引入额外门控运算,LSTM稍做修改,性能便堪比Transformer-XL

An LSTM extension with state-of-the-art language modelling results.
一个LSTM 扩展,能够取得 SOTA 语言模型结果。

研究意义
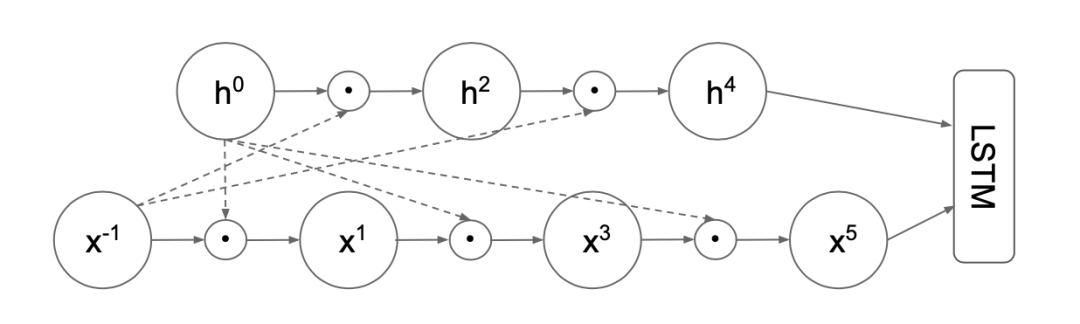
主要思路
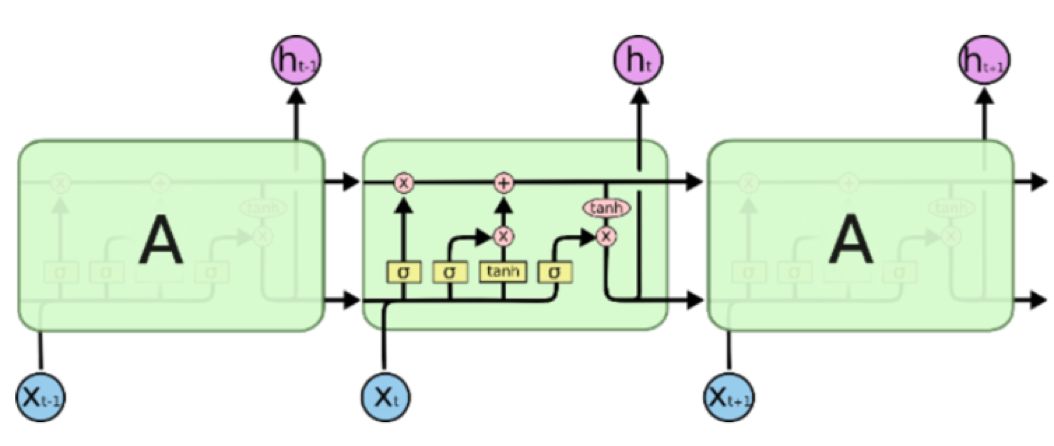
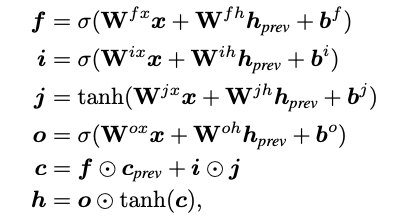
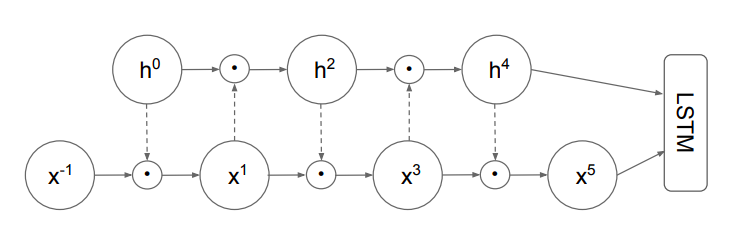


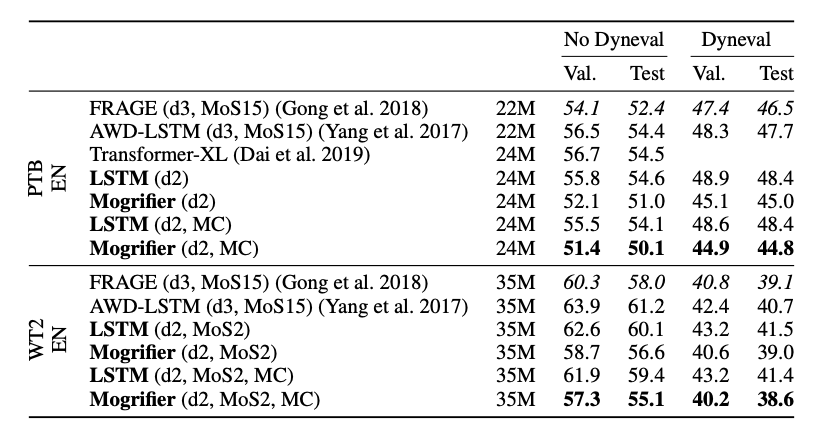
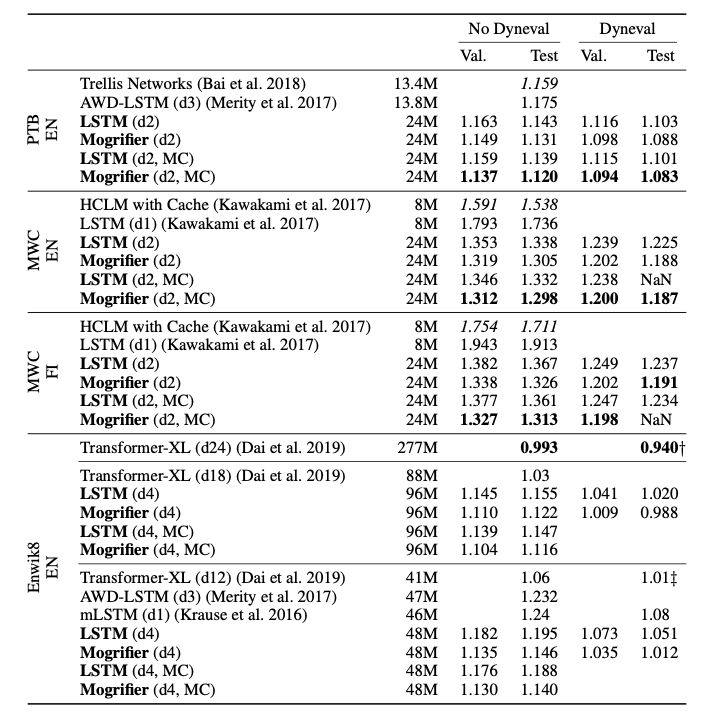
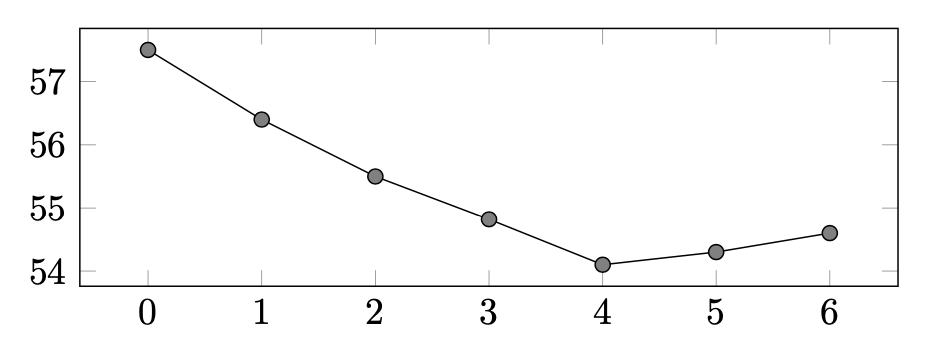
实验
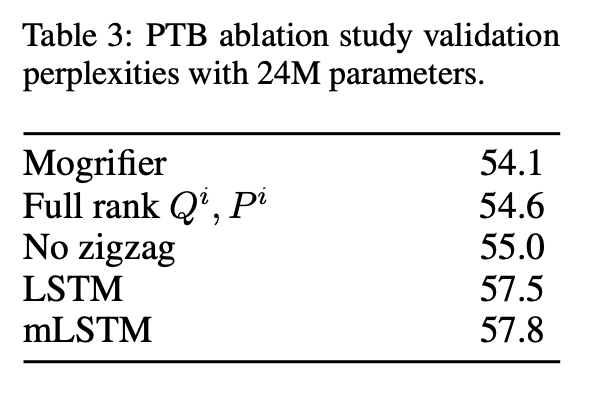
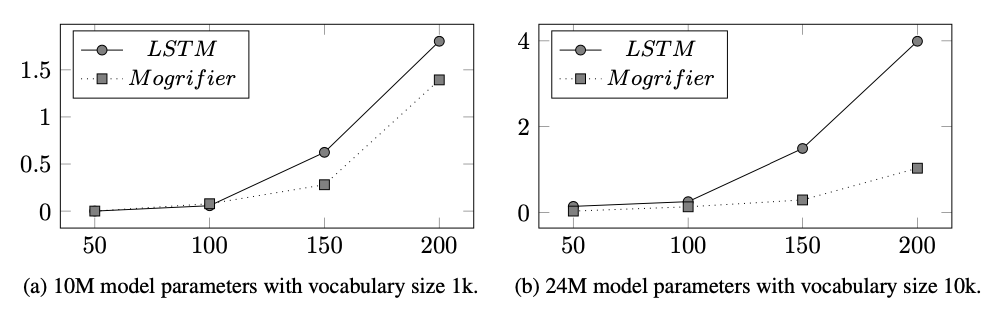
总结
火爆的图机器学习,ICLR 2020上有哪些研究趋势?
03. Spotlight | 组合泛化能力太差?用深度学习融合组合求解器试试
04. Spotlight | 加速NAS,仅用0.1秒完成搜索
3、Poster
Poster | 华为诺亚:巧妙思想,NAS与「对抗」结合,速率提高11倍

 点击“
阅读原文” 前往 AAAI 2020 专题页
点击“
阅读原文” 前往 AAAI 2020 专题页
登录查看更多
相关内容





相关VIP内容
相关资讯
相关论文