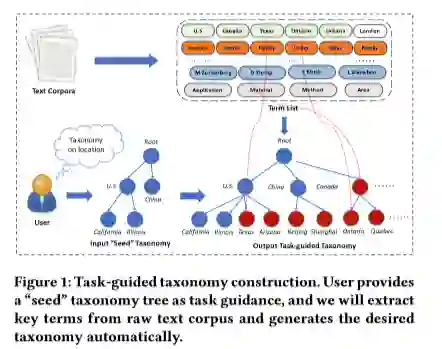
【论文笔记】韩家炜团队HiExpan:任务导向型分类树构建
【导读】 分类法对许多具有丰富知识的应用程序都具有巨大的价值。由于人工分类花费大量人力,所以构建自动分类 需求很大。然而,大多现存的自动分类构建方法只能建立上位分类,且每条边仅限于表达“is-a”关系。这样就限制了很多父子节点存在不同关系的任务。本篇论文,提出了一种新的方法(HiExpan)来自动生成术语列表并通过递归扩散来实现分类。
动机
2019/10/26
1)人工分类费时费力,不易改变,完成度低,因此构建自动分类法的需求很大
2)现存的大多数分类法基本都是基于“is-a”关系,获取上下位术语对,然后组成树。然而,这种方法不能满足存在复杂语义关系的结构,并且它的应用也十分有限。
因此,提出了一种新的方法(HiExpan),首先将用户提供的种子分类树作为任务指导,通过从语料库获取主要术语来自动生成并扩大分类树。
主要挑战
2019/10/26
一个术语可能会出现在分类树中的多个位置
初始分类树的分支较少
核心思想
2019/10/26
介绍一种研究人物导向的分类法构建,该构建以用户提供的种子分类和特定领域的语料库为输入,旨在输出满足用户特定的分类。
提出 HiExpan框架,分别从横向和纵向扩散分类树,并采用全局优化来调整分类树。
相关工作
2019/10/26

分层构建
常用的上下位词对关系获取的方法有两类:基于模式和分布式,然而这两类方法仅用于获取上下位词对,而我们主要是构建任务型分类,要获取明确的父子关系。对于这种结构性分类方法,首先要建立图结构,然后将图转换为树形分类。本篇论文中采用的方法是利用种子分类中的弱监督建立一个特定任务的分类法,其中的术语可以保持非上位关系,近一步,获取明确的关系并引入分类结构。
集合扩散
主要工作类似于将一个小的实体集扩展到一个完整的具有相同语义类别的实体集。除了增加新的实体到集合中,还需要将这些实体构建成树结构。
弱监督关系获取
与语料级关系获取的方法相似,从实体文本库中来获取关系,语料级关系获取有两种方法:基于模式,另一种是学习实体的低维特征表示,因为相似语义的实体就会有相似的表示。然而。这些方法在我们的设置中是不可行的,因为用户指定了有限的实体与实体之间的关系。此外这些方法没有考虑将关系对组织为分类结构。
符号说明
2019/10/26
文档语料D,种子分类(用户提供的初始分类),本篇论文的目的是将种子分类扩展成一个完整的分类T,每个节点e ∈ T代表从语料库D中获取的一个术语,边⟨e1, e2⟩表示满足明确关系的术语对,并使用E和 R来表示所有的节点和边。
框架介绍
2019/10/26
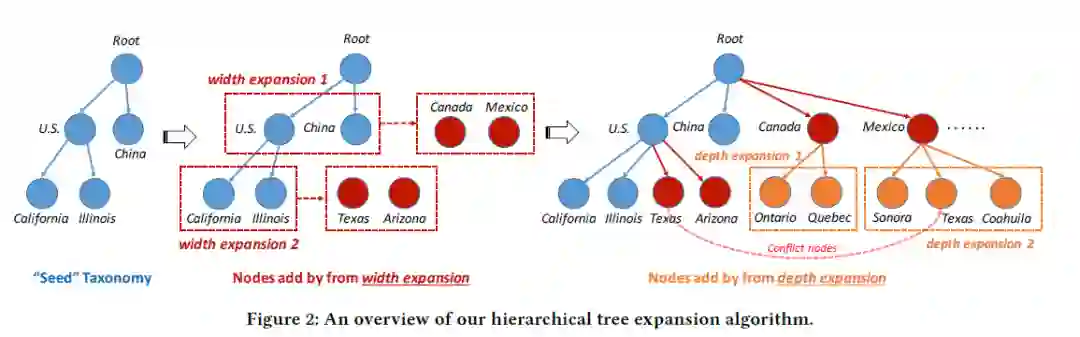
HiExpan可以在每个分类节点形成一个有关联的集合,比如那两个第一层节点(China和US),可以生成一个“country”语义类的集合,即其他国家的一个集合。相似的,在纵向方面,可以形成US的洲的集合。
对于给定的语料库D,可以通过短语挖掘工具来获取所有的关键术语,然后再分别使用两个方向的扩散(横向扩散和纵向扩散),最后,通过优化结构来调整分类树。
关键术语获取
使用AutoPhrase算法来挖掘语料库D,可以获得一个关键术语列表和识别每个关键术语在语料库中的出现;应用POS来获得每个关键术语的词性序列,并获得名词性标签的关键术语;最后将出现过至少一次的关键术语加入关键术语列表中。尽管这样生成的关键术语列表比较嘈杂,包含一些和任务无关的术语,召回比较关键,因为可以识别并简单地忽略在HiExpan的后期阶段的误报,但没有机会纠正错误排除于任务相关的术语。
等级树扩散
扩散算法是基于SetExpan与REPEL算法来实现的,之所以这样选择,是因为这两个算法在这个方向的应用效果很好。
横向扩散(查找同级节点)
基于SetExpan算法,合并术语嵌入特征,更好的利用实体特征。
三种特征类型:skip-pattern, term embedding 和 entity type
skip-pattern:
给定句子中的目标术语e_i,它的skip-pattern特征之一是“w−1___ w1”,这里引号中的w-1与w1是上下文词语,e_i为占位符“”,举例说明,术语“California”的skip-pattern的是句子“We need to pay California tax.”中的“pay___ tax”。
term embedding:
使用SkipGram 模型进行嵌入。对于一个术语中存在多个词,论文中使用“_”进行连接。术语嵌入特征可以学习到每个术语的特征。
entity type:
将每个实体的类型信息链接到Probase,返回类型用作该实体的特性。对于不可链接的实体,没有entity type的特性。
1)相似测量
计算两个同级实体的相似度是横向扩展算法的核心,首先在每个实体和skip-pattern之间分配权重:
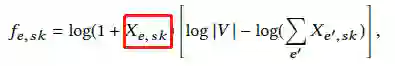
这里,红色框中表示的是e和sk同时出现的次数,|V|是候选实体的总数。
其次是定义实体和类型之间的权重:
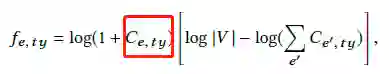
红框定义的是Probase返回的置信度,表示的是实体e具有类型ty的置信度。
最后,通过skip-pattern特征计算两个同级实体的相似度:
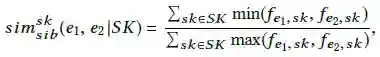
SK代表的是一组选定的skip-pattern特征,同样可以使用所有的类型特征来计算

最后,使用cosine相似度来计算两个基于嵌入特征的实体的相似度:
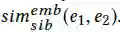
为了结合以上三个相似度,使用了一个如下方法来计算同级相似度:
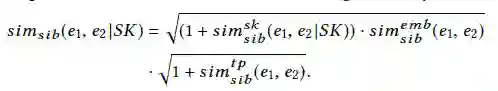
2)横向扩展过程
给定一个种子实体集S和一个候选实体列表V,一个直接方法就是计算每个候选实体与种子实体之间的实体平均相似度。然而这种方法可能会出现问题,因为(1)特征多且杂,(2)候选实体可能与种子实体不相关。因此,提出首先选择一组质量skip-pattern特征,然后判断实体与任一skip-pattern特征是否相关联,如果关联就对其打分。
从种子集S开始,首先计算每个skip-pattern特征和S中实体的分数,然后选择得分高的前200个skip-pattern特征,此后,使用不替代采样方法来生成10个skip-pattern特征子集SK_t(t=1,2,3,……,10),每个子集有120个skip-pattern特征。
给定一个SKt,如果与SKt中的至少一个特征有关联就把它视为V中的候选实体,候选实体的分数计算:

对于每个SKt,可以获得一个基于分数的候选实体等级列表,使用r_ti表示列表L_t中的实体e_i的等级,如果在列表中不存在实体,就用r_ti=∞表示。最后,计算每个实体的平均倒数mrr,并且将平均排名高于r的实体添加到集合S中。
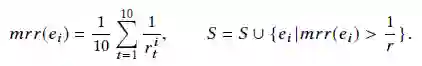
上述的关键点是无关实体不会频繁出现在多个L_t的顶部位置,因此可能具有较低的mmr得分。
纵向扩展
通过处理同级节点和niece/nephew节点之间的关系来获得目标节点的最初子节点。例如,节点“Canada”,为了得到他的初代子节点“Ontario” 和 “Quebec“,就要学习它的同级节点”U.S.“与它的子节点”California”和“Illinois“之间的关系。
这个算法依赖于术语嵌入,使用v(t)表示术语t的嵌入,两个术语嵌入的偏移量表示它们之间的关系,这样就出现了接下来的表示:

因此,给出一个父节点et,一系列父子节点集合E={<e_p,e_c>},e_p是父节点,e_c是子节点,为了计算et对应的子节点e_x:
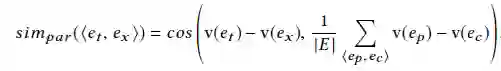
计算所有的候选节点ei的simpar(<e_t,e_i>),并选出top3作为父节点e_t的初代子节点。
术语嵌入是来自于REPEL,是一个使用Pattern-enhanced Embedding Learning的弱监督关系获取的模型。它输入的少数种子关系术语,输出术语嵌入和目标关系类型的可靠关系短语。
解决冲突
这里的冲突指的是,当同一个术语出现多个不同的位置。通过找到最好的位置来解决这样的冲突。
给出一组冲突节点数据集C,对应的是同一个实体的不同位置,通过以下三个步骤来选择这个集合中的最好的节点。
如果C中的任一节点是中的节点,直接选择这个节点并跳过以下两个步骤,反之,C中的每队节点要检查其中一个节点是否是另一个节点的父节点,并保留父节点。
计算每个留下来的节点e∈ C的自信度
最后,没有被选择的节点,将会删除由它产生的子树,以及在它之后产生的同级节点。
总结

算法1表示了整个等级树扩散的过程,从树的根部开始扩散每个节点的子级。当发现目标节点没有子节点时,首先纵向获得它的初代子节点然后使用横向扩展获得更多的子节点。每次迭代的过程中,会解决所有的冲突节点,当扩展到做大上限时,迭代过程终止,并返回最终的扩散分类树。
分类全局优化
2019/10/26
在算法1中,节点基于同级节点和父节点的局部相似度分类,这种局部相似度可能会简化树扩散的过程,发现橙橙的分类效果似乎并不是最好的。例如,节点法国,“Molise”被错误的添加到了法国这个节点下,这很可能是因为该实体与法国的其他地区有许多相似的背景。然而,当我们以更全面的角度来看,对于问题“Molise位于哪个国家”,我们可以很轻易的说出“意大利”,那是因为,“Molise“和意大利有更多的相似之处。因此,提出了一种分类全局优化模块。
该模块主要是为了调整分类树中的两个连续级别,找到最好的父节点。分类全局优化的两个期许:
1)有相同父节点的实体彼此之间十分相似并形成一个集合
2)每个实体与父节点之间的相似度要比与其同级节点之间的相似度高
假设有m个父节点,n个子节点,用W表示同级节点的相似度,用Y^c表示跨级节点的相似度。如果i,j不相等,W_{ij}=simsib(ei,ej),否则,W_ii=0,Yc_{ij}=sim_par(<e_j,e_i>)。如果子节点e_i在父节点e_j的下面就用Ys{ij}=1,反之Y^s{ij}=0。F表示子节点的父级分配。最后提出了一个优化公式:
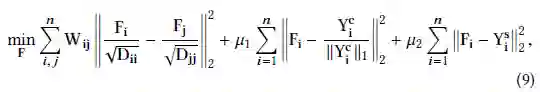
D_ii表示的是W的第i行之和,μ为超参数。上式中的第一个加数对应第一个期许,第二个加数对应第二个期许,最后一项用来约束并获得全局优化前的分类结构信息。
为了解决优化问题,还提出了一个目标函数的倒数:
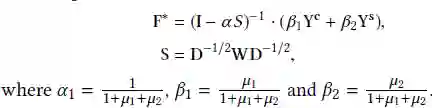
实验
2019/10/26
实验设置
数据集:使用3个不同领域的语料库(156k DBLP的摘要、Wiki、463K PubMedCVD摘要)
baselines:因为是第一次做这种分类,没有合适的baselines,因此用基于受启发的模型开展的方法以及自身的变体来进行比较。(HSetExpan、NoREPEL、NoGTO)
参数设置:使用AutoPhrase时频率为15,REPEL和 SkipGram嵌入维度为100,max_iter=5,μ1 = 0.1, μ2 = 0.01。
定性结果
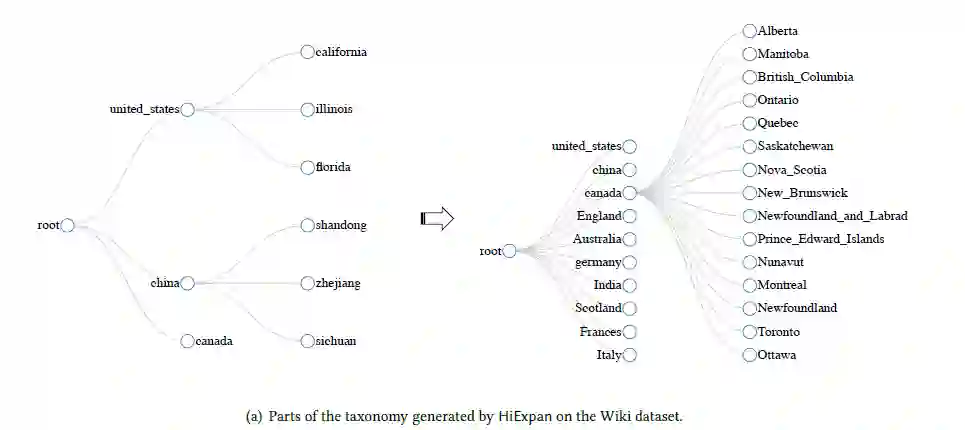

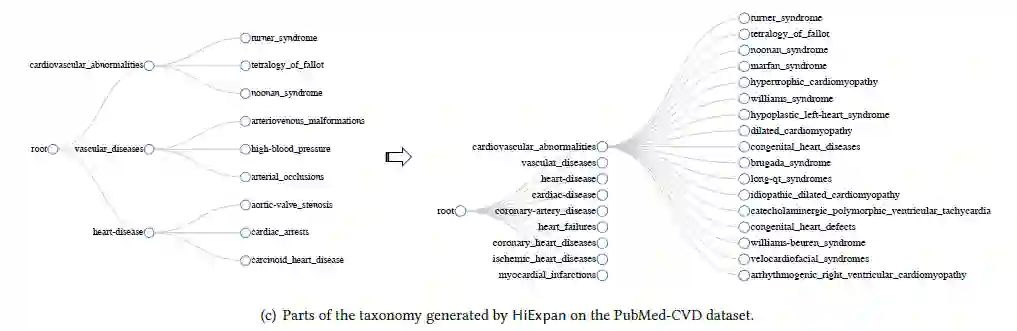

定量结果
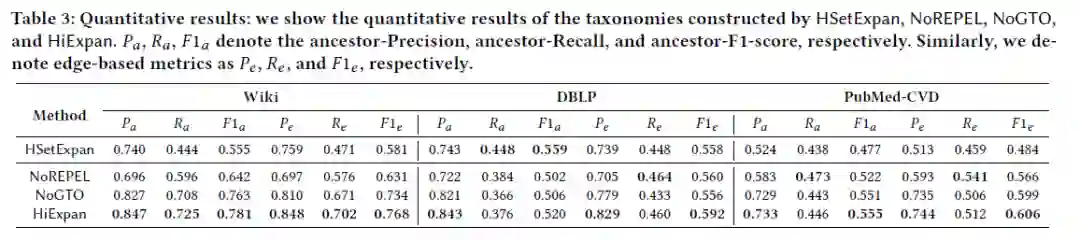
使用Ancestor-F1和 Edge-F1来评估结果。Ancestor-F1用来测量正确的父子关系,Pa为准确率,Ra为召回率,F1a为F1-score。Edge-F1与Ancestor-F1相似。

通过作者团队的努力得到了以下的评估数据:
总结
2019/10/26
提出了一种新颖的以task-guided主导的分类方法
提出了一种基于扩散的框架:HiExpan
采用弱监督的提取模块来推断父子
通过优化全局结构来调整分类树







