旷视研究院新出8000点人脸关键点,堪比电影级表情捕捉
导语
还记得创造了票房神话的电影《阿凡达》吗?其中最吸睛的技术,便是逼近真人水准的 CG 表情。当时,导演卡梅隆专门发明了一种带固定摄像头的特殊头盔,并在演员脸上绘制了许多绿点,用来追踪表情。这些“绿点”数据经过一系列复杂的处理,最终由电脑合成到虚拟角色上,成就了栩栩如生的 CG 表情。

《阿凡达》中复杂的表情捕捉系统
而如今,随着深度学习的发展,表情捕捉将不再需要笨重的设备和繁琐的流程。旷视研究院LLCV 组推出的“8000 点人脸关键点技术”,可以完美替代人脸上的“小绿点”,在手机上就可以实现精准的表情捕捉。
旷视研究院 LLCV 组的“8000点人脸关键点技术”,以单张彩色图像或单段视频作为输入,提取出面部稳定鲁棒的 8000 个 3D 关键点。通过 10,000,000 张人脸数据的训练,该技术可以精细刻画全脸 3D 特征,支持全方位姿态、各种极端表情,并且能在移动端平台实时运行。下方是三段demo。

夸张表情,惟妙惟肖

下左右,全无死角
手机实测,又快又好
简介
在计算机视觉领域,人脸关键点定位一直是一个重要的话题。它是许多人脸技术和应用的基础。随着研究者的努力,一些形式简单的人脸关键点已经做的比较成熟,并已成功运用到诸多具体领域中,例如人脸识别,拍照美颜等。
现存的一个问题在于,所有现有方法都着力于“五官”等图像特征语义明显的部位,比如眼睛,鼻子,嘴巴;但是对一些“定义模糊”、或图像特征不明显的区域却束手无策,如眼袋,法令纹,颧骨,苹果肌等。可以说,人脸关键点技术仍然缺乏一种针对整张脸的分析手段。
旷视研究院 LLCV 组推出的“8000 点人脸关键点技术”,首次填补了这一空缺,让关键点覆盖全脸无死角。

基于3DMM的8000关键点定位方法
量变引起质变。半年前 LLCV 组推出了 1000 关键点,重在描述人脸的轮廓线,是由点到线的升级。而现今 LLCV 组推出的 8000 关键点,可以清晰描述人脸 3D 曲面信息,是从线到面的再次升级。
8000 点不只是简单的数量提升,它相比于前两者的难点在于:其中许多点并没有明确的语义信息,人都无法准确定义。因此,用神经网络直接预测所有点的坐标是非常难的一件事。为了解决这一难点,LLCV 组引入了名为 3D Morphable Model(3DMM)的人脸经验模型。
3DMM经验模型
3DMM 是一类参数化人脸模型的统称,它最早在 1999 年由一篇名为《A Morphable Model For The Synthesis Of 3D Faces》的论文提出,后续大多是基于这一工作的改进。现今常见的人脸模型包括 Basel Face Model(BFM)、FaceWarehouse、Large Scale Facial Model (LSFM)等等。
3DMM 的核心思想是:把人脸 3D 模型参数化。以人脸形状为例,参照下述公式,任何一个人的 3D 人脸形状都可用一个平均人脸形状和一些表示人脸特征的特征向量线性组合而成。
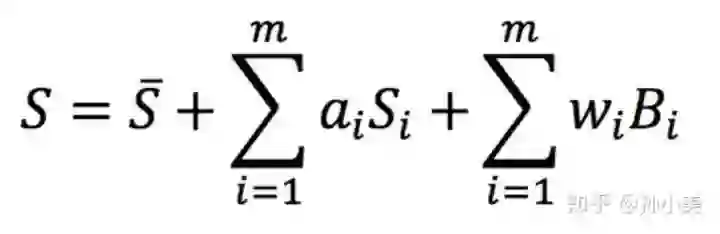
其中 





3DMM人脸参数调制示意图
调制参数求解
将 8000 点人脸关键点与 3DMM 进行映射之后,求解 8000 点的问题转化成求解 3DMM 调制系数的问题。同时为了让 2D 与 3D 结合,LLCV 组还需要考虑相机参数。这类问题的常见解决方法是制定如下所示的损失函数,并使用解最优化问题的方法。
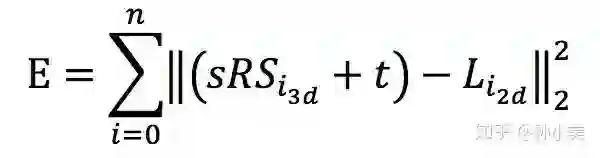
其中 { 


这个算法准确度非常高,但损失函数的繁琐决定了算法的高复杂度。使用该方法在 PC 端对一张人脸进行建模需要 2 分钟左右。
深度学习端到端训练
为了令上述方法能在手机端实时运行,旷视研究院采用了神经网络端到端学习,如下图所示。神经网络具备强大的学习能力,省略了凸优化算法中繁琐费时的迭代过程,端到端的直接学会了如何从一张人脸直接预测出其所需要的调制参数。
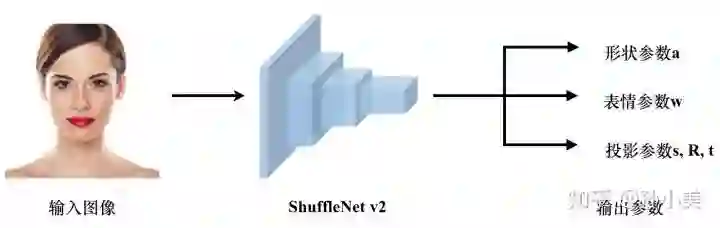
网络结构示意图
数据方面,为了让最终结果对光照、姿态、表情、遮挡等与人脸相关的因素都足够鲁棒,LLCV 组使用了旷视内部 10,000,000 规模的人脸数据集进行训练。
网络结构方面,LLCV 组使用旷视研究院最新版本的 ShuffleNet V2 网络结构。ShuffleNet V2 是针对移动端设计的高效卷积神经网络结构,它在速度和精度上均超越了同规模的 SOTA 网络(如旷视的 ShuffleNet V1,谷歌的 MobileNets, 微软亚研院的 IGV3 等)。
损失函数方面,LLCV 组在形式上与传统解优化方法一致,但是将网络的输出变为语义信息差距很大的三部分:形状参数 a、表情参数 w 和投影系数 {s,R,t}。为了让神经网络更好更快收敛,LLCV 组将三部分分开计算 Loss,即每部分使用损失函数计算 Loss 时,另外两部分都使用ground truth。同时,这三部分各自的 Loss 以动态权重加权成最终的损失函数。
最终训练的神经网络模型运算量为 32 MFLOPS,在中端处理器骁龙660 上的平均运行时间为:10.5ms,而在高端处理器骁龙855 上的平均运行时间可达:4ms,帧速率 250fps。
得到了调制参数,即可使用调制参数生成定制的人脸 3D 模型,进一步根据映射关系就可以得到人脸的 3D 关键点。显然,这里的人脸关键点都是 3D 的,每个关键点的坐标为 (x,y,z),它对人脸的描述更加合理,可以保证人脸在不同姿态时,每个关键点都保证自己的语义一致。
结论
8000 点人脸关键点,是从感知点到线再到面的进步,是从 2D 技术到 3D 技术的升级。在数字化世界逐渐完善的过程中,3D 技术是推进工业化和信息化“两化”融合的发动机。以 8000 点人脸关键点为代表的一系列 3D 技术,终将为旷视驱动百亿智能设备的愿景添一份助力。
参考文献
[1] V. Blanz and T. Vetter, "A morphable model for the synthesis of 3D faces", In Proceedings of the 26th annual conference on Computer graphics and interactive techniques, 1999
[2] P. Paysan, R. Knothe, B. Amberg, S. Romdhani and T. Vetter, "A 3D Face Model for Pose and Illumination Invariant Face Recognition", In Advanced video and signal based surveillance, 2009
[3] J. Booth, A. Roussos, S. Zafeiriou, A. Ponniah and D. Dunaway, "A 3D Morphable Model learnt from 10,000 faces", In Computer Vision and Pattern Recognition (CVPR), 2016
[4] J. Booth, A. Roussos, A. Ponniah, D. Dunaway and S. ZafeiriouLarge scale, "3D Morphable Models ", In International Journal of Computer Vision (IJCV), 2017
[5] C. Chen, Y. Weng, S. Zhou, Y. Tong and K. Zhou, "FaceWarehouse: a 3D Facial Expression Database for Visual Computing", In IEEE Transactions on Visualization and Computer Graphics, 20(3): 413-425, 2014
[6] N. Ma, X. Zhang, H. Zheng and J. Sun, "ShuffleNet V2: Practical Guidelines for Efficient CNN Architecture Design", In European Conference on Computer Vision (ECCV), 2018
@知乎:孙伟
版权声明
本文版权归《孙伟》,转载请自行联系。

历史文章推荐:
加州伯克利大学计算机系是如何培养计算机人才的?
CVPR2019 | 最新高效卷积方式HetConv
合集下载 | 2018年图灵奖得主“深度学习三巨头”主要贡献和代表性论文
火爆GitHub的《机器学习100天》,有人把它翻译成了中文版!
如何学会看arxiv.org才能不错过自己研究领域的最新论文?
机器学习中的最优化算法总结
深度学习500问!一份火爆GitHub的面试手册
深度学习最常见的 12 个卷积模型汇总,请务必掌握!
CVPR2019 | 专门为卷积神经网络设计的训练方法:RePr
深度神经网络模型训练中的最新tricks总结【原理与代码汇总】
基于深度学习的艺术风格化研究【附PDF】
最新国内大学毕业论文LaTex模板集合(持续更新中)
你正在看吗?👇




