当大火的文图生成模型遇见知识图谱,AI画像趋近于真实世界

本文作者:朱祥茹、段忠杰、汪诚愚、黄俊
导读
ARTIST模型详解
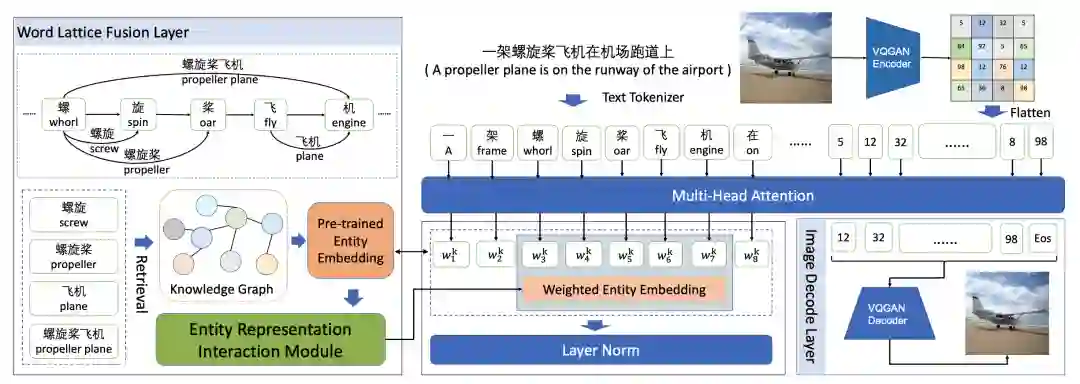
第一阶段:基于VQGAN的图像矢量量化
第二阶段:以文本序列为输入利用GPT生成图像序列
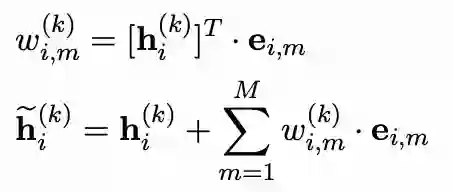
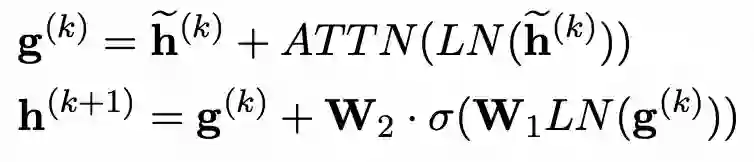
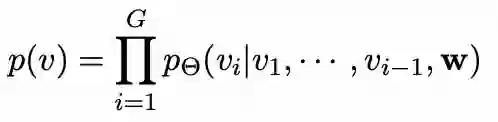
ARTIST模型效果
标准数据集评测结果


案例分析


|
|
|
|
|
|


|


|
|
|
|
|
|
|


|


|
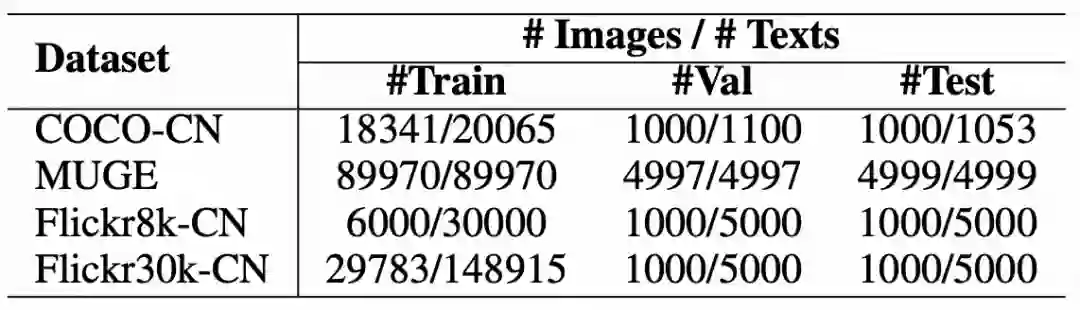
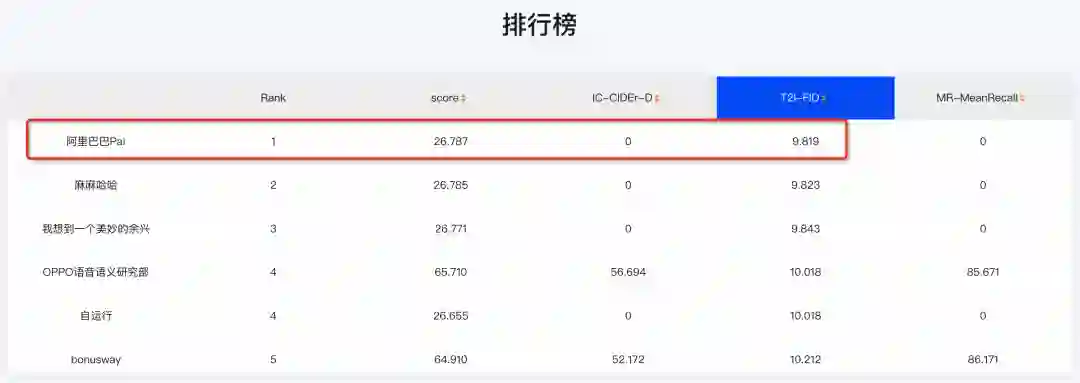
ARTIST模型在MUGE榜单的评测结果
ARTIST模型的实现
# in easynlp/appzoo/text2image_generation/model.py# initself.transformer = GPT_knowl(self.config)# forwardx = inputs['image']c = inputs['text']words_emb = inputs['words_emb']x = x.permute(0, 3, 1, 2).to(memory_format=torch.contiguous_format)# one step to produce the logits_, z_indices = self.encode_to_z(x)c_indices = ccz_indices = torch.cat((c_indices, a_indices), dim=1)# make the predictionlogits, _ = self.transformer(cz_indices[:, :-1], words_emb, flag=True)# cut off conditioning outputs - output i corresponds to p(z_i | z_{<i}, c)logits = logits[:, c_indices.shape[1]-1:]
在数据预处理过程中,我们需要获得当前样本的输入文本和实体embedding,从而计算得到words_emb:
# in easynlp/appzoo/text2image_generation/data.py# preprocess word_matrixwords_mat = np.zeros([self.entity_num, self.text_len], dtype=np.int)if len(lex_id) > 0:ents = lex_id.split(' ')[:self.entity_num]pos_s = [int(x) for x in pos_s.split(' ')]pos_e = [int(x) for x in pos_e.split(' ')]ent_pos_s = pos_s[token_len:token_len+self.entity_num]ent_pos_e = pos_e[token_len:token_len+self.entity_num]for i, ent in enumerate(ents):words_mat[i, ent_pos_s[i]:ent_pos_e[i]+1] = entencoding['words_mat'] = words_mat# in batch_fnwords_mat = torch.LongTensor([example['words_mat'] for example in batch])words_emb = self.embed(words_mat)
ARTIST模型使⽤教程
安装EasyNLP
数据准备
-
准备自己的数据,将image编码为base64形式:ARTIST在具体领域应用需要finetune, 需要用户准备下游任务的训练与验证数据,为tsv文件。这⼀⽂件包含以制表符\t分隔的三列(idx, text, imgbase64),第一列是文本编号,第二列是文本,第三列是对应图片的base64编码。样例如下:
64b4109e34a0c3e7310588c00fc9e157 韩国可爱日系袜子女中筒袜春秋薄款纯棉学院风街头卡通兔子长袜潮 iVBORw0KGgoAAAAN...MAAAAASUVORK5CYII=
https://atp-modelzoo-sh.oss-cn-shanghai.aliyuncs.com/release/tutorials/artist_text2image/T2I_train.tsvhttps://atp-modelzoo-sh.oss-cn-shanghai.aliyuncs.com/release/tutorials/artist_text2image/T2I_val.tsvhttps://atp-modelzoo-sh.oss-cn-shanghai.aliyuncs.com/release/tutorials/artist_text2image/T2I_test.tsv
-
将输入数据与lattice 、entity位置信息拼接到一起 :输出格式为以制表符\t分隔的几列(idx, text, lex_ids, pos_s, pos_e, seq_len, [Optional] imgbase64)
# 下载entity to entity_id映射表wget wget -P ./tmp https://atp-modelzoo-sh.oss-cn-shanghai.aliyuncs.com/release/tutorials/artist_text2image/entity2id.txt
python examples/text2image_generation/preprocess_data_knowl.py \ --input_file ./tmp/T2I_train.tsv \ --entity_map_file ./tmp/entity2id.txt \ --output_file ./tmp/T2I_knowl_train.tsv
python examples/text2image_generation/preprocess_data_knowl.py \ --input_file ./tmp/T2I_val.tsv \ --entity_map_file ./tmp/entity2id.txt \ --output_file ./tmp/T2I_knowl_val.tsv
python examples/text2image_generation/preprocess_data_knowl.py \ --input_file ./tmp/T2I_test.tsv \ --entity_map_file ./tmp/entity2id.txt \ --output_file ./tmp/T2I_knowl_test.tsv
ARTIST文图生成微调和预测示例
# 下载entity_id与entity_vector的映射表wget -P ./tmp https://atp-modelzoo-sh.oss-cn-shanghai.aliyuncs.com/release/tutorials/artist_text2image/entity2vec.pt# finetunepython -m torch.distributed.launch $DISTRIBUTED_ARGS examples/text2image_generation/main_knowl.py \--mode=train \--worker_gpu=1 \--tables=./tmp/T2I_knowl_train.tsv,./tmp/T2I_knowl_val.tsv \--input_schema=idx:str:1,text:str:1,lex_id:str:1,pos_s:str:1,pos_e:str:1,token_len:str:1,imgbase64:str:1, \--first_sequence=text \--second_sequence=imgbase64 \--checkpoint_dir=./tmp/artist_model_finetune \--learning_rate=4e-5 \--epoch_num=2 \--random_seed=42 \--logging_steps=100 \--save_checkpoint_steps=200 \--sequence_length=288 \--micro_batch_size=8 \--app_name=text2image_generation \--user_defined_parameters='pretrain_model_name_or_path=alibaba-pai/pai-artist-knowl-base-zhentity_emb_path=./tmp/entity2vec.ptsize=256text_len=32img_len=256img_vocab_size=16384# predictpython -m torch.distributed.launch $DISTRIBUTED_ARGS examples/text2image_generation/main_knowl.py \--mode=predict \--worker_gpu=1 \--tables=./tmp/T2I_knowl_test.tsv \--input_schema=idx:str:1,text:str:1,lex_id:str:1,pos_s:str:1,pos_e:str:1,token_len:str:1, \--first_sequence=text \--outputs=./tmp/T2I_outputs_knowl.tsv \--output_schema=idx,text,gen_imgbase64 \--checkpoint_dir=./tmp/artist_model_finetune \--sequence_length=288 \--micro_batch_size=8 \--app_name=text2image_generation \--user_defined_parameters='entity_emb_path=./tmp/entity2vec.ptsize=256text_len=32img_len=256img_vocab_size=16384max_generated_num=4'
在阿里云机器学习平台PAI上使用Transformer实现文图生成
未来展望
Reference
-
Chengyu Wang, Minghui Qiu, Taolin Zhang, Tingting Liu, Lei Li, Jianing Wang, Ming Wang, Jun Huang, Wei Lin. EasyNLP: A Comprehensive and Easy-to-use Toolkit for Natural Language Processing. EMNLP 2022 -
Tingting Liu*, Chengyu Wang*, Xiangru Zhu, Lei Li, Minghui Qiu, Ming Gao, Yanghua Xiao, Jun Huang. ARTIST: A Transformer-based Chinese Text-to-Image Synthesizer Digesting Linguistic and World Knowledge. EMNLP 2022 -
Aditya Ramesh, Mikhail Pavlov, Gabriel Goh, Scott Gray, Chelsea Voss, Alec Radford, Mark Chen, Ilya Sutskever. Zero-Shot Text-to-Image Generation. ICML 2021: 8821-8831
[1]https://zhuanlan.zhihu.com/p/547063102
[2]https://github.com/alibaba/EasyNLP
[3]https://zhuanlan.zhihu.com/p/547063102
[4]https://tianchi.aliyun.com/dataset/dataDetail?dataId=107332
[5]https://help.aliyun.com/document_detail/194831.html
[6]https://pai.console.aliyun.com/?regionId=cn-shanghai#/dsw-gallery-workspace/preview/deepLearning/nlp/easynlp_text2image_generation
登录查看更多
相关内容
Arxiv
23+阅读 · 2019年11月5日
Arxiv
11+阅读 · 2018年5月9日


相关VIP内容
相关资讯
相关论文
Arxiv
23+阅读 · 2019年11月5日
Arxiv
11+阅读 · 2018年5月9日