今日头条丨一点资讯丨腾讯丨搜狐丨网易丨凤凰丨阿里UC大鱼丨新浪微博丨新浪看点丨百度百家丨博客中国丨趣头条丨腾讯云·云+社区
本文刊发于工信部主管,中国电子技术标准化研究院主办的《信息技术与标准化》杂志,2019.5期《大数据技术与应用专刊》。
自计算机诞生以来,信息技术潜移默化的影响着人类生活的方方面面。尤其是近十余年来,大数据、人工智能、云计算等技术蓬勃发展,让人们的生活方式每隔几年就产生天翻地覆的改变。由大数据的汇聚,分布式技术释放计算能力开始,技术不断延伸发展,大数据、人工智能与云计算的边界越来越模糊,三类技术不断互相影响与融合。大数据3.0时代正是这些前沿技术不断结合,真正赋能各行各业的伟大时代。
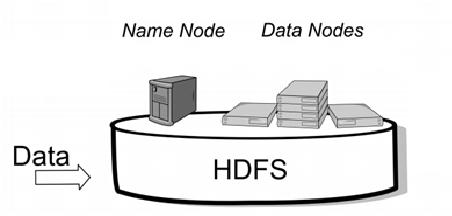
2006年的Apache基金会仿照谷歌在2003年发表的Google File System论文建立了Hadoop开源项目,用来解决大规模的数据存储和离线计算的难题。首先诞生的是分布式文件系统HDFS和分布式计算框架MapReduce。HDFS至今仍被沿用,MapReduce则随着硬件成本的降低,逐渐被基于内存的计算框架取代。但MapReduce在那时的条件下,已经是最适合的思路,意义非凡。
随后在2007年的时候,Apache Hadoop项目仿照谷歌的BigTeble开发了HBase,一个分布式的大型NoSql数据库。除此之外还有Apache Hive,Hive可以使用类SQL语言查询存放在HDFS上的数据。Hive利用这种语言最终被转化为MapReduce,实现SQL查询。
从2006到2009年这个阶段,以MapReduce计算框架为代表,大数据技术广泛应用于大规模结构化数据的批处理。具体的应用场景是互联网公司用这些技术做用户行为分析和精准营销。这个阶段我们称之为大数据的1.0时代,1.0时代的大数据技术只在大型互联网巨头中有所应用,技术难度非常高。
大数据进入2.0时代的标志,是Spark核心计算引擎的出现。Spark的出现主要是由于MapReduce在需要短时间响应的交互式分析场景下表现的并不够好,人们需要一个更加高效的计算框架。从2009年Spark诞生到2015年Spark在这场战争中逐步胜出,以Spark为主流的计算引擎已经广泛的替代了MapReduce。这个阶段有两个重要变化:
一方面是大数据开始从过去做日志用户行为分析转为记录化数据处理,所有的大数据公司开始在Hadoop之上打造SQL引擎,或者在Hadoop之上打造分布数据库。
2012年开始竞争进入到白热化阶段,随后两年中出现20多个基于Hadoop的SQL引擎,解决结构化数据问题。
到
2015年竞争后只留下了4个,当中星环的批处理数据库Inceptor基本上可以说赢得这场竞争,成为支持SQL最完整、性能最好的分析型数据库。
第二方面,实时数据处理方面。
这个时期物联网技术开始蓬勃发展,大量的传感器数据需要及时处理,此时出现了多种流计算引擎。
到2015年 Flink、Storm、Spark Streaming等几个产品成为主流。
星环的流处理引擎Slipstream在2014年开始上线,可以在低延时计算框架上面支持复杂的SQL引擎以及机器学习。
如今也成为流处理技术上功能最完善,性能最强的实时流处理产品。
大数据2.0时代是一个百花争鸣的时代,更多的玩家参
与到了技术角逐中,诞生了很多全新的技术,能解决更多业务场景下的实际问题。
至2015年,结构化数据的处理问题已经基本解决,此后人们开始把关注焦点转到了非结构化数据处理上面,特别是图像、视频、语音、文本的处理。人们将此前在非结构化数据表现出众的深度学习技术与大数据技术相结合。除此之外,人们又试图用深度学习这样新的思路去解决过去MapReduce和Spark已经解决的问题,如结构化数据处理等问题。大家希望有一个统一计算框架来处理,从结构化数据到非结构化数据的所有的问题。
随着时间和业务不断的发展,人们提出了新的需求,是否能将大数据这种分布式的架构部署在云平台上,更好的实现数据共享,解决数据孤岛和烟囱开发等难题。
至此,大数据技术、人工智能技术、云计算技术开始融合。大数据3.0时代要求在同一个平台当中,满足各种不同层次的大数据需求。大数据技术,解决了深度学习计算力和训练数据量的问题,开始产生巨大的生产价值;同时,大数据技术通过将传统机器学习算法分布式实现,向人工智能领域延伸;此外,随着数据不断汇聚在一个平台,通过容器技术,在容器云平台上构建大数据与人工智能基础公共能力,将人工智能、大数据与云计算进行融合。
![]()