复旦邱锡鹏团队最新成果fastHan:基于BERT的中文NLP集成工具
机器之心编辑部
fastHan 是基于 fastNLP 与 PyTorch 实现的中文自然语言处理工具,像 spacy 一样调用方便, 其内核为基于 BERT 的联合模型。




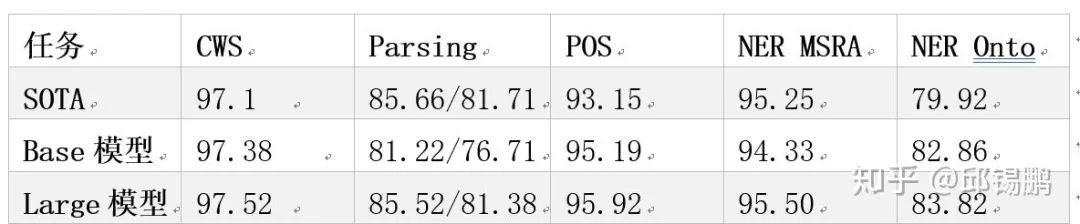
CWS:AS、CITYU、CNC、CTB、MSR、PKU、SXU、UDC、WTB、ZX
NER:MSRA、OntoNotes
POS & Parsing:CTB9

登录查看更多
相关内容

专知会员服务
64+阅读 · 2020年4月28日
Arxiv
16+阅读 · 2019年5月24日




相关VIP内容
专知会员服务
64+阅读 · 2020年4月28日
相关资讯
相关论文
Arxiv
16+阅读 · 2019年5月24日