把握市场趋势和波动——基于EMD算法的日内趋势策略

为中国的量化投资事业贡献一份我们的力量!


前言
本文主要基于广发证券研报《经验模态分解下的日内趋势交易策略》的思路进行实证研究,本文的主要内容包括:
1)EMD算法及数值实验。
2)EMDT策略及参数确定。
3)策略回测及评价。
一、EMD算法及数值实验
经验模态分解(Empirical Mode Decomposition,EMD)方法是由美国航空航天局(NASA)的黄锷院士提出的一种处理非平稳和非线性信号的分析方法。与一般的信号处理方法不同,EMD是一种自适应的分析方法,即依据数据自身的时间尺度特征来进行信号分解。简单地说,EMD是一种去除噪声和短期波动的算法,具有算法简单、延迟性低等特点。
1.1 EMD算法简介
经验模态分解假设任何复杂的信号都是由一些不同的“波动项”和一个“趋势项”组成。这些波动项被称为本征模态函数(IMF),即复杂信号
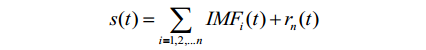
其中IMF需满足以下两个条件:
函数的局部极大值和局部极小值的数目之和与零点的数目相等或者只能差1,即一个极值之后必需马上接一个零点。
在任何时间点,局部最大值所定义的上包络线与局部极小值所定义的下包络线,取平均要接近于零。
算法步骤:
输入:原始信号s。
输出:本征模态函数IMF1,IMF2,…,IMFn和趋势项r。
step1:找出s中的所有局部极大值和局部极小值。
step2:利用三次样条插值函数,分别将局部极大值串联成信号的上包络线,局部极小值串联成下包络线。
step3:求出上下包络线的平均值m1,。
step4:令h1=s-m1,检查h1是否满足IMF条件,如未满足则用h1替代原始信号s,回到step1,直到hk满足IMF条件。
step5:将hk作为IMF1,令r1=s-IMF1,判断r是否单调,如不单调则以r1作为原始信号回到step1,直到rn单调为止,从而获得趋势项。
1.2 关于EMD算法的数值实验
本部分关于EMD算法效果的实验分为单IMF信号、多IMF信号和带噪多IMF信号三个部分进行。
1)单IMF信号
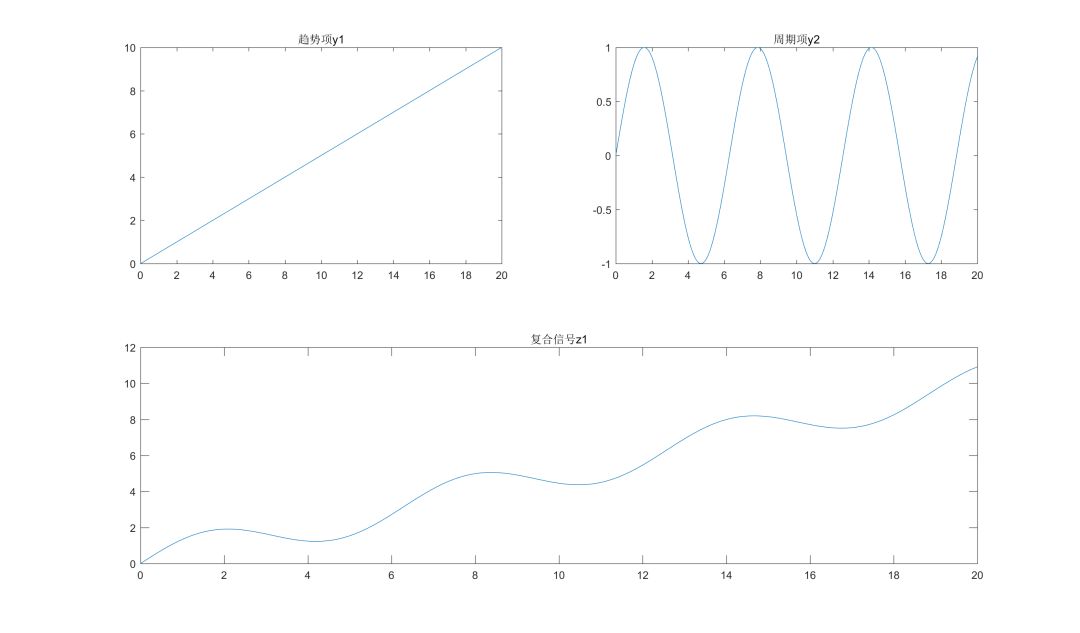
取趋势项y1=0.5*x,周期项y2=sin(x),复合信号z1=y1+y2,分别如下图所示:
经EMD算法提取的本征模态函数IMF和趋势项r分别如下图所示:
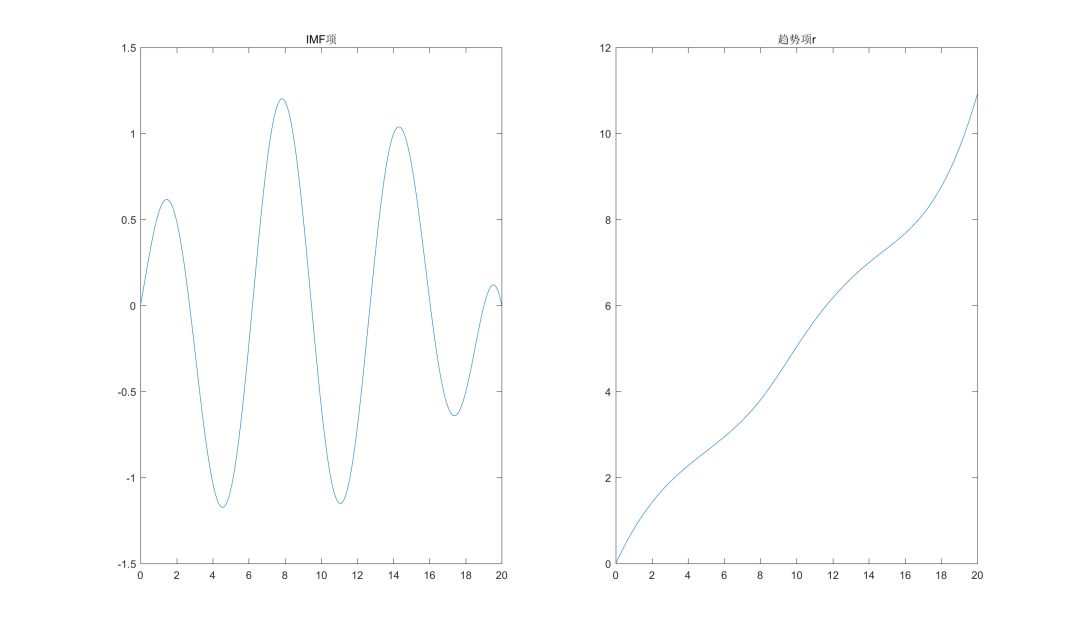
从结果上看,虽然与实际信号存在一定的出入,但EMD算法还是较好地分离了趋势信号和周期信号。另外,关于实验需要说明的是:由于IMF的第二个条件要求h的上下包络线的均值在任意位置都接近于0,关于该条件在程序中的量化,笔者考虑为上下包络线均值的最大值小于h绝对值均值的某一阈值alpha。上图是当alpha取0.1时的结果,此时h发生了5次迭代(过程数据未给出,感兴趣的读者可自行实验),直观上,alpha取值越小,信号的分解可能会越精确,但相对地,计算代价也会越大,对此,需要使用者根据实际情况进行权衡。
2)多IMF信号
在 1)的情况下增加周期项y3=cos(2*x),即复合信号z2=z1+y3,如下图所示:
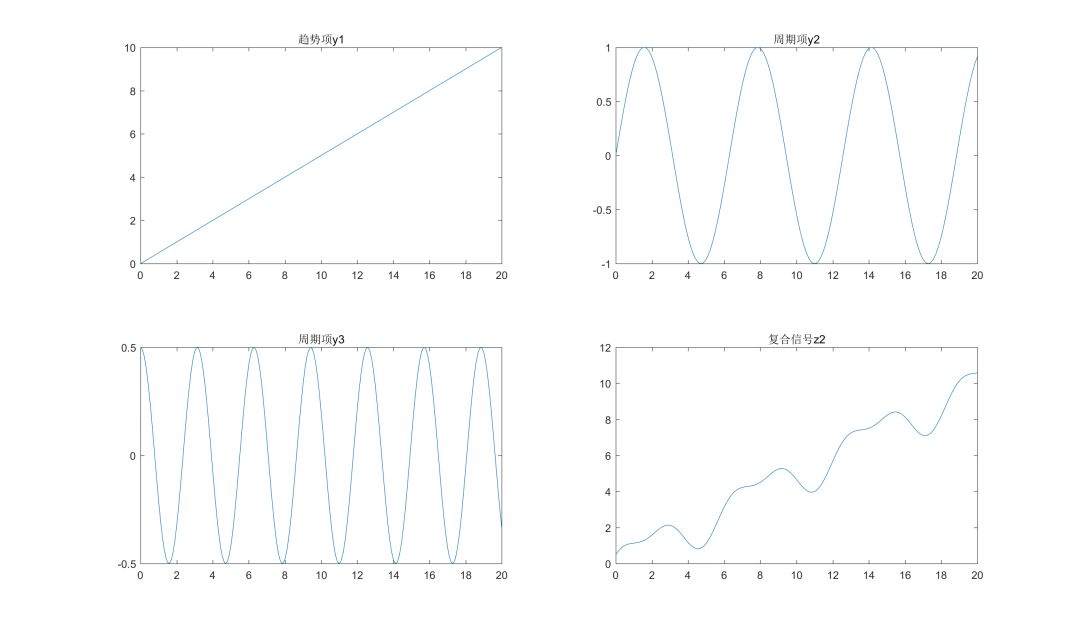
使用EMD算法分解后的IMF项和趋势项r分别如下所示:
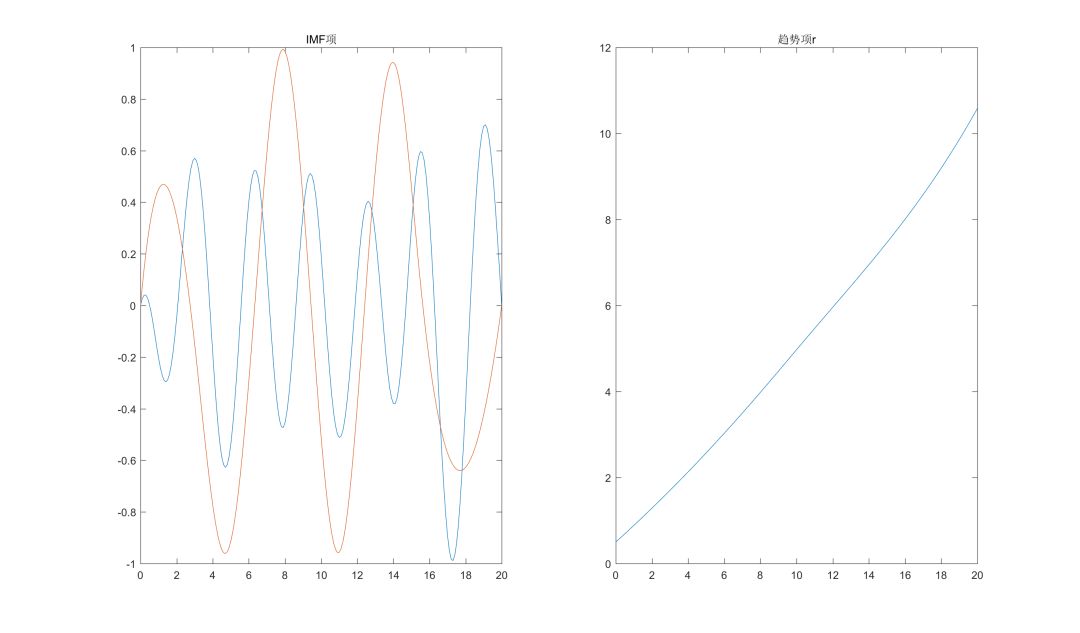
总的来说,算法对于三种信号的还原还是比较准确的。
3)带噪的多IMF信号
在原z2的信号中增加噪声信号n1,噪声强度为0.5倍的标准正态分布,即复合信号z3=z2+n1,如下图所示。
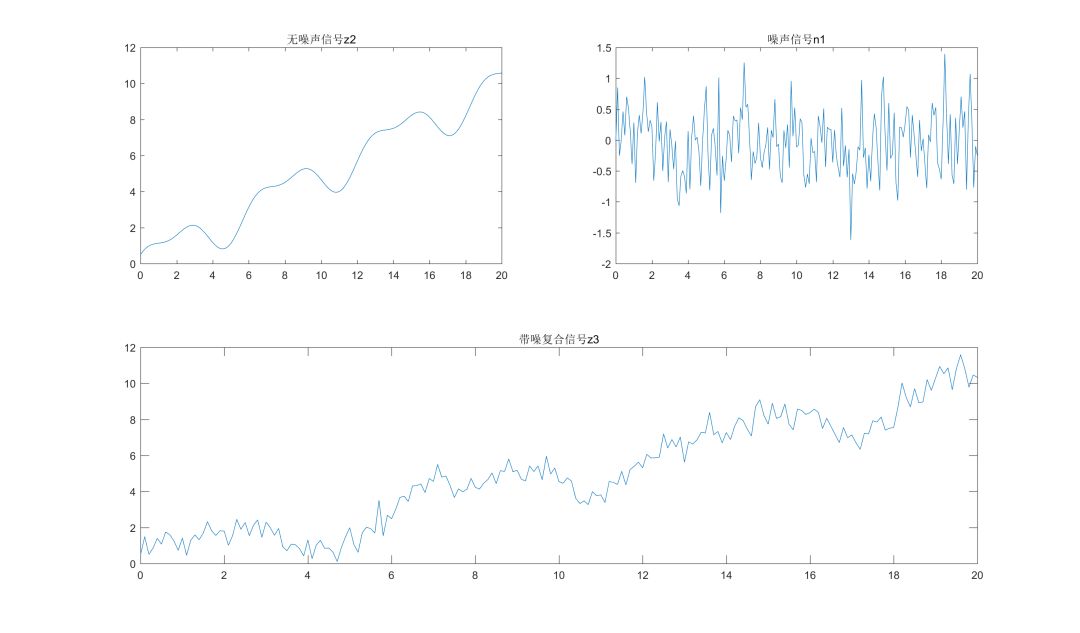
EMD算法的结果如下图:
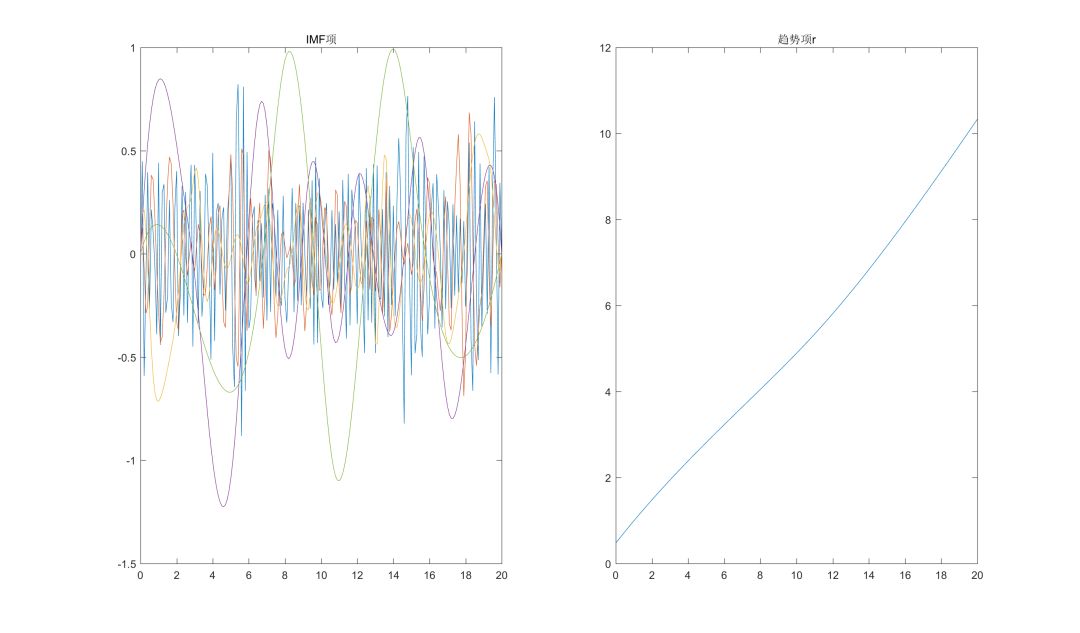
从结果上看,①趋势项依然较好地得到了分离。②尽管实际中只有两个周期信号,但算法却分解出了5个IMF,其中除了两个主要的IMF以外,其他的都近似于噪声水平。表明算法受噪声的影响还是比较大的。从算法上进行解释的话主要的原因在于算法终止条件要求最终的趋势项r是严格单调的,这一点在噪声较大时有时会显得过于苛刻。对此,在实际应用中笔者认为可以考虑两种处理方式:一是不要求r完全单调,而改为基本单调(通过设定阈值使得当大部分数值单调时就退出循环);二是直接限定IMF的最大阶数,例如研报中便直接将IMF的阶数设定为4。本文接下来的部分也采用这种方法进行。
另外,关于h的计算过程中,由于现实数据的离散性,有可能出现连续的零值,届时在IMF条件的判定中将陷入死循环,因此本文接下来的实证中也限定了h的最大迭代次数。(在研报中则直接忽略了IMF条件的判定,不过这点对结果的影响其实并不大。)
本部分主要代码
(本文代码太长,请点击阅读原文,查看全部)
1)EMD算法:
function [imfset,r]=emd(s)
% 输入:原始信号,输出:本征模态函数集、趋势项
% tic;
alpha=0.1;
imfset={};
k=1;
% while k<=4 % 设定IMF的最大阶数为4
while true % 不限定IMF的阶数
imf=getimf(s,alpha);
imfset{1,k}=imf; %#ok<AGROW>
r=s-imf;
flag=ismon(r); % 判断r是否单调
if flag==1
break;
end
k=k+1;
s=r;
end2)数值实验代码:
% emd算法的数值实验
clear;clc;
%% 单IMF信号
x=0:0.1:20;
y1=0.5*x; % 趋势项
y2=sin(x); % 周期项1
z1=y1+y2; % 实验函数1
figure;
subplot(2,2,1);plot(x,y1);title('趋势项y1');
subplot(2,2,2);plot(x,y2);title('周期项y2');
subplot(2,2,[3,4]);plot(x,z1);title('复合信号z1')
[imfset1,r1]=emd(z1');
n=size(imfset1,2);
figure;
subplot(1,2,1);
for i=1:n
plot(x,imfset1{i});
hold on;
end
二、EMDT及参数确定
2.1 EMDT策略
EMDT策略的基本思路:使用EMD算法对价格序列进行分解得到趋势项和波动项,通过比较两者相对能量的强弱判断当日行情的趋势是否明显,如趋势强烈则相应建仓直到当日临收盘时平仓。具体地说:
取开盘若干分钟(下文均取30分钟)的价格序列s通过EMD算法分解得到趋势项r,定义波动和趋势的能量比为:
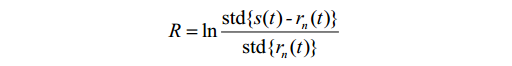
显然当趋势越强时R越小,那么基于开盘半小时数据计算得到的指标R能在多大程度上与一天的趋势强度相关联呢?若以一天K线中实体部分的占比来度量当天的趋势强度,即
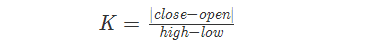
其中open,close,high和low分别代表一天的开盘价、收盘价、最高价和最低价。
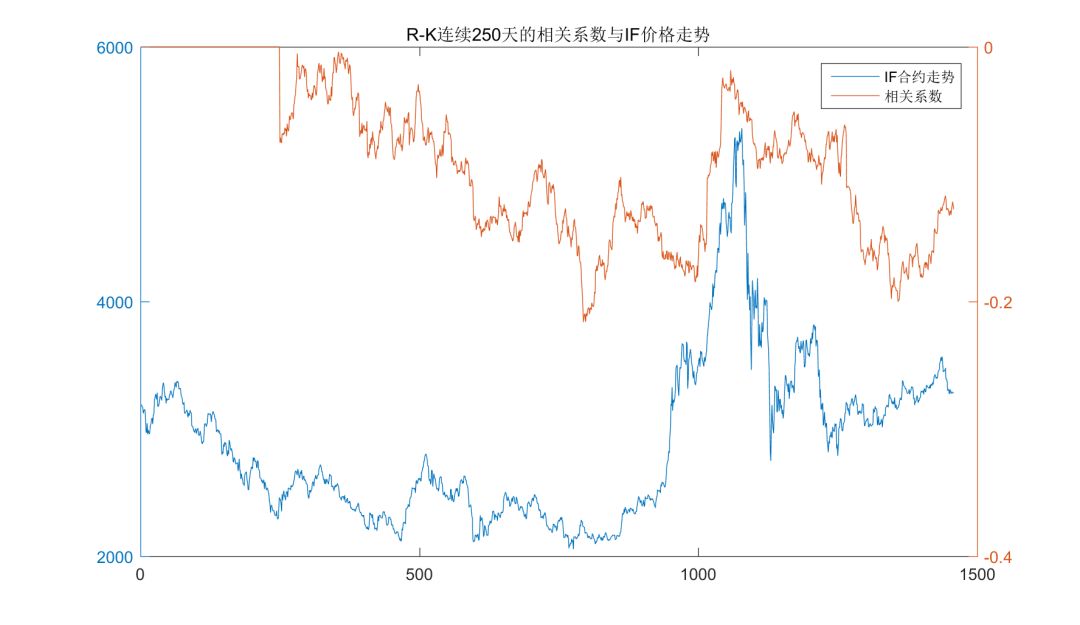
则基于沪深300股指期货主力合约(IF0000)20110101-20161231期间共计1458个交易日的数据计算得到的R和K的相关系数为-0.1055,可以说是相关性比较强的一个因子了。进一步地,我们考察该相关性的时间敏感性,下图给出了两者在连续的250个交易日里的相关系数,在我们的样本时间里,该相关系数始终小于0,最高时能超过0.2,尽管随时间波动较大,但对照同期IF合约的走势来看该相关关系的变化似乎与大行情的震荡或趋势并无明显关系。
2.2 策略参数确定
基于上述信息,我们可以选取某一阈值beta,当R小于beta时则根据涨跌情况建立多头或空头仓位,除非触发止损条件否则持有至临收盘时平仓。研报中对于该参数的选取采用的是过去k日的平均值,该方法简单易行却显得过于主观,本节则尝试着基于历史数据探讨beta的可能规律,然后尽量给出一种较为客观的参数选取规则。
1)参数的初步确定
基于IF0000合约20110101至20161231期间的历史数据,我们测试了beta自-1.5至1.5间隔的策略效果。如下图所示,左轴表示策略的累积收益(在不考虑止损和交易费用的情况下)、右轴表示策略的胜率。从测试的结果来看,随着beta的增大,收益明显增加,直到beta=0.3时达到最大值,随后递减。而胜率则随着beta的增加一路递减,并最终稳定在0.5左右。
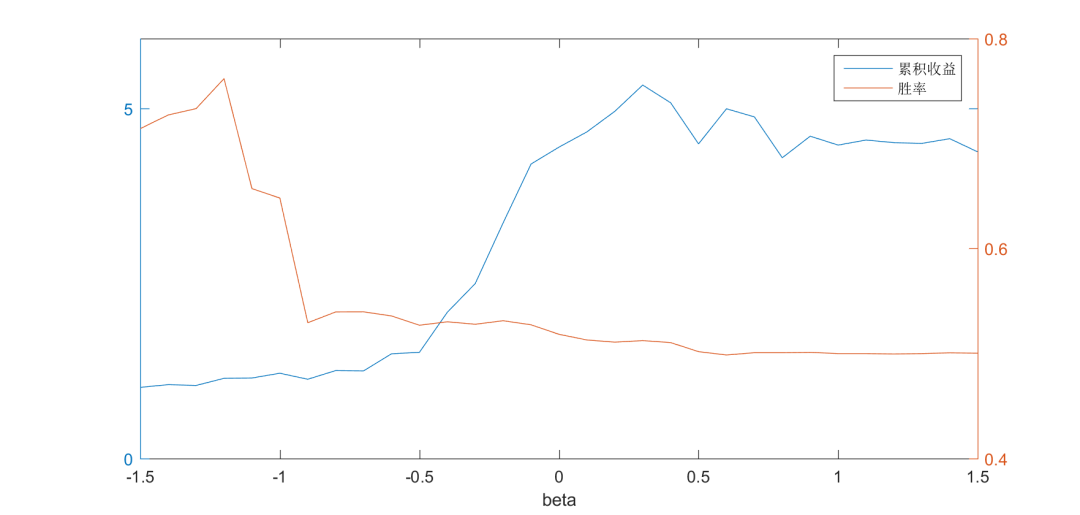
从上图中可以看出beta=0.3这点显示出了较好的极值特性,如果仅看这点似乎0.3是最佳参数,但需要注意的是过拟合问题,即过于迎合历史数据的拟合结果可能并不适应于未来的情况。但是另一方面,一个具有普适性的策略应该在过去也有较好的表现(虽然通常并不是最好的),因此大体上我们可以将参数范围限定在-0.1~0.9。接下来我们对该范围的参数进行时间敏感性测试。
2)参数的时间敏感性测试
下面两张图给出了beta取值从-0.1~0.7之间时,策略在连续250天和500天里的累积收益的变动情况。大体上可以看出几点:
1、当大行情处于震荡时,较小beta的业绩较好,尤其是在损失控制方面。
2、趋势行情是本策略的主要盈利点,在此行情中较大的beta业绩较好。
3、几乎在任何时刻beta>0.3的业绩都未能比beta=0.3更好,如果考虑交易成本,可以预见这点会更加明显。
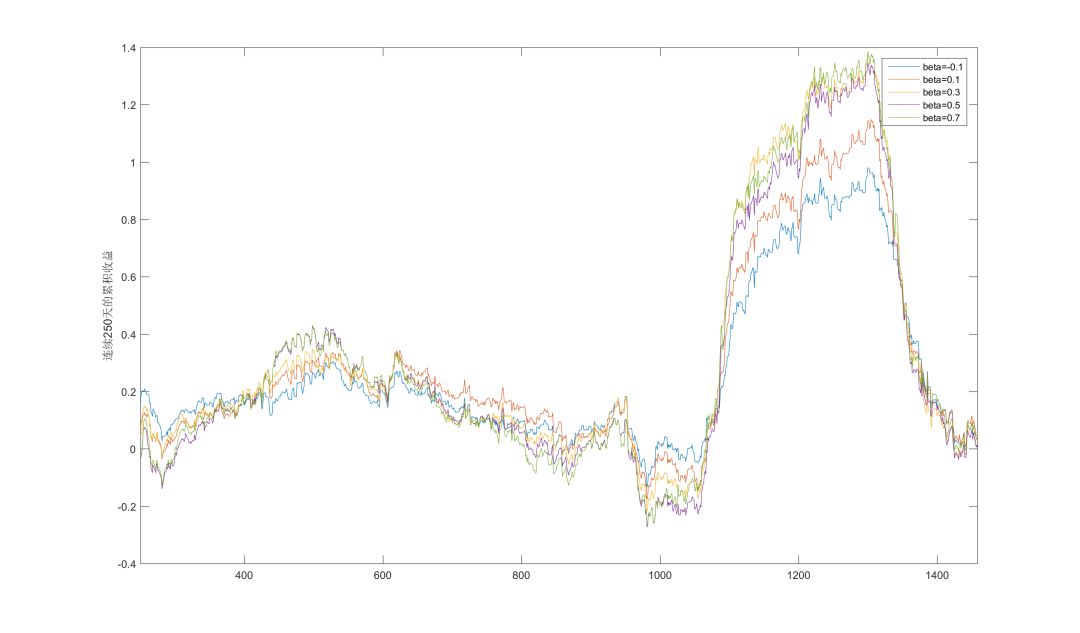
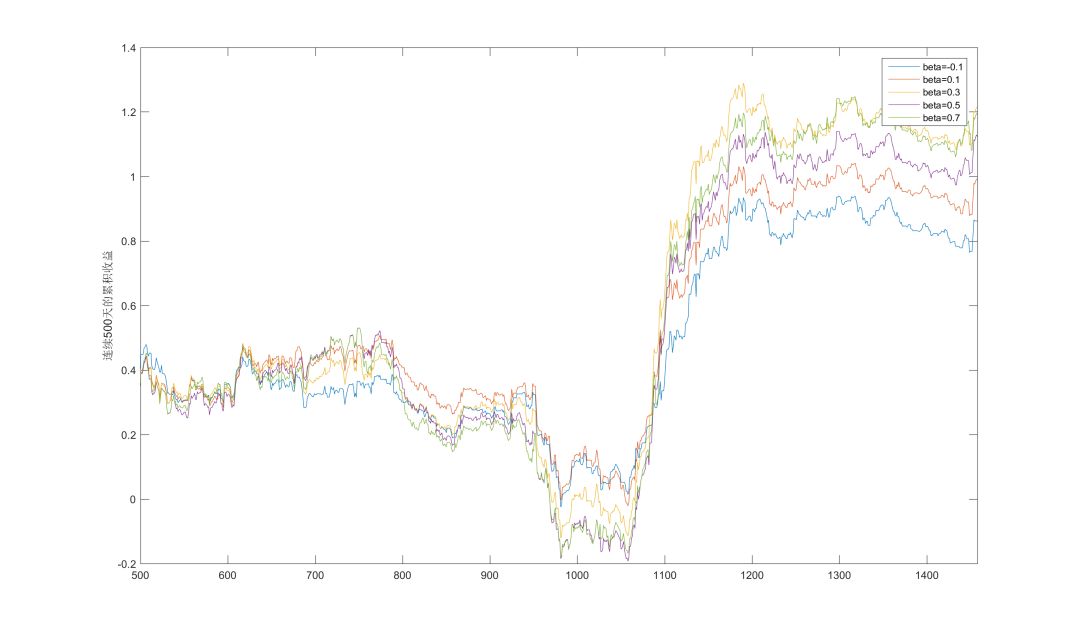
如果要进一步测试参数对样本的敏感性程度,还可以采用自助抽样法(Bootstrapping),通过产生随机样本进行多次模拟以确保参数的可靠性。本文暂时不就此展开。
三、策略回测及评价
如果仅从历史数据考虑,无疑beta=0.3是最佳选择,但假如该策略要在现在执行,考虑到当前及短时间的未来不太可能出现大行情,那么beta应取较小为宜。故本次回测中,beta取-0.1,同时止损点设为0.03,手续费率取万分之二,不使用杠杆的情况下样本内(2011-2016)和样本外(2017)的回测结果如下所示。
策略代码
具体策略代码请点击阅读原文

回测详情
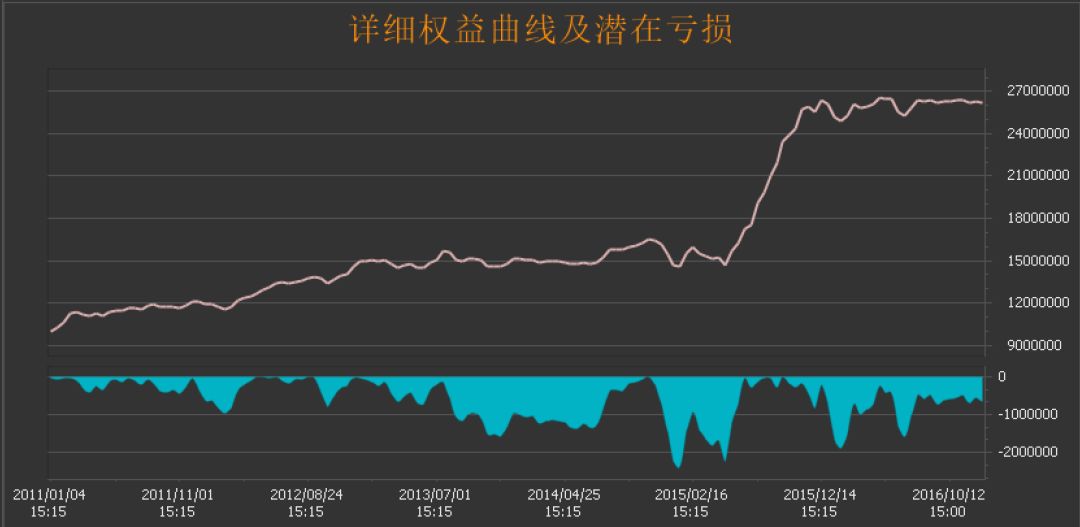
主要指标:
年化收益:18.03%
最大回撤:16.65%
夏普比率:1.15
Calmar比率:0.96
胜率:51.83%。
2017年的回测由于软件问题无法给出权益曲线,从指标上来看收益率2.21%,最大回撤4.76%,但胜率依然能有51.85%,总体上讲由于17年市场较为沉寂鲜有较大的行情,这对于主要靠趋势盈利的策略来说很难有所作为,因此业绩表现差强人意,该情形同样也出现在13年和16年。
策略评价
1、做为一种通过日内趋势获利的策略,其适用于趋势性较强的期货品种,尽管本文的研究基于股指期货而展开,但其并不一定是本策略最适宜的投资品种。
2、本策略接近52%的胜率在趋势型策略中算是比较高的,而且长期来看都比较稳定,因此即使行情不利,也很少出现特别大的亏损,表明算法还是具有一定的可靠性。
3、若要进一步改善策略笔者考虑可以从两个方面进行:
一是当判定行情趋势性不强时,在日内使用震荡型策略的操作方式做为补充。
二是同时在日频数据上使用EMD算法判定大行情的趋势性强弱,进而采取动态参数或动态选择交易对象等。


