【首届北美计算机华人学者年会】伊利诺伊大学刘兵:终身机器学习(45PPT)
新智元报道
来源:SOFC 2017
翻译/报道:刘小芹,闻菲
【新智元导读】第一届北美计算机华人学者年会暨计算技术前沿研讨会于 2017 年 6 月9-10日在芝加哥举行。这是会议是华人计算机学者的顶级盛会,新智元从会议主办方处获得了伊利诺伊大学芝加哥分校刘兵教授在会上的演讲PPT,刘兵教授以《打造能够终身学习的机器》为题,介绍了终身机器学习(Lifelong Machine Learning,LML)系统,尤其是 LML 在自然语言处理中的应用。

北美计算机华人学者协会(Association of Chinese Scholars in Computing,ACSIC)的使命是通过协助和促进成员对社会的贡献,推进计算科学技术和教育。
ACSIC 通过提供成员之间的信息交流和协作机会,提高会员的知名度和奖学金,组织社会和技术活动,以及与其他科技机构和企业合作来实现其使命。
第一届北美计算机华人学者年会暨计算技术前沿研讨会(The First ACSIC Symposium on Frontiers in Computing,SOFC)于 2017 年 6 月 9-10日在芝加哥举行。会议旨在:(1)探讨计算技术的前沿问题;(2)促进华人计算机学者的交流与合作;(3)凝聚华人计算机学者的共识。
在本次会议上,以下华人计算机学者发表了主旨演讲:
Ming Li,滑铁卢大学(ACM Fellow, IEEE Fellow)
Bing Liu,伊利诺伊大学芝加哥分校(ACM Fellow, AAAI Fellow, IEEE Fellow)
Yuan Xie,加州大学圣巴巴拉分校(IEEE Fellow)
Lixia Zhang,加州大学洛杉矶分校(ACM Fellow, IEEE Fellow)
Xiaodong Zhang,俄亥俄州立大学(ACM Fellow, IEEE Fellow)
Yuanyuan Zhou,加州大学圣地亚哥分校(ACM Fellow, IEEE Fellow)
主旨演讲话题覆盖了计算机系统、网络、体系结构、算法、人工智能等计算机科学的几个大方向。会议还就“计算前沿技术”(Frontiers in Computing)举办了论坛。
其中,伊利诺伊大学芝加哥分校的刘兵教授,演讲题目为《打造终身学习的机器》,涉及“终身机器学习”(Lifelong Machine Learning,LML)的概念与机器学习密切相关。
下面就是刘兵教授的 PPT 全文。

终身机器学习
刘兵
伊利诺伊大学芝加哥分校计算机科学系

经典学习范式(ML1.0)
孤立的单任务学习:给定一个数据集,运行一个ML算法,然后构建一个模型。
没有考虑任何以前学的知识
“孤立学习”的弱点:学到的知识没有保留或积累,也就是说,没有记忆。
需要大量的训练示例。
适用于限制环境中有明确定义的狭义任务。
不能自我激励和自我学习

机器学习:ML 2.0
人类从来不是孤立地学习的:人类是连续学习
积累过去学到的知识,并利用它们去学习更多知识;
高效地从少量示例学习,并自我激励。
终身机器学习(LML):
模仿人类的这种学习能力

人类不是孤立地学习的
没有人会给我1000个正面的和1000个负面的汽车评论,然后让我建一个分类器去给汽车评论分类。
我可以不需要任何评论来训练就可以做到这些,因为我已经知道人们是如何赞美和贬损事物。
如果我没有积累的知识,我不可能做到这些。比如说,我完全不懂阿拉伯语,即使有人给我2000个用阿拉伯语写的正面/负面评论来训练,我也不可能学会。

大纲
终身学习的定义
基于全局知识的终身学习
基于局部知识的终身学习
自我意识和自我激励的学习
利用图形的终身学习
测试或执行中的学习
总结

LML的定义
学习者从1到N完成一系列任务的学习。
在面对第(N + 1)个任务时,它使用知识库(knowledge base,KB)中的相关知识来辅助学习第(N + 1)个任务。
在学会第(N + 1)个任务后,将第(N + 1)个任务的学习结果更新到知识库。
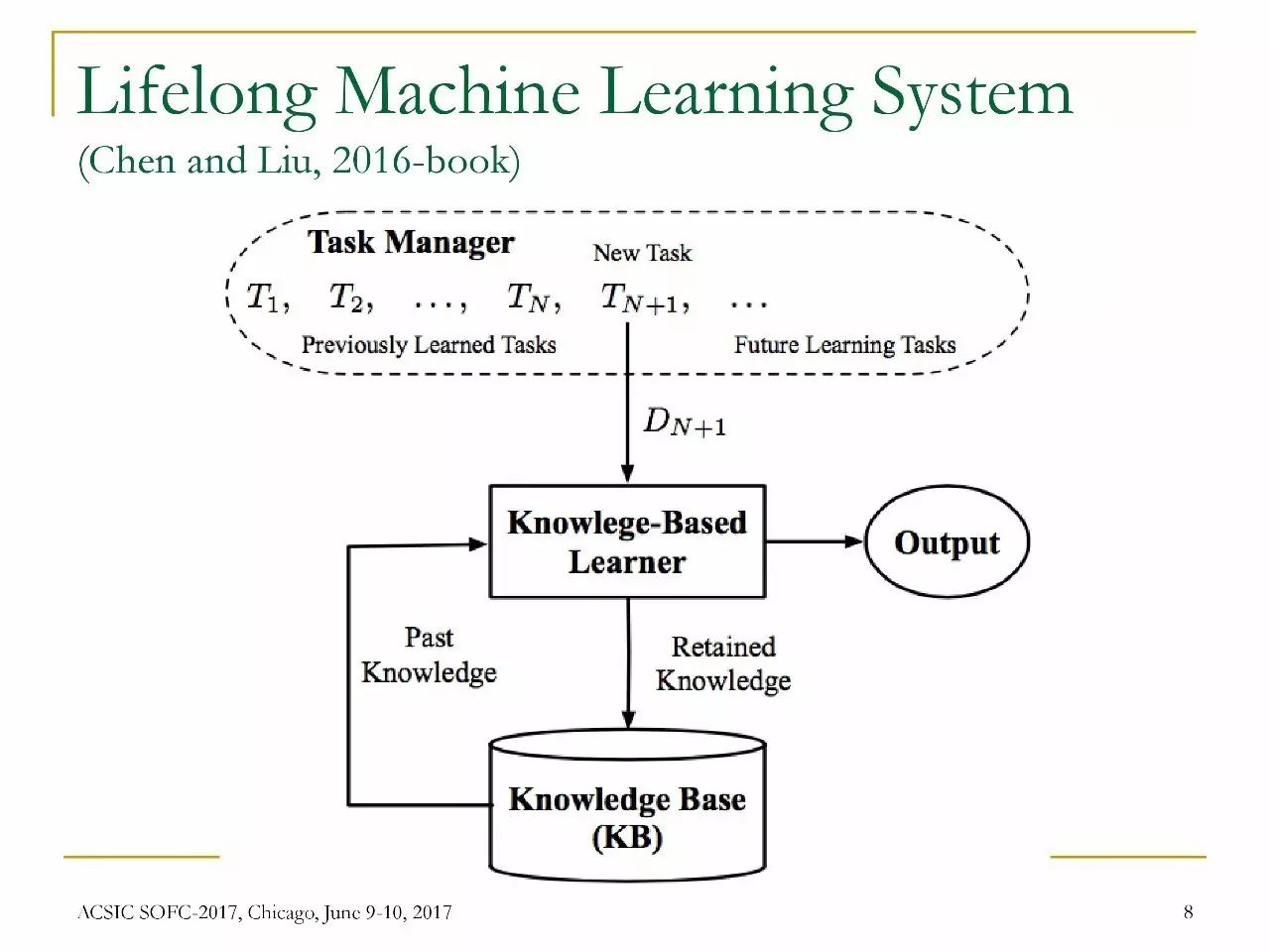
终身机器学习系统(示意图)

LML的主要特征
连续学习过程:不仅在训练过程学习,而且在模型使用或执行中学习
知识被保留和积累在知识库:具有更多的知识
使用并适应过去学习的知识,以帮助未来的学习和解决问题

迁移学习,多任务学习 →终身学习
迁移学习 vs. LML
迁移学习是不连续的
迁移学习不保留或积累知识
迁移学习只有一个方向:帮助目标领域
多任务学习vs. LML
多任务学习除了保留数据外,不保留知识
当任务有很多时,很难重新学习
在线的多任务学习就是LML

共享知识的两种类型
全局知识(Global knowledge):许多现有的LML方法假设在共享的任务中存在一个全局的潜在结构(global latent structure)。
这种全局结构可以在新任务的学习过程中学到和利用。
这些方法来自多任务学习。
任务应该来自同一领域。

ELLA:有效的终身学习算法
ELLA基于GO-MTL,一种批处理多任务学习方法。
ELLA是在线多任务学习方法,更高效并能处理大量任务。ELLA是一种终身学习方法,可以高效地添加新任务的模型,每个过去任务的模型都可以快速更新。

方法:共享的全局知识
每个模型的参数向量
是权重向量
和基本模型参数L的线性组合,公式如:
(Kumar et al.,2012)。
初始目标函数如PPT上所示。
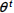
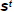

两种类型的知识
局部知识(Localknowledge):其他的许多方法不具有任务之间的全局潜在结构。
在学习新任务时,它们根据新任务的需要选择要使用的先验知识。这些只是被称为局部知识,不具有连续的全局结构。
局部知识可以跨领域共享。

终身情感分类
目标:将文档或句子分类为+或-。需要人工对每个领域的大量训练数据进行标记,这是很大的劳动量。
那么,我们可以不必为每个领域的数据进行标记,或至少减少要标记的文档/句子数量吗?

一种简单的LML方法
假设我们已经为大量过去的领域知识的所有数据D提供了标记:
使用D创建分类器,在新领域上测试(注意:由于迁移学习不能很好地工作,只使用一个过去域/源域)
在许多情况下,准确率可以提高多达19%(= 80%-61%)。为什么?
在其他情况下,结果不太好,例如,对于玩具的评论效果不好。为什么呢?

目标函数(见图)

通过惩罚开拓知识
两种类型的惩罚项分别是:
文档级的知识;
领域级的知识
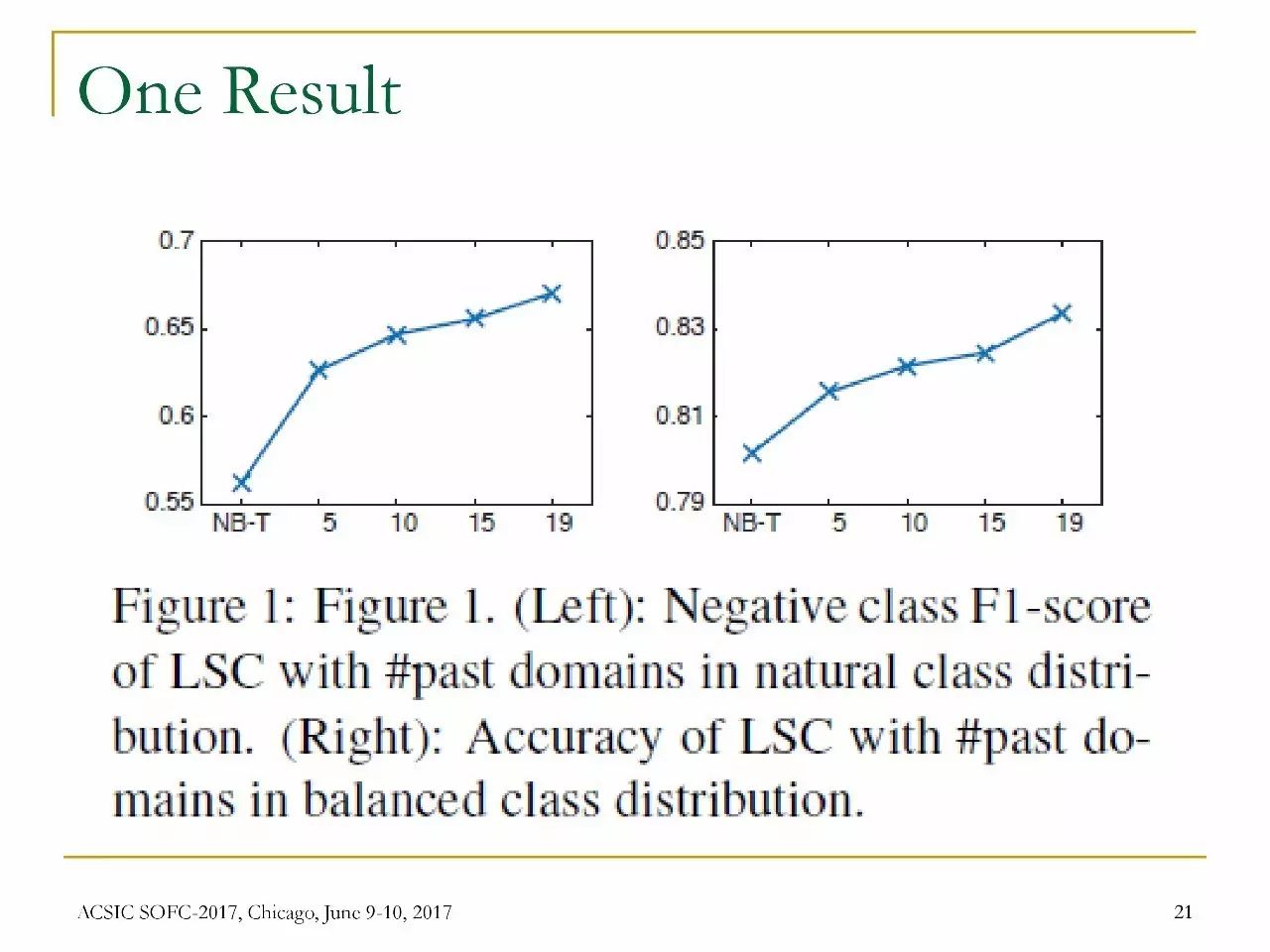
结果之一:
左图:在自然的类分布中具有#past域的LSC的负级F1分数。
右图:在均衡的类分布中具有#past域的LSC的准确率。

终身主题建模(LTM)
语句“电池很好,但拍照很差”,其中的主题项是:电池,拍照
提取主题实际上包含两个任务:
提取主题项:“图片”,“照片”,“电池”,“电源”
聚类(同义词分组):同样的aspects:{“图片”,“照片”},{“电池”,“电源”}
好的模型(Blei et al 2003)同时执行这两个任务。主题就是一个aspect,例如,{价格,成本,便宜,昂贵,...}

产品评论中的重点观察
在不同产品领域的评论中,相当多的主题重叠。
每个产品评论都有的aspect:价格;
大多数电子产品共享的aspect:电池性能;
其中很多产品也共享的aspect:屏幕。
这种跨领域的概念/知识共享是普遍的。
在学习中不利用这种共享就显得有点silly。

哪些知识?
属于同一个aspect/topic => Must-Links:e.g., {picture,photo}
不属于同一aspect/topic => Cannot-Links:e.g., {battery,picture}
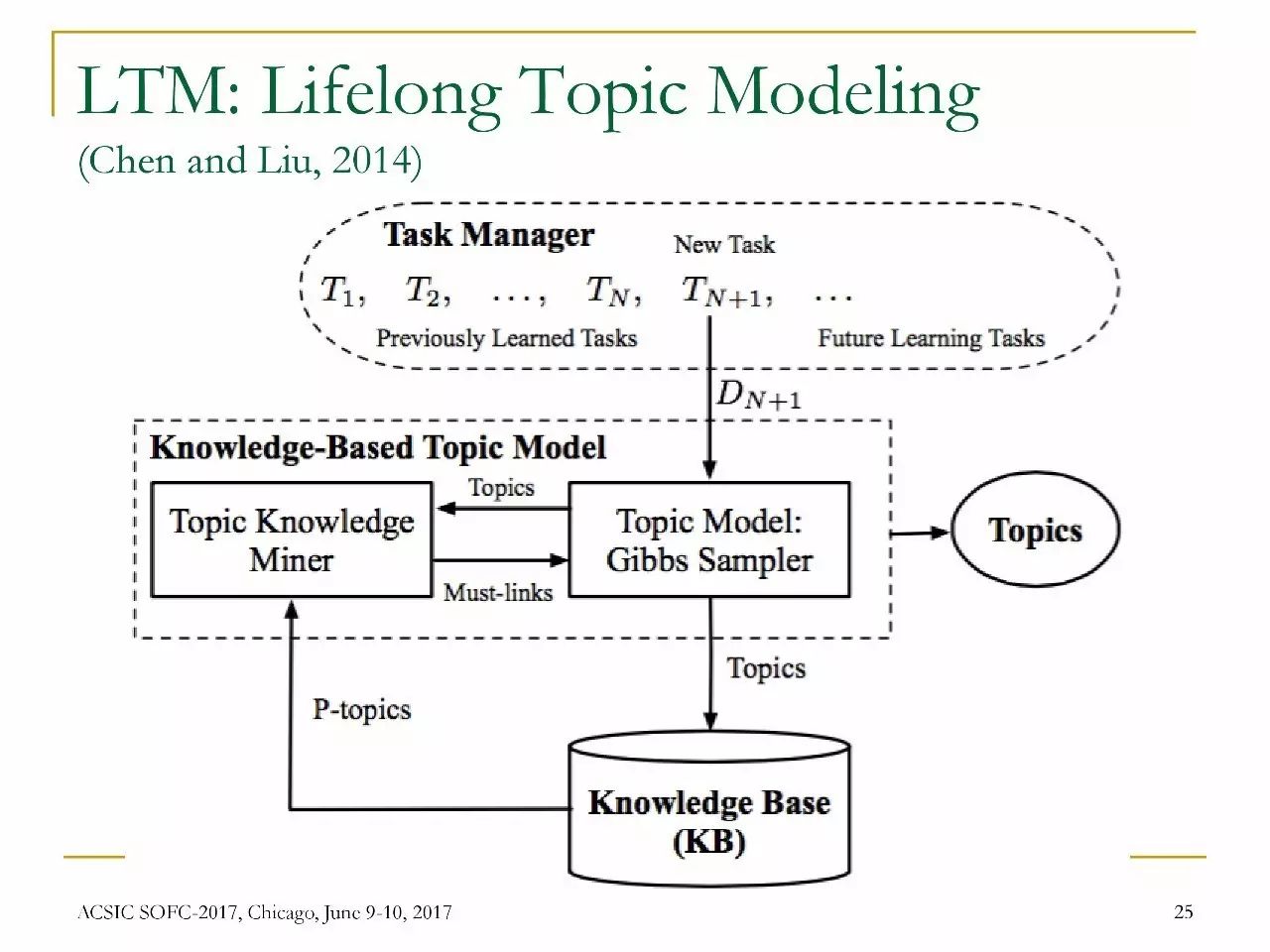
LTM:终身主题建模

方法:共享局部知识
来自先前任务/领域的一些知识可用于新任务,例如,{price,cost}和{price,expensive}应属于同一主题。

自觉积累的学习
传统的监督学习是一种封闭世界假说:测试中的类是训练中已经见过的,也就是说,测试数据里没有新的类。
这在许多动态环境中都是不真实的,新数据中可能包含新的文档类别。
我们需要在开放世界中进行分类,检测到新的文档类别,也就是说,既要记住已经知道的知识,也要探索未知的。
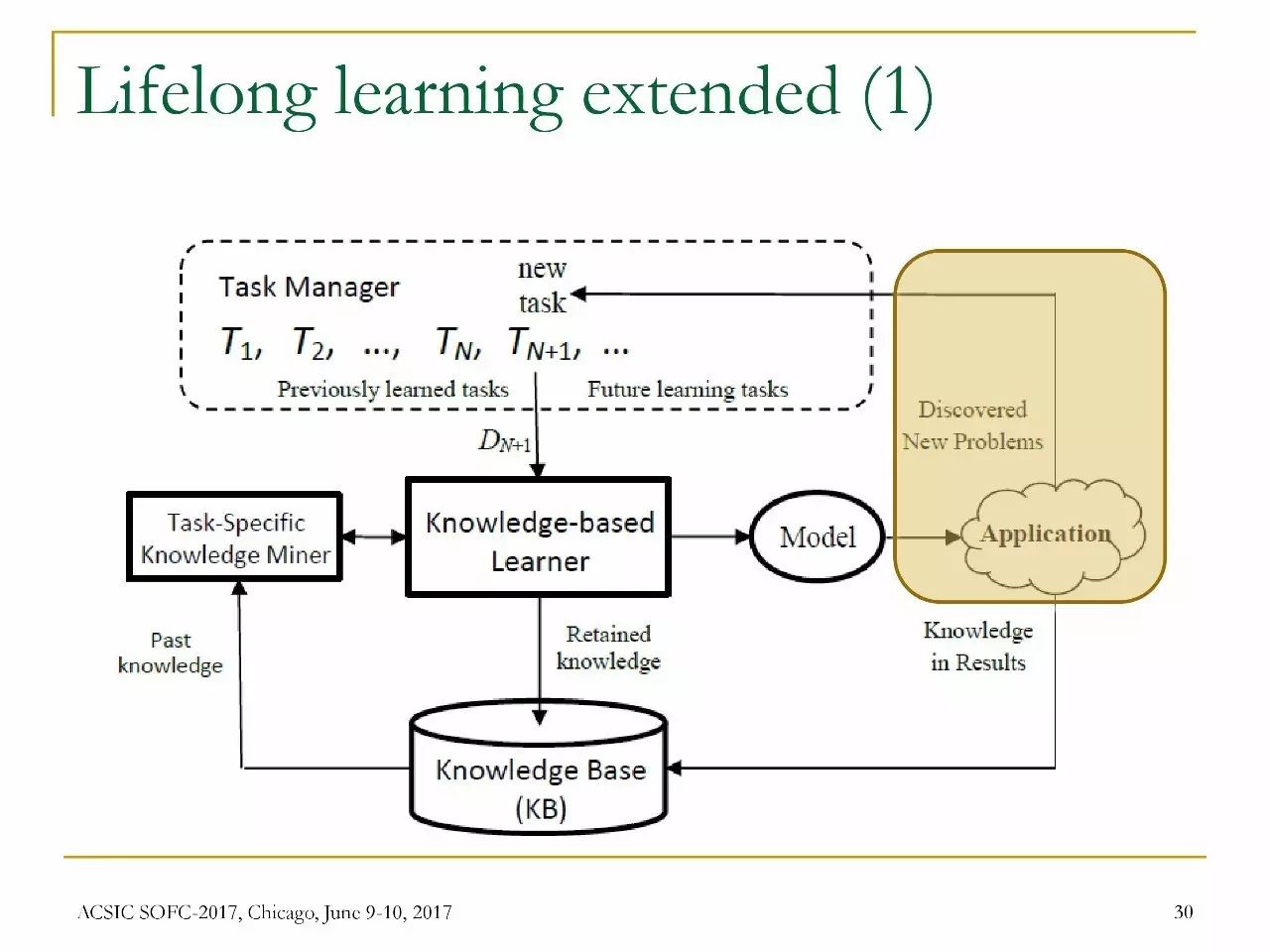
累积学习LML

在标签传播(labelpropagation)中的终身学习
松弛标记法(RelaxationLabeling, RL)是一种无监督的基于图的标签传播算法,它可以通过终身学习进行扩展(Lifelong-RL),以利用在以前的任务中学到的知识。



松弛标记法(RL)
图由节点(node)和边缘(edge)组成。
Node:要标记的对象
Edge:两个节点之间的二进制关系。

终身松弛标记法(Lifelong-RL)
Lifelong-RL使用两种形式的知识
先前的edge:图通常不是给定或固定的,而是基于文本数据构建的。如果数据很少,可能会丢失很多边缘,但这些边缘可能存在于以前的某些任务的图中。
先前的label:初始的P0(L(ni))很难设置,但是可以使用先前任务的结果更准确地进行设置。

从Lifelong-RL到SA任务
问题:观点目标标签
将entity和aspect分离,例如在“Although the engine is slightly weak, this car is great.”这个观点中,entity是“car”,aspect是“engine”。
目标提取(target extract)常常无法区分两者。
这个问题适合使用终身学习的方法:共享edge,entity和aspect,以及共享他们跨领域的label。
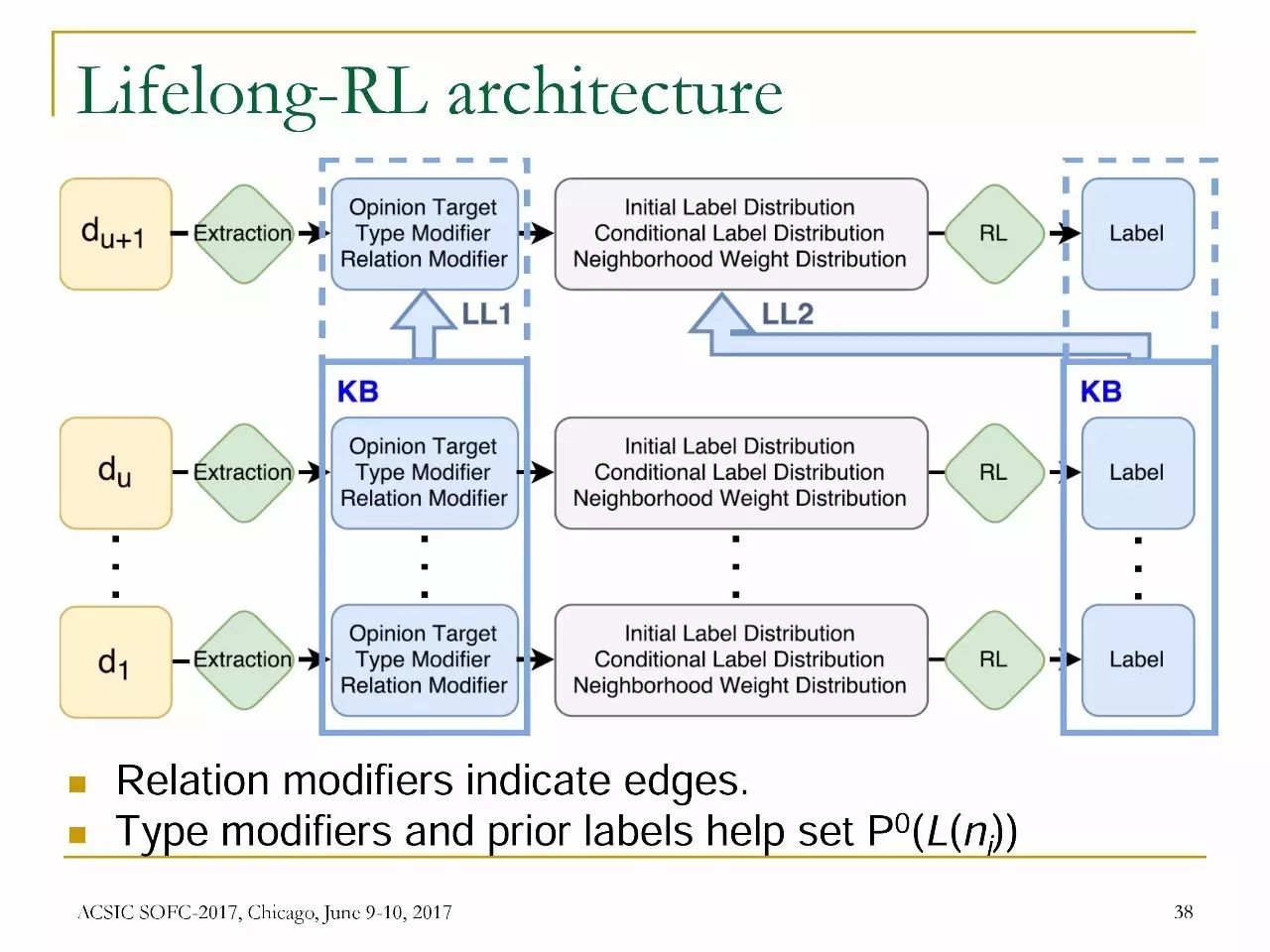
Lifelong-RL的架构(见图)
Relation modifier表示edge,Typemodifier和先前的label有助于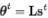

在执行中改进模型
在没用人工标记的标签的训练下,模型的性能可以提升吗?
本文提出了一种利用CRF信息提取的上下文中改进模型的技术。
它利用相依性特性,随着模型得到更多的数据,能有更多的特征被识别出来。这些特征有助于在新的领域使用相同的模型产生更好的结果。

本讲座简要介绍了在一些NLP应用中的LML
LML的研究现在还处于起步阶段,对LML的了解非常有限,目前的研究主要集中在只有一种类型任务的系统。LML需要大量数据,以学习大量不同类型的知识。

LML存在许多挑战,例如:
知识的正确性
知识的适用性
知识表达和推理
学习多种类型的任务
自我激励的学习
组合学习
在人与系统的交互中学习
(感谢施巍松、卢山两位老师在报道中提供的帮助!)

点击阅读原文查看新智元招聘信息



