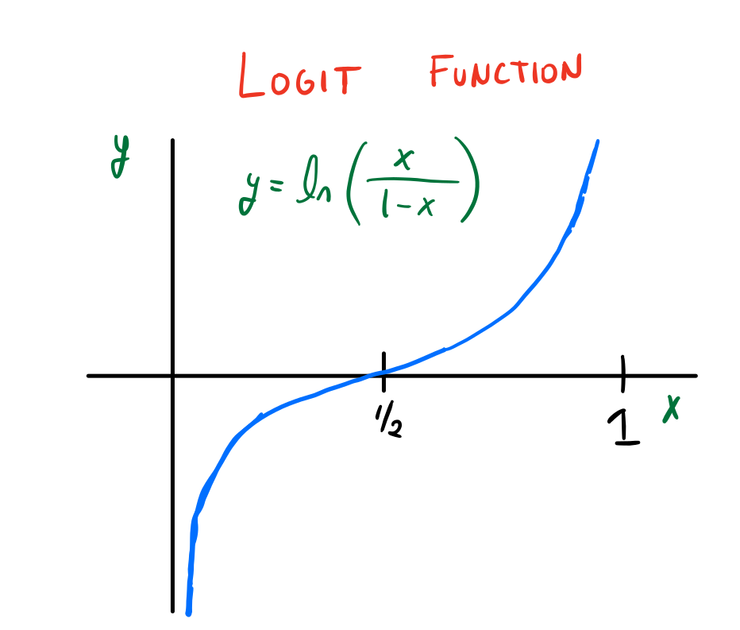
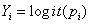 产生的,可以使用多元回归技术。这是逻辑回归的基本思想:
产生的,可以使用多元回归技术。这是逻辑回归的基本思想:
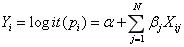
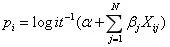
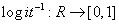 通过以下方式给出:
通过以下方式给出:
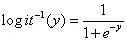
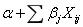 和一个将线性预测函数映射到响应变量的链接函数g( ):
和一个将线性预测函数映射到响应变量的链接函数g( ):
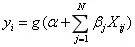
九、为什么这很重要?
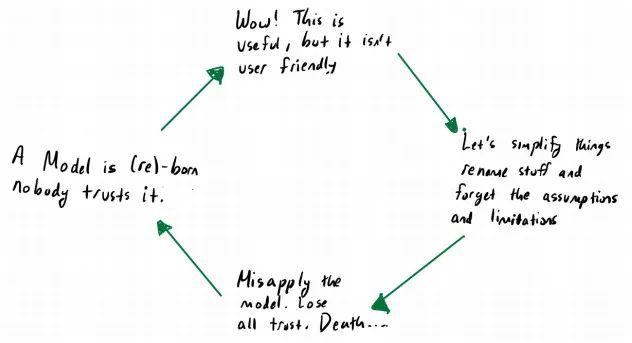
创建模型,从停止死记硬背开始。
-
https://lindeloev.github.io/tests-as-linear/
登录查看更多
相关内容





相关VIP内容
相关资讯