R爬虫小白入门:Rvest爬链家网+分析(三)

作者:汪喵行 R语言中文社区专栏作者
知乎ID:https://www.zhihu.com/people/yhannahwang
前言
上两节我们已经成功爬取了链家网的3w条数据,并且做了一些浅显的分析,那么这一节我们就利用机器学习,用除了房屋价格之外的其他因素(房屋高度/房屋面积等)来预测一套房子的价格。
objective:用除了房屋总价和房屋单位价格的其他因素,来预测房子的价格
用到的R包: splitstackshape / dummies / rpart / rpart.plot / RWeka / ggplot2
首先,根据我们的目标,我们需要预测的房屋总价是一个numeric的变量,具体的机器学习的方法有很多,比如简单的线性回归,回归树,模型树,甚至神经网络等等,这里具体介绍用regression tree和model tree来进行预测。这是因为对于比较复杂的数据,直接用建立一个全局线性规划模型有时候是不切实际并且费劲的,但是regression tree和model tree能够解决这个问题。
读取数据
1house_info <- read.csv("house_inf.csv",stringsAsFactors = FALSE)
由于之前数据里面还有一些需要处理的字符之类,在我们训练模型之前先把这些字符啊什么的都处理处理。
1content <- as.vector(house_info$house_level)
2content_size <-as.vector(house_info$house_size)
3content <- gsub(".*平.*地上","",content)
4content_size <- gsub("厅","",content_size)
5level <- as.data.frame(content)
6size <- as.data.frame(content_size)
7house_info[7] <- level
8house_info[3] <- size
9# 相当于把house_level,house_size里面的字去掉以后再放回去
看一下output:

这里我们发现:
1.house_size这个变量其实可以拆成两个,变成bedroom和hall。因为要用“室”来切分这个变量,所以之前我没有把变量里这个字去掉。
2.第一列对于我们预测房价没有什么意义,所以也直接去掉。
3.第5列其实也可以看成一个除了房屋总价的因变量,所以也应该去掉。
1library(splitstackshape)
2house_infos <- concat.split.multiple(house_info,"house_size", "室")
3colnames(house_infos)[7:8] <- c("bedroom","hall")
4house_infos <- house_infos[,-1]#去掉第一列
5house_infos <- house_infos[,-4]#去掉第五列
看一下output:
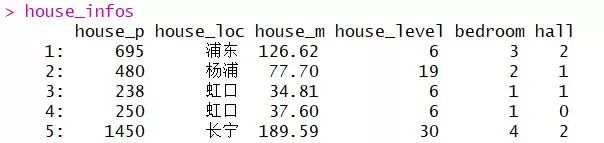
Model要求的形式是每一个variable是numeric或者int形式的,所以这里有个麻烦就是我们的house_loc,这是一个类别型变量,很容易想到的办法是给予每个区一个数字代替,但是这样是错误的,因为model对于这个变量会区分大小。比如“黄浦区”是1,“长宁区”是12,那么因为12>1,我们的model会认为“长宁区”>“黄浦区”,但是这种情况并不正确,所以用这种方法,我们的model准确度会很差。
其实对于类别型变量有一种方法就是one-hot Encoding(独热变量),把类别型变量变成dummy variables,既能实现类别型变量的区分,也不会造成直接赋值带来的问题。
这里用R中的dummies package就可以实现:
1library(dummies)
2#one-hot encoding on categorical variables
3house_infosd <- dummy.data.frame(house_infos, names=c("house_loc"), sep="_")
看一下output:
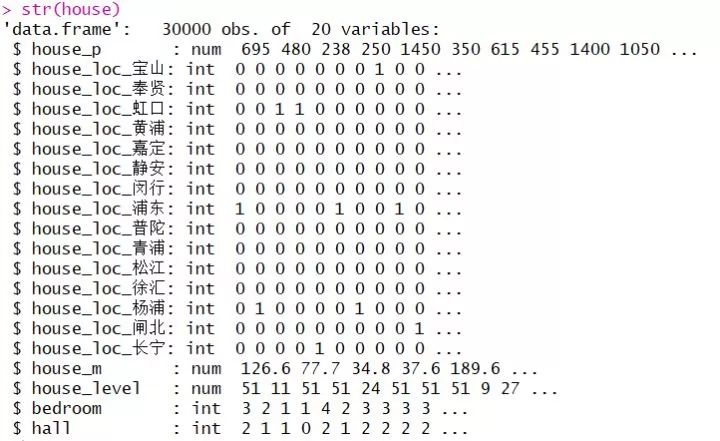
可以看出,我们原来一个house_loc变量,在运用dummies以后变成了15个变量,比如house_loc_黄浦,如果某条数据里为0,那么说明这套房子不在黄浦区,为1则说明在黄浦区,这个变量只能取0/1这两个值,代表是否存在。其他14个和house_loc变来的变量也是如此。
首先我们要划分训练集和测试集,这里按照3:1进行划分。
1#split the train and test datasets
2order <- sample(30000,22500)
3train <- house[order,]
4test <- house[-order,]
5test_p <- test$house_p
6test_f <- test[-1] # remove the variable which we want to predict
到此,train里面是我们包括house_p的训练数据,一共22500条,test_f是我们去掉house_p的测试数据,共7500条。
regression tree make predictions based on the average value of examples that reach a leaf. 回归树使用CART算法来构建树,使用二元切分法来分割数据,其叶节点包含单个值。首先,计算所有数据的均值,然后计算每条数据的值到均值的差值,再求平方和,即我们用总方差的方法来度量连续型数值的混乱度。在回归树中,叶节点包含单个值,所以总方差可以通过均方差乘以数据集中样本点的个数来得到。
在R中用rpart包来建立模型:
1library(rpart)
2model <- rpart(house_p ~ .,data = train)
3
output:

这里我们可以看见决策回归树是怎样来判定的,也可以用rpart.plot把树画出来:
1library(rpart.plot)
2rpart.plot(model, digits = 5)
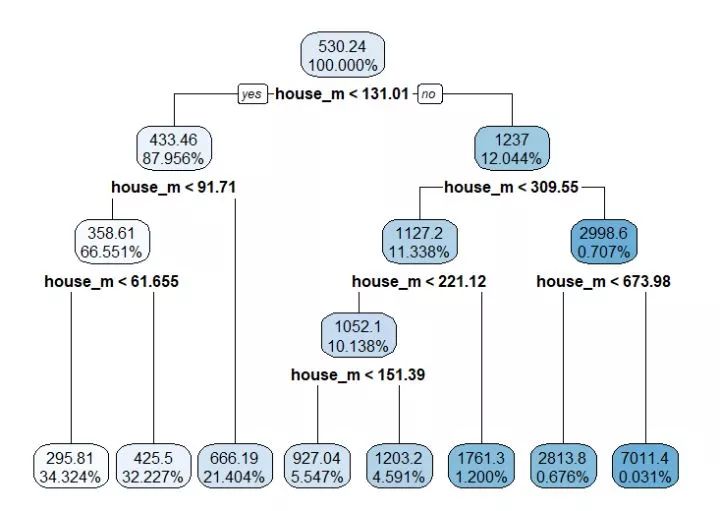
这里寻找的第一个切分点是house_m,当测试数据进来以后,会根据house_m的值去走到叶子节点,进行预测。
下面我们把测试集放进去进行预测:
1pre <- predict(model,test_f)
pre是我们用test数据集预测数来的房屋价格,test$house_p是test数据集里面原有的房屋价格。可以看出它们在中间部分的分布差不多,极值的差别还是很大的。
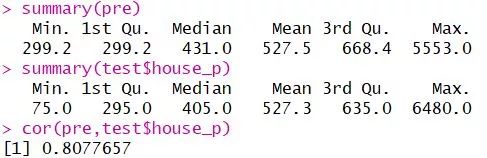
cor在0.81左右,说明真实值和预测值是很相关的。说明模型准确度还可以。
算一下MAE
1# MAE
2MAE <- function(actual, predicted) { mean(abs(actual - predicted)) }
3MAE(pre, test$house_p)
MAE= 147.8623
单纯的MAE是看不出我们预测值和真实值的差别的,所以我们可以用整个数据的平均值去放到整个数据的预测变量里,看看这个MAE2是多少,再和我们model的MAE比较:
1mean(test$house_p)
2MAE(527.3331, test$house_p)
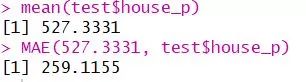
MAE2=259.311>147.8623=MAE,说明我们的模型减小了误差,但是并不是那么好,可以考虑用model tree试试看。
模型树与回归树的差别在于:回归树的叶节点是节点数据标签值的平均值,而模型树的节点数据是一个线性模型。简单来说,就是只有当某个data到达某个叶子节点的时候,才会用叶子节点上面建立的model去预测。
Model tree里面会用到的就是这个Rweka包:
1library(RWeka)
2model.m5p <- M5P(house_p ~ ., data = train)
3
house_p是我们要预测的因变量,这个.代表除了house_p之外的其他变量,"data="后面跟的就是我们需要训练的数据。
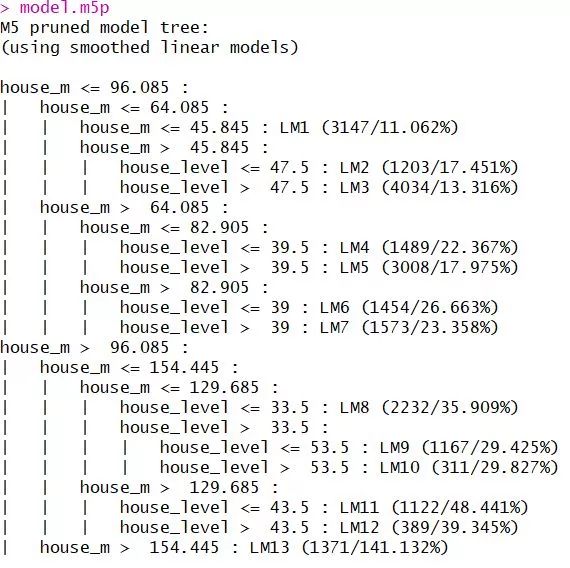
我们最后训练的模型就是这样子的,LM1-LM13代表的是每个叶子节点上的线性模型,也就是说,当我们用这个模型树进行预测的时候,当某个test data走到某个叶子节点的时候,就会用那个叶子节点上的model来进行预测。
带入测试数据:
1pre.m5p <- predict(model.m5p, test_f)
比较一下真实值和预测值的情况:
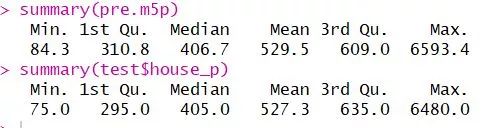
1cor(pre.m5p,test$house_p)

cor也可以看出,比刚刚的相关度0.81要高了很多。MAE比刚刚小了一些,说明model tree准确度和相关度都是优于regression tree的。
最后让我们以一张model tree预测的预测房价和真实房价的对比图结尾:
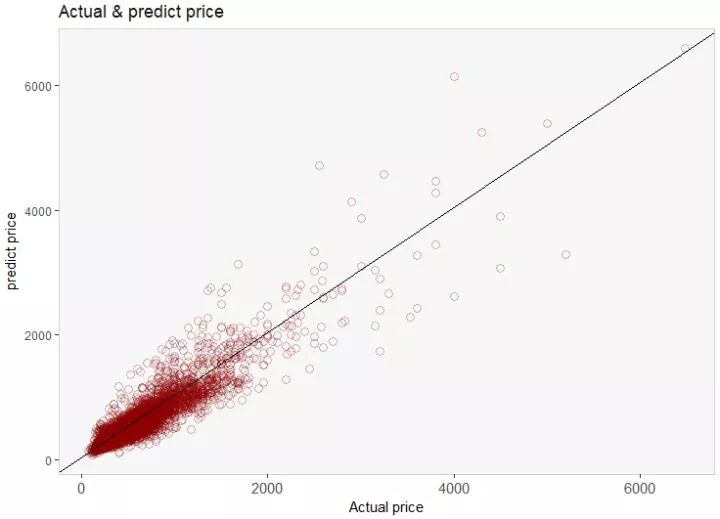
散点越靠近y=x这条线,说明模型效果越好。从图中看出,我们的模型还是比较好的。
根据这个模型我们也可以知道,可以去找那些在y=x这条线以下的房子,因为这些是低于市场价的。
最后写写模型可以改进的地方。
1.数据方面,单单把上海分成十几个区可能不大科学,但是考虑到独热变量可能带来的维度飙升问题所以还是选择只用十多个区而不再细分
2.可能可以对于一些异常值进行处理
3.回归树和模型树可能可以剪枝(?)效果可能会好一些,但也需要尝试才知道
最后的最后,做再多的模型,还是!买!不!起!房!
罢了罢了,与其唱一首 凉凉 送给自己,不如过好佛系的一生。足矣。
参考文献:
《Machine Learning with R, 2nd Edition》 by Brett Lantz
附上画图代码 :
1library(ggplot2)
2ggplot(data = b,aes(x=b$V1 ,y=b$pre.m5p))+
3 labs(x="Actual price",y="predict price",
4 title = "Actual & predict price")+
5 geom_point(size=3,shape=21,color="dark red",alpha=0.3)+
6 geom_abline(intercept = 45,color="black")+
7 theme(axis.text.x = element_text(angle = 0,size=11),
8 panel.grid.major=element_blank(),
9 panel.grid.minor=element_blank(),
10 panel.background = element_rect(fill = "gray97"),
11 panel.border=element_rect(fill="transparent",color="light gray"),
12 plot.title = element_text(lineheight = 610,colour = "gray9"))

今日祈祷:
没房子的你,过得还好吗?祝愿看到此篇的朋友们都能有一个属于自己的豪宅。

往期精彩:

公众号后台回复关键字即可学习
回复 爬虫 爬虫三大案例实战
回复 Python 1小时破冰入门
回复 数据挖掘 R语言入门及数据挖掘
回复 人工智能 三个月入门人工智能
回复 数据分析师 数据分析师成长之路
回复 机器学习 机器学习的商业应用
回复 数据科学 数据科学实战
回复 常用算法 常用数据挖掘算法
有房子的朋友请坐下↓



