【报告分享】胡包钢研究员:基于信息理论的机器学习(附报告PPT)
【导读】深度学习近年来在各个领域取得了巨大的成功,然而深度神经网络的可解释性及其理论尚未解决。利用信息论来解释神经网络的文章也逐渐引起关注,比如《Deep Learning and the information Bottleneck Principle》《Opening the Black Box of Deep Neural Networks via Information》,深度学习先驱Geoffery Hinton也曾评价该文章”信息瓶颈极其有趣…或许是解开谜题的那把钥匙”。自动化所胡包钢研究员在国际神经信息处理会议ICONIP上做了《基于信息理论的机器学习》教学报告。报告认为,信息学习理论将会成为未来机器学习理论发展中更为重要的基础内容。报告介绍了信息学习理论与机器学习的区别与联系,以新的视角来描述机器学习问题,也就是”What to learn”, “How to learn”, “What to evaluate”, “How to evaluate”这个四个基本问题。报告认为,统计学与优化理论主要是解决“How to learn”的问题,而无法回答“what to learn”的科学问题。
报告内容分为以下部分:
引言(Introduction)
信息理论基础(Basics of Information Theory)
二值信道的理论进展(Theoretical Progress in Binary Channel)
分类评价中的信息度量(Information Measures in Classification Evaluation)
贝叶斯分类器和互信息分类器(Bayesian Classifiers and Mutual-information Classifiers)
总结和讨论(Summary and Discussions)
本篇主要分享“信息论基础”和“二值信道的理论进展
在机器学习中,经验学习准则一般基于经验函数,如误差、泛化误差、误差边界、风险、损失、准确率、召回率等;而信息学习理论准则通常是基于熵的函数,如信息熵、信息散度、交叉熵、互信息等。
那么,对于一个机器学习问题,我们应该选择哪种学习准则作为目标?我们是否可以将基于熵的函数作为理解机器学习机制的统一理论呢?信息学习准则与经验学习准则之间的关系,以及使用信息学习准则的优势与局限是什么呢?
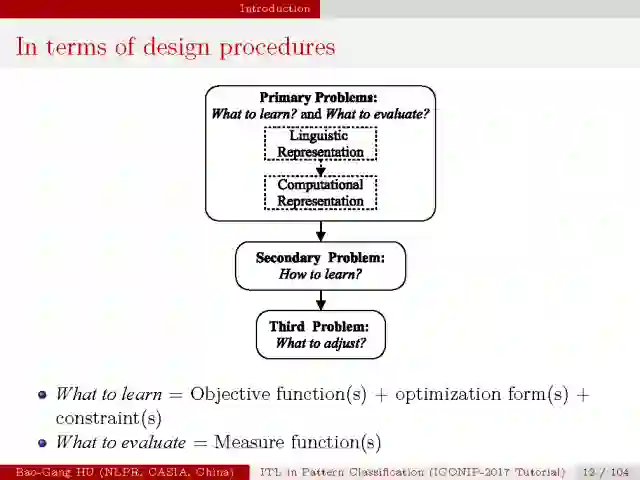
我认为机器学习可分为四个基本的问题,“what to learn”, “how to learn”, “what to evaluate”, “what to adjust”。
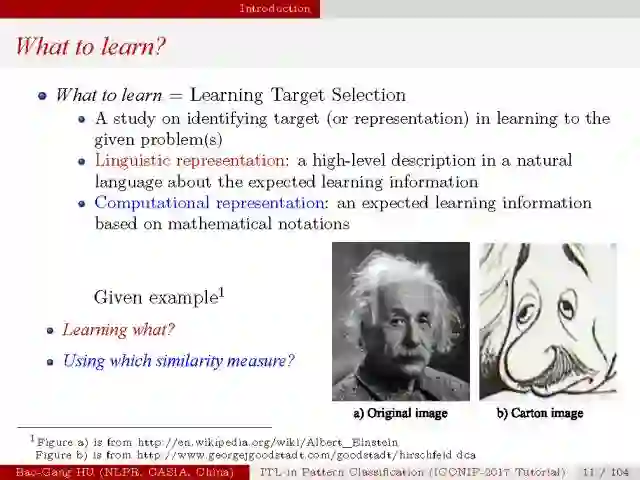
“what to learn” 是指学习目标的选择,要学习什么以及选择什么度量方式, 它通常由目标函数,优化方法与约束条件组成;”what to evaluate” 是指度量函数;这两个问题在计算表达与可解释层面组成了机器学习的初级问题;在这个基础上,”how to learn”是次级问题,它表示在满足所有约束条件下达到学习目标的学习过程设计与实现;第三级问题是”what to adjust”, 体现了机器在实现智能动态进化或成长的功能。
在大部分的机器学习与模式识别研究中,关注更多的是”how to learn”与”what to evaluate”的问题,但是”what to learn”以及”how to adjust”的问题却很少被研究,而他们也是机器学习更加智能的关键,如果学习目标是错误的,即使再好的学习方法也无法达到目标;而不知道如何调整机器学习组件,也就无法提升机器智能的层次。

老子在《道德经》中写到,“道生一,一生二,二生三,三生万物”, 可见万事万物皆有其本源的道理,寻找这种统一思想从两千多年前就是人们探索事物本质的一种方式。在人工智能的发展过程中,人们也曾尝试提出统一的思想框架,如上图所示。本人认为,机器学习的本质是从数据中提取和学习有用信息的过程,而信息论为信息的处理提供了坚实的理论框架,基于信息论的机器学习理论将会在今后机器学习的发展中扮演重要的角色,或许会成为机器学习统一理论的基石。
信息论基础
在这一部分,首先介绍熵的概念,它是随机变量不确定度的度量。如下,香农熵的计算形式,二值熵函数。


但是,先有熵还是先有概率?这仍然需要我们去理解哪一个是源哪一个是流。例如最大熵PCA的例子。


这是在比较几种信息度量。

在上图中,监督学习中信息度量的图式理解,这个图很重要,T表示目标变量,H(T)是分类问题的基线;优化算法优化目标尽可能接近这个基线,但是直接优化交叉熵H(Y;T),KL散度,条件熵并不一定能达到目的。只有互信息作为一种相似性的度量,拥有对称的属性。
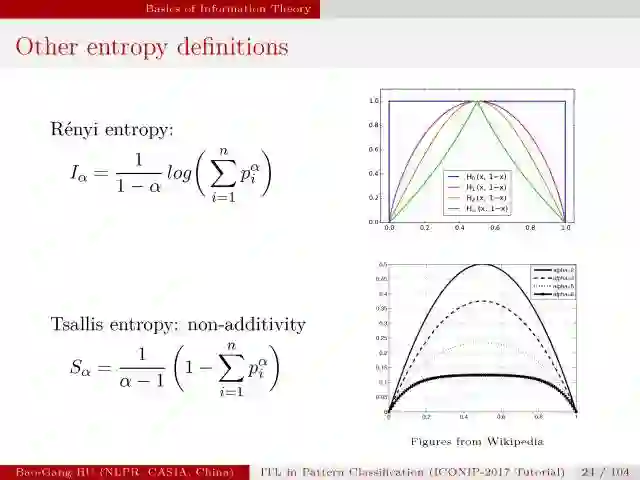
然后是介绍其他基于熵的度量方式以及不同散度的定义。
信息论源自于熵的概念,熵的数学定义形式会随着信息论的发展不断拓展;如果我们用类比的方式理解信息度量,比如,熵看作单一随机变量的偏差;互信息看作两个随机变量的协方差;归一化的互信息看作两个随机变量的相关系数;散度看作两个随机变量的一种距离度量。可以从中得到许多启发。
二值信道的理论进展

分类是一种监督学习,因为每个样本的目标类标T通常给出。
(目前的深度学习是“
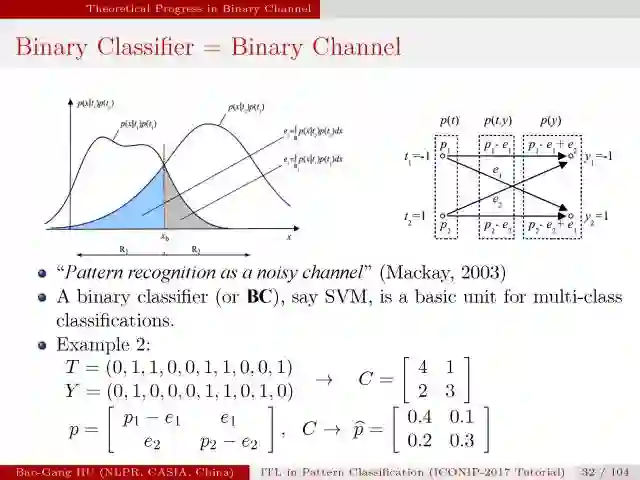
二值分类在通信理论中被称为二值信道。

在传统信息论研究中仅考虑贝叶斯误差。

信息论中已有的上界与下界计算公式。它们适用于m类有限类别,
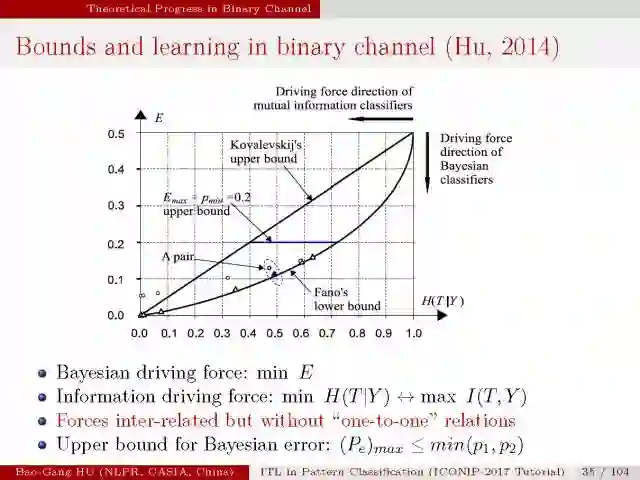
该图示意了二值分类上界与下界曲线。

二值分类中条件熵计算公式。由于H(T)通常为固定值,


应用优化的方法我们从联合概率分布导出上下界计算公式,


贝叶斯误差与条件熵的关联关系。下界与Fano完全相同,
该界同时包括互信息为零(即条件熵最大,或
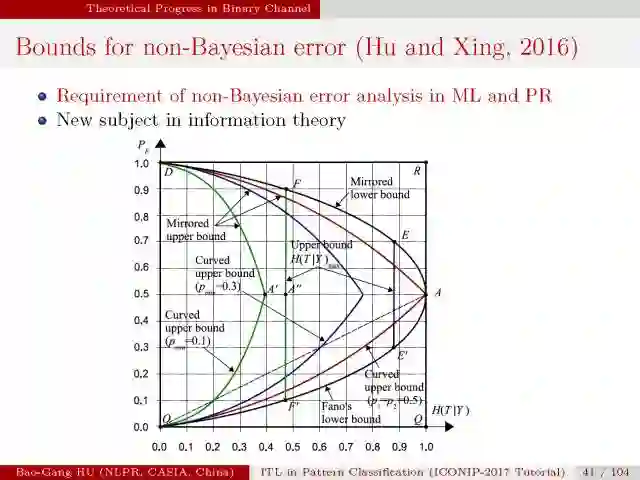
非贝叶斯误差与条件熵的关联关系。

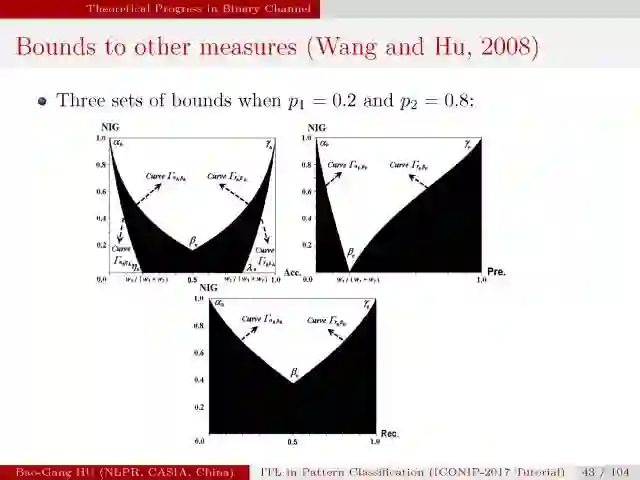
这是首次推导的二值分类性能指标与互信息关联的关系式。
本章总结
误差与条件熵的界分析是建立信息类学习目标与传统经验类学习目标
参考文献:
New Theory Cracks Open the Black Box of Deep Learning:
https://www.quantamagazine.org/new-theory-cracks-open-the-black-box-of-deep-learning-20170921/
胡包钢研究员个人主页:
http://www.escience.cn/people/hubaogang/index.html
胡包钢老师简介:
胡包钢老师是机器学习与模式识别领域的知名学者,1993年在加拿大McMaster大学获哲学博士学位。1997年9月回国前在加拿大MemorialUniversity of Newfoundland, C-CORE研究中心担任高级研究工程师。目前为中国科学院自动化研究所研究员。2000-2005年任中法信息、自动化、应用数学联合实验室(LIAMA)中方主任。
▌PPT
Information Theoretic Learning in Pattern Classification