DQN系列(3): 优先级经验回放(Prioritized Experience Replay)论文阅读、原理及实现
深度强化学习实验室报道
论文来源:arxiv.com
作者:DeepRL

还是往常的学习顺序,先摘要和结论本论文是由DeepMind操刀,Schaul主导完成的文章,发表于顶会ICLR2016上,主要解决经验回放中的”采样问题“(在DQN算法中使用了经典的”experience replay“,但存在一个问题是其采用均匀采样和批次更新,导致特别少但价值特别高的经验没有被高效的利用)。
 通常情况下,在使用“经验”回放的算法中,通常从缓冲池中采用“均匀采样(Uniformly sampling)”,虽然这种方法在
DQN算法
中取得了不错的效果并登顶Nature,但其缺点仍然值得探讨,本文提出了一种 “优先级经验回放(prioritized experience reolay)” 技术去解决采样问题,并将这种方法应用在DQN中实现了state-of-the-art的水平。
通常情况下,在使用“经验”回放的算法中,通常从缓冲池中采用“均匀采样(Uniformly sampling)”,虽然这种方法在
DQN算法
中取得了不错的效果并登顶Nature,但其缺点仍然值得探讨,本文提出了一种 “优先级经验回放(prioritized experience reolay)” 技术去解决采样问题,并将这种方法应用在DQN中实现了state-of-the-art的水平。

-
基于梯度的更新打破了数据之间的独立同分布(i.i.d.) 假设问题 -
快速忘记了一些罕见重要的、以后使用的经验数据
| transition |
|---|
| < , , , > |
| < , , , > |
| .... |
| < , , , > |
所以问题归结于"如何从上表中的experience中以mini-batch的方式选取数据学习呢?",即 如何采样(sampling)?
作者拿一个具体的例子来说明均匀采样有什么问题,假设有一个如下图所示的environment,它有 个状态,2个动作,初始状态为1,状态转移如箭头所示,当且仅当沿绿色箭头走的时候会有1的reward,其余情况的reward均为0。那么假如采用随机策略从初始状态开始走n步,我们能够获得有用的信息(reward非0)的可能性为 。也就是说,假如我们把各transition都存了起来,然后采用均匀采样来取transition,我们仅有 的概率取到有用的信息,这样的话学习效率就会很低。
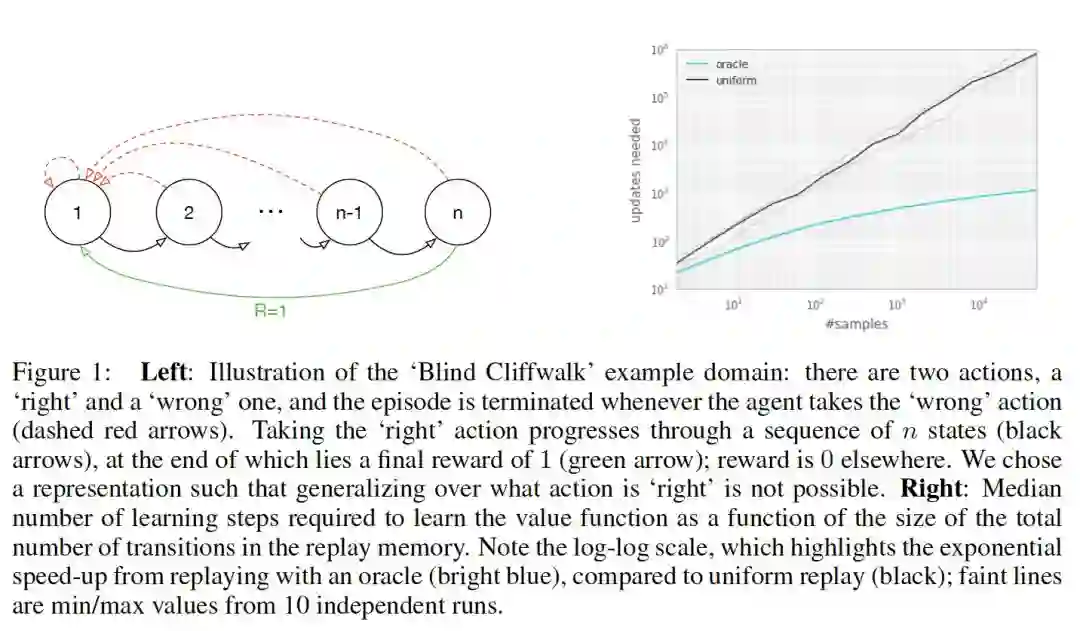
1.2 衡量指标 TD-error
作者首先给出了一个衡量指标:“TD-error”,随后贪心地选”信息量“最大的transition,然而这种方法存在以下缺陷:
-
由于考虑到算法效率,不会每次critic更新后都更新所有transition的TD-error,我们只会更新当次取到的transition的TD-error。 因此transition的TD-error对应的critic是以前的critic(更准确地说,是上次取到该transition时的critic)而不是当前的critic。 也就是说某一个transition的TD-error较低,只能够说明它对之前的critic“信息量”不大,而不能说明它对当前的critic“信息量”不大,因此根据TD-error进行贪心有可能会错过对当前critic“信息量”大的transition。 -
容易overfitting: 基于贪心的做法还容易“旱的旱死,涝的涝死”,因为从原理上来说,被选中的transition的TD-error在critic更新后会下降,然后排到后面去,下一次就不会选中这些transition),来来去去都是那几个transition,导致overfitting。
Prioritized DQN能够成功的主要原因有两个:
-
sum tree这种数据结构带来的采样的O(log n)的高效率 -
Weighted Importance sampling的正确估计

2.1 随机优先级采样方法
其中 为第 个transition的priority, 用于调节优先程度( 的时候退化为均匀采样),以下两种方案的区别在于对priority的定义不同。
2.1.1 第一种变体:proportional prioritization(比例优先级)
,其中 为TD-error, 用于防止概率为0,实现的时候采用sum tree的数据结构。
SumTree方法
1.为什么使用SumTree?假设有一个数据列表,并且需要从列表中随机抽取数据。您可以做的一件事是生成一个介于零和列表大小之间的随机整数,并从列表中检索数据
#!/usr/bin/python# -*- coding: utf-8 -*-data_list = np.array(np.random.rand(100))#数据生成index = np.random.randint(0,len(data_list))data = data_list [index]print(data)
使用这种方法,将能够以等价方式从列表中获取数据。如果需要从列表中获得更高优先级的数据,该怎么办? 有没有一种可以为某些高优先级数据提供较高的检索率方法呢?
《1》 方法1: 尝试按优先级从高到低的顺序对数据列表进行排序。然后从生成器中获取一个随机数,该生成器有很大的机会给出接近零的数字,而当该数字远离零时则具有较低的机会。均值等于零的高斯随机数生成器可能会起作用。您可以相应地调整sigma。
这里的主要问题是如何调整sigma以适合列表的大小。如果列表的大小增加了,那么您将需要再次调整sigma。另外,如果生成器提供的数字大于列表的大小,该怎么办?因此,该方法将不可行。
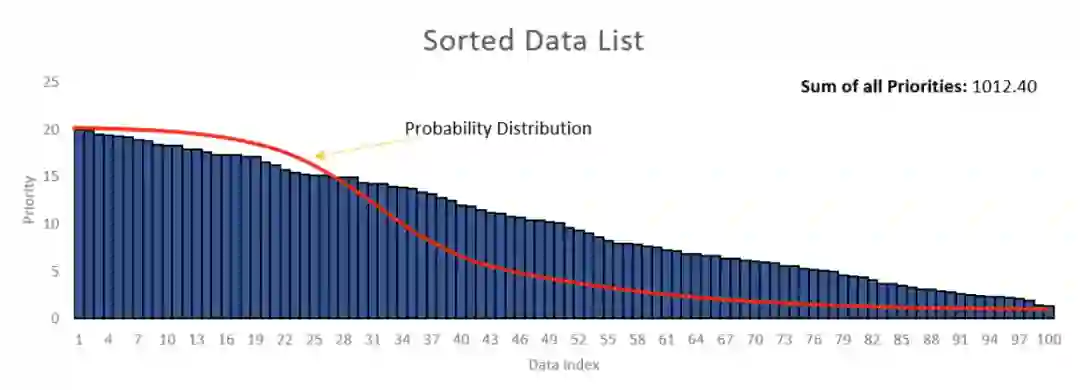
《2》 方法二:根据均匀分布在数据列表中的零和总优先级值之和之间生成一个随机数(在示例中为1012.4)。假设从随机数生成器获得了数字430.58。然后必须从左到右对列表的优先级值求和,直到总和超过430.58。
在下图这种情况下,总概率为68。根据均匀分布生成一个随机数。如果生成的数字介于之间0-17,则必须从列表中选择第一个元素。如果介于之间18-30,则必须选择第二个元素,依此类推,这样从数据列表中检索第一个元素的机会更高。其实考虑一下,如果遵循求和方法,则无需进行排序,则有较高的机会检索具有较高概率值的元素。如图右。
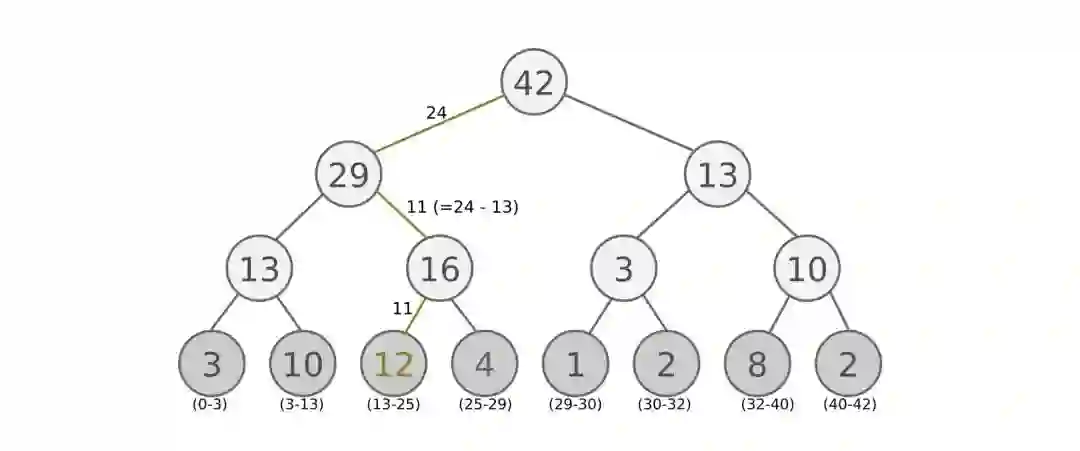
定义: SumTree(求和树)是一种特殊的二叉树,其中父节点的值等于其子节点的值之和,如下图所示,根节点的值是所有叶子的值的和:13 = 3+10,42 = 29+13,依此类推......
这里的Node的值,我们将其定义为每个经验样本一个优先度(priority)优先度定义为:
表示如果TD-error愈大,则代表这个样本预测精度还有很多上升空间,意味着更需要被学习,也就是优先度(priority)愈高,其中,leaf上的数值是priority,也就是最底下那一层就是叶子(leaf)
基本原理:在抽样时, 将root priority 除以batch_size, 分成batch_size个区间,
如果root node 的priority 是42的话, 如果抽6个样本, 这时的区间拥有的priority可能是这样.[0-7], [7-14], [14-21], [21-28], [28-35], [35-42]然后在每个区间随机选取一个数(value),比如在区间[21-28]选到了24,就按照这个24从最顶上的42开始向下搜索,首先看到最顶上的42下面有两个child nodes,拿着手中的24对比左边的child 29,如果左边的child比自己手中的值大,那就走左边这条路,接着再对比29下面左边那个点13这时手中的24比13大,那就走右边那条路,并且将手中的值根据13修改一下,变成24–13=11,接着拿着11和13左下角的12比,结果12比11大,那就选12当作这次选到的priority,并且也选择12对应的数据。 之后就在这几个区间内分别做均匀采样,最后取得6个transition。
下面进行SumTree的实现
import numpy as npclass Tree(object):write = 0def __init__(self, capacity):self.capacity = capacity # capacity是叶子节点个数,self.tree = np.zeros(2 * capacity) # 从1开始编号[1,capacity]self.data = np.zeros(capacity+1, dtype=object) # 存叶子节点对应的数据data[叶子节点编号id] = datadef add(self, p, data):idx = self.write + self.capacityself.data[self.write+1] = dataself._updatetree(idx, p)self.write += 1if self.write > self.capacity:self.write = 0def _updatetree(self, idx, p):change = p - self.tree[idx]self._propagate(idx, change)self.tree[idx] = pdef _propagate(self, idx, change):parent = idx // 2self.tree[parent] += change # 更新父节点的值,是向上传播的体现if parent != 1:self._propagate(parent, change)def _total(self):return self.tree[1]def get(self, s):idx = self._retrieve(1, s)index_data = idx - self.capacity + 1return (idx, self.tree[idx], self.data[index_data])def _retrieve(self, idx, s):left = 2 * idxright = left + 1if left >= (len(self.tree)-1):return idxif s <= self.tree[left]:return self._retrieve(left, s) # 往左孩子处查找else:return self._retrieve(right, s - self.tree[left]) # 往右孩子处查找tree = Tree(5)tree.add(1,3)tree.add(2,4)tree.add(3,5)tree.add(4,6)tree.add(6,11)print(tree.get(4)) # (8, 4.0, 6)
2.1.2 第二种变体:rank-based prioritization(基于排名的优先级)
2.1.2.1 基于优先级rank数学表示为:
这里定性地考虑priority,没有定量地考虑priority。实现类似分层抽样,事先将排名段分为几个等概率区间,再在各个等概率区间里面均匀采样,其中在采样的过程中采用了热偏置处理。
2.1.2.2 热偏置(Annealing The Bias)
Importance samplingn(重要性采样)重要性采样是统计学中估计某一分布性质时使用的一种方法。该方法从与原分布不同的另一个分布中采样,而对原先分布的性质进行估计,数学表示为:
利用随机更新得来的期望值往往依赖于这些更新,优先回放引入了误差,因为它以一种不受控的形式改变了分布,从而改变了预测会收敛到的solution(即使policy和状态分布都固定),通常可以用下面的重要性采样权重来修正该误差(见2.1.4伪代码):
采样过程的实现如下:
def sample(self, n):b_idx, b_memory, ISWeights = np.empty((n,), dtype=np.int32), np.empty((n, self.tree.data[0].size)), np.empty((n, 1))pri_seg = self.tree.total_p / n # priority segmentself.beta = np.min([1., self.beta + self.beta_increment_per_sampling]) # max = 1min_prob = np.min(self.tree.tree[-self.tree.capacity:]) / self.tree.total_p # for later calculate ISweightif min_prob == 0:min_prob = 0.00001for i in range(n):a, b = pri_seg * i, pri_seg * (i + 1)v = np.random.uniform(a, b)idx, p, data = self.tree.get_leaf(v)prob = p / self.tree.total_pISWeights[i, 0] = np.power(prob/min_prob, -self.beta)b_idx[i], b_memory[i, :] = idx, datareturn b_idx, b_memory, ISWeights
通过以上,已经将要采样的区间划分为n段切每段进行均匀采样,当我们拿到第i段的均匀采样值v以后,就可以去SumTree中找对应的叶子节点拿样本数据、样本叶子节点序号以及样本优先级。代码如下:
def get_leaf(self, v):"""Tree structure and array storage:Tree index:-> storing priority sum/ \2/ \ / \4 5 6 -> storing priority for transitionsArray type for storing:[0,1,2,3,4,5,6]"""parent_idx = 0while True: # the while loop is faster than the method in the reference codecl_idx = 2 * parent_idx + 1 # this leaf's left and right kidscr_idx = cl_idx + 1if cl_idx >= len(self.tree): # reach bottom, end searchleaf_idx = parent_idxbreakelse: # downward search, always search for a higher priority nodeif v <= self.tree[cl_idx]:parent_idx = cl_idxelse:v -= self.tree[cl_idx]parent_idx = cr_idxdata_idx = leaf_idx - self.capacity + 1return leaf_idx, self.tree[leaf_idx], self.data[data_idx]
总结:和DQN比,DDQN的TensorFlow网络结构流程中多了一个TD误差的计算节点,以及损失函数多了一个ISWeights系数。
2.1.4 算法伪代码如下:

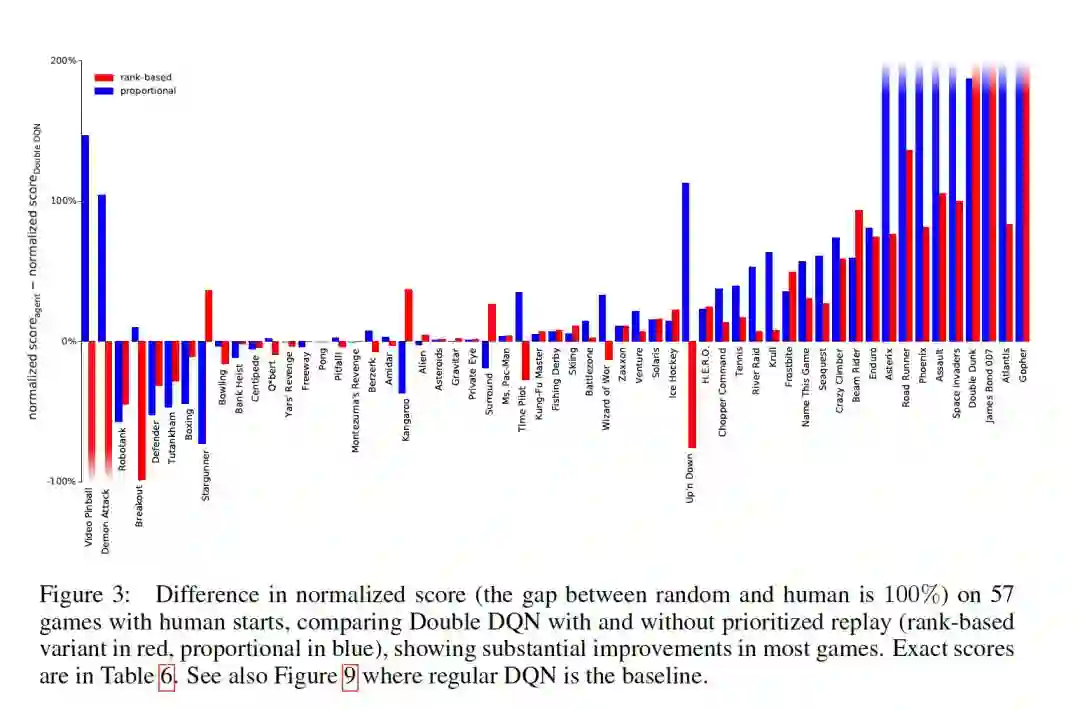
2.3 实验结果:
实验结果部分的谈论本文不作过多讨论,具体结果如下,感兴趣的请阅读原论文
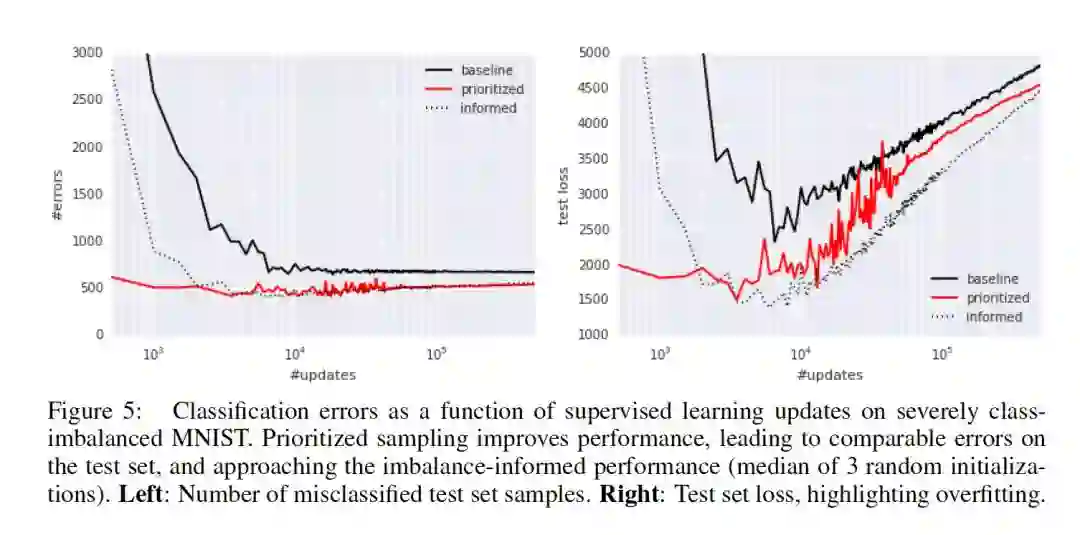
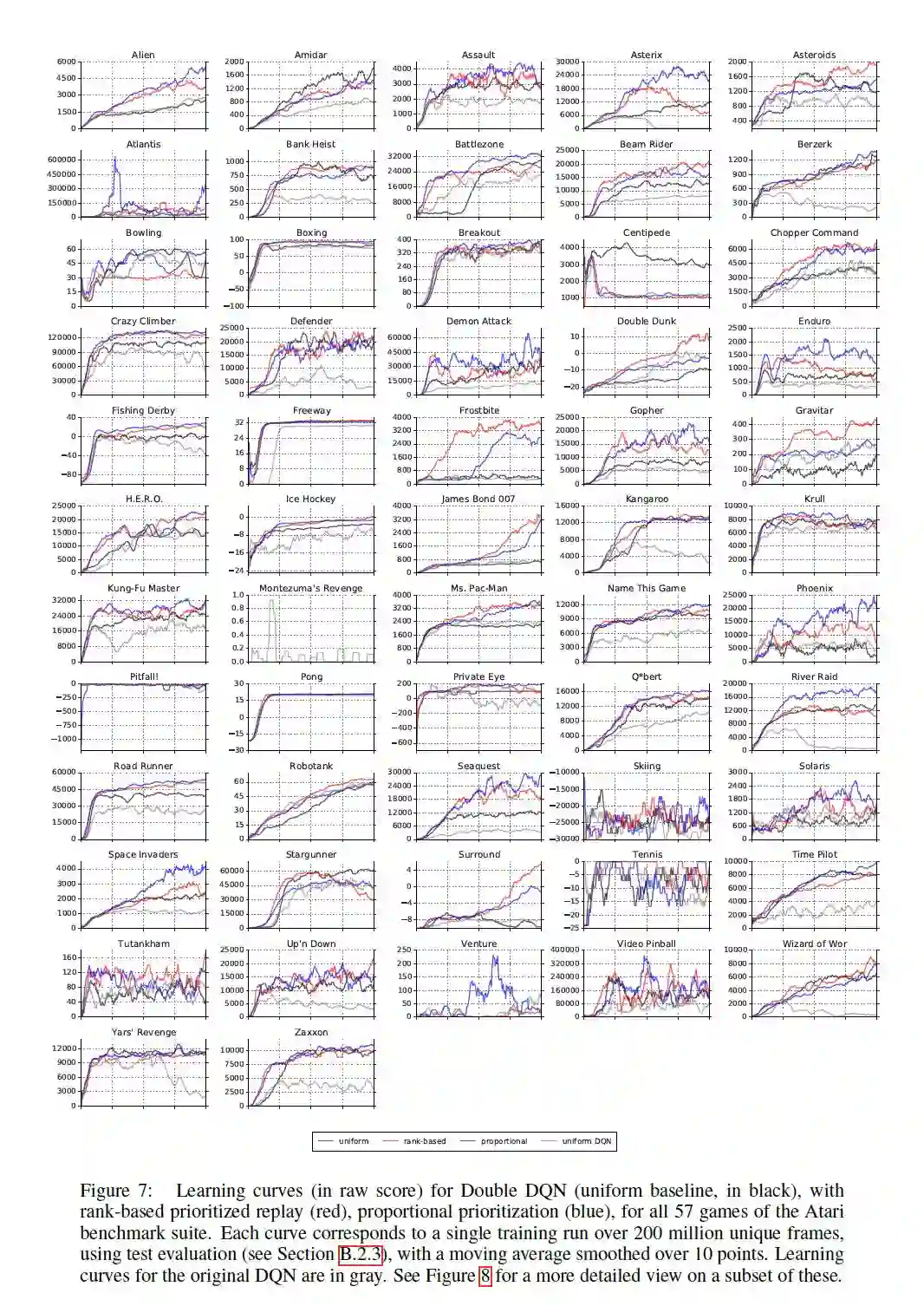
也可查看博客:
https://blog.csdn.net/gsww404/article/details/103673852
|| 3. 代码复现
本文参考了很多优秀伙伴的代码,以tensorflow为例如下:
import gymimport tensorflow as tfimport numpy as npimport randomfrom collections import deque# Hyper Parameters for DQNGAMMA = 0.9 # discount factor for target QINITIAL_EPSILON = 0.5 # starting value of epsilonFINAL_EPSILON = 0.01 # final value of epsilonREPLAY_SIZE = 10000 # experience replay buffer sizeBATCH_SIZE = 128 # size of minibatchREPLACE_TARGET_FREQ = 10 # frequency to update target Q networkclass SumTree(object):"""This SumTree code is a modified version and the original code is from:https://github.com/jaara/AI-blog/blob/master/SumTree.pyStory data with its priority in the tree."""data_pointer = 0def __init__(self, capacity):self.capacity = capacity # for all priority valuesself.tree = np.zeros(2 * capacity - 1)# [--------------Parent nodes-------------][-------leaves to recode priority-------]# size: capacity - 1 size: capacityself.data = np.zeros(capacity, dtype=object) # for all transitions# [--------------data frame-------------]# size: capacitydef add(self, p, data):tree_idx = self.data_pointer + self.capacity - 1self.data[self.data_pointer] = data # update data_frameself.update(tree_idx, p) # update tree_frameself.data_pointer += 1if self.data_pointer >= self.capacity: # replace when exceed the capacityself.data_pointer = 0def update(self, tree_idx, p):change = p - self.tree[tree_idx]self.tree[tree_idx] = p# then propagate the change through treewhile tree_idx != 0: # this method is faster than the recursive loop in the reference codetree_idx = (tree_idx - 1) // 2self.tree[tree_idx] += changedef get_leaf(self, v):"""Tree structure and array storage:Tree index:0 -> storing priority sum/ \1 2/ \ / \3 4 5 6 -> storing priority for transitionsArray type for storing:[0,1,2,3,4,5,6]"""parent_idx = 0while True: # the while loop is faster than the method in the reference codecl_idx = 2 * parent_idx + 1 # this leaf's left and right kidscr_idx = cl_idx + 1if cl_idx >= len(self.tree): # reach bottom, end searchleaf_idx = parent_idxbreakelse: # downward search, always search for a higher priority nodeif v <= self.tree[cl_idx]:parent_idx = cl_idxelse:v -= self.tree[cl_idx]parent_idx = cr_idxdata_idx = leaf_idx - self.capacity + 1return leaf_idx, self.tree[leaf_idx], self.data[data_idx]def total_p(self):return self.tree[0] # the rootclass Memory(object): # stored as ( s, a, r, s_ ) in SumTree"""This Memory class is modified based on the original code from:https://github.com/jaara/AI-blog/blob/master/Seaquest-DDQN-PER.py"""epsilon = 0.01 # small amount to avoid zero priorityalpha = 0.6 # [0~1] convert the importance of TD error to prioritybeta = 0.4 # importance-sampling, from initial value increasing to 1beta_increment_per_sampling = 0.001abs_err_upper = 1. # clipped abs errordef __init__(self, capacity):self.tree = SumTree(capacity)def store(self, transition):max_p = np.max(self.tree.tree[-self.tree.capacity:])if max_p == 0:max_p = self.abs_err_upperself.tree.add(max_p, transition) # set the max p for new pdef sample(self, n):b_idx, b_memory, ISWeights = np.empty((n,), dtype=np.int32), np.empty((n, self.tree.data[0].size)), np.empty((n, 1))pri_seg = self.tree.total_p / n # priority segmentself.beta = np.min([1., self.beta + self.beta_increment_per_sampling]) # max = 1min_prob = np.min(self.tree.tree[-self.tree.capacity:]) / self.tree.total_p # for later calculate ISweightif min_prob == 0:min_prob = 0.00001for i in range(n):a, b = pri_seg * i, pri_seg * (i + 1)v = np.random.uniform(a, b)idx, p, data = self.tree.get_leaf(v)prob = p / self.tree.total_pISWeights[i, 0] = np.power(prob/min_prob, -self.beta)b_idx[i], b_memory[i, :] = idx, datareturn b_idx, b_memory, ISWeightsdef batch_update(self, tree_idx, abs_errors):abs_errors += self.epsilon # convert to abs and avoid 0clipped_errors = np.minimum(abs_errors, self.abs_err_upper)ps = np.power(clipped_errors, self.alpha)for ti, p in zip(tree_idx, ps):self.tree.update(ti, p)class DQN():# DQN Agentdef __init__(self, env):# init experience replayself.replay_total = 0# init some parametersself.time_step = 0self.epsilon = INITIAL_EPSILONself.state_dim = env.observation_space.shape[0]self.action_dim = env.action_space.nself.memory = Memory(capacity=REPLAY_SIZE)self.create_Q_network()self.create_training_method()# Init sessionself.session = tf.InteractiveSession()self.session.run(tf.global_variables_initializer())def create_Q_network(self):# input layerself.state_input = tf.placeholder("float", [None, self.state_dim])self.ISWeights = tf.placeholder(tf.float32, [None, 1])# network weightswith tf.variable_scope('current_net'):W1 = self.weight_variable([self.state_dim,20])b1 = self.bias_variable([20])W2 = self.weight_variable([20,self.action_dim])b2 = self.bias_variable([self.action_dim])# hidden layersh_layer = tf.nn.relu(tf.matmul(self.state_input,W1) + b1)# Q Value layerself.Q_value = tf.matmul(h_layer,W2) + b2with tf.variable_scope('target_net'):W1t = self.weight_variable([self.state_dim,20])b1t = self.bias_variable([20])W2t = self.weight_variable([20,self.action_dim])b2t = self.bias_variable([self.action_dim])# hidden layersh_layer_t = tf.nn.relu(tf.matmul(self.state_input,W1t) + b1t)# Q Value layerself.target_Q_value = tf.matmul(h_layer_t,W2t) + b2tt_params = tf.get_collection(tf.GraphKeys.GLOBAL_VARIABLES, scope='target_net')e_params = tf.get_collection(tf.GraphKeys.GLOBAL_VARIABLES, scope='current_net')with tf.variable_scope('soft_replacement'):self.target_replace_op = [tf.assign(t, e) for t, e in zip(t_params, e_params)]def create_training_method(self):self.action_input = tf.placeholder("float",[None,self.action_dim]) # one hot presentationself.y_input = tf.placeholder("float",[None])Q_action = tf.reduce_sum(tf.multiply(self.Q_value,self.action_input),reduction_indices = 1)self.cost = tf.reduce_mean(self.ISWeights *(tf.square(self.y_input - Q_action)))self.abs_errors =tf.abs(self.y_input - Q_action)self.optimizer = tf.train.AdamOptimizer(0.0001).minimize(self.cost)def store_transition(self, s, a, r, s_, done):transition = np.hstack((s, a, r, s_, done))self.memory.store(transition) # have high priority for newly arrived transitiondef perceive(self,state,action,reward,next_state,done):one_hot_action = np.zeros(self.action_dim)one_hot_action[action] = 1#print(state,one_hot_action,reward,next_state,done)self.store_transition(state,one_hot_action,reward,next_state,done)self.replay_total += 1if self.replay_total > BATCH_SIZE:self.train_Q_network()def train_Q_network(self):self.time_step += 1# Step 1: obtain random minibatch from replay memorytree_idx, minibatch, ISWeights = self.memory.sample(BATCH_SIZE)state_batch = minibatch[:,0:4]action_batch = minibatch[:,4:6]reward_batch = [data[6] for data in minibatch]next_state_batch = minibatch[:,7:11]# Step 2: calculate yy_batch = []current_Q_batch = self.Q_value.eval(feed_dict={self.state_input: next_state_batch})max_action_next = np.argmax(current_Q_batch, axis=1)target_Q_batch = self.target_Q_value.eval(feed_dict={self.state_input: next_state_batch})for i in range(0,BATCH_SIZE):done = minibatch[i][11]if done:y_batch.append(reward_batch[i])else :target_Q_value = target_Q_batch[i, max_action_next[i]]y_batch.append(reward_batch[i] + GAMMA * target_Q_value)self.optimizer.run(feed_dict={self.y_input:y_batch,self.action_input:action_batch,self.state_input:state_batch,self.ISWeights: ISWeights})_, abs_errors, _ = self.session.run([self.optimizer, self.abs_errors, self.cost], feed_dict={self.y_input: y_batch,self.action_input: action_batch,self.state_input: state_batch,self.ISWeights: ISWeights})self.memory.batch_update(tree_idx, abs_errors) # update prioritydef egreedy_action(self,state):Q_value = self.Q_value.eval(feed_dict = {self.state_input:[state]})[0]if random.random() <= self.epsilon:self.epsilon -= (INITIAL_EPSILON - FINAL_EPSILON) / 10000return random.randint(0,self.action_dim - 1)else:self.epsilon -= (INITIAL_EPSILON - FINAL_EPSILON) / 10000return np.argmax(Q_value)def action(self,state):return np.argmax(self.Q_value.eval(feed_dict = {self.state_input:[state]})[0])def update_target_q_network(self, episode):# update target Q netowrkif episode % REPLACE_TARGET_FREQ == 0:self.session.run(self.target_replace_op)#print('episode '+str(episode) +', target Q network params replaced!')def weight_variable(self,shape):initial = tf.truncated_normal(shape)return tf.Variable(initial)def bias_variable(self,shape):initial = tf.constant(0.01, shape = shape)return tf.Variable(initial)# ---------------------------------------------------------# Hyper ParametersENV_NAME = 'CartPole-v0'EPISODE = 3000 # Episode limitationSTEP = 300 # Step limitation in an episodeTEST = 5 # The number of experiment test every 100 episodedef main():# initialize OpenAI Gym env and dqn agentenv = gym.make(ENV_NAME)agent = DQN(env)for episode in range(EPISODE):# initialize taskstate = env.reset()# Trainfor step in range(STEP):action = agent.egreedy_action(state) # e-greedy action for trainnext_state,reward,done,_ = env.step(action)# Define reward for agentreward = -1 if done else 0.1agent.perceive(state,action,reward,next_state,done)state = next_stateif done:break# Test every 100 episodesif episode % 100 == 0:total_reward = 0for i in range(TEST):state = env.reset()for j in range(STEP):env.render()action = agent.action(state) # direct action for teststate,reward,done,_ = env.step(action)total_reward += rewardif done:breakave_reward = total_reward/TESTprint ('episode: ',episode,'Evaluation Average Reward:',ave_reward)agent.update_target_q_network(episode)if __name__ == '__main__':main()
致谢:代码部分参考了liujianping,特别感谢,其他见参考文献。

总结3: 《强化学习导论》代码/习题答案大全
总结6: 万字总结 || 强化学习之路
完
第64篇:UC Berkeley开源RAD来改进强化学习算法
第61篇:David Sliver 亲自讲解AlphaGo、Zero
第59篇:Agent57在所有经典Atari 游戏中吊打人类
第58篇:清华开源「天授」强化学习平台
第57篇:Google发布"强化学习"框架"SEED RL"
第53篇:TRPO/PPO提出者John Schulman谈科研
第52篇:《强化学习》可复现性和稳健性,如何解决?
第51篇:强化学习和最优控制的《十个关键点》
第50篇:微软全球深度强化学习开源项目开放申请
第49篇:DeepMind发布强化学习库 RLax
第48篇:AlphaStar过程详解笔记
第47篇:Exploration-Exploitation难题解决方法
第45篇:DQN系列(1): Double Q-learning
第44篇:科研界最全工具汇总
第42篇:深度强化学习入门到精通资料综述
第41篇:顶会征稿 || ICAPS2020: DeepRL
第40篇:实习生招聘 || 华为诺亚方舟实验室
第39篇:滴滴实习生|| 深度强化学习方向
第37篇:Call For Papers# IJCNN2020-DeepRL
第36篇:复现"深度强化学习"论文的经验之谈
第35篇:α-Rank算法之DeepMind及Huawei改进
第34篇:从Paper到Coding, DRL挑战34类游戏
第31篇:强化学习,路在何方?
第30篇:强化学习的三种范例
第29篇:框架ES-MAML:进化策略的元学习方法
第28篇:138页“策略优化”PPT--Pieter Abbeel
第27篇:迁移学习在强化学习中的应用及最新进展
第26篇:深入理解Hindsight Experience Replay
第25篇:10项【深度强化学习】赛事汇总
第24篇:DRL实验中到底需要多少个随机种子?
第23篇:142页"ICML会议"强化学习笔记
第22篇:通过深度强化学习实现通用量子控制
第21篇:《深度强化学习》面试题汇总
第20篇:《深度强化学习》招聘汇总(13家企业)
第19篇:解决反馈稀疏问题之HER原理与代码实现
第17篇:AI Paper | 几个实用工具推荐
第16篇:AI领域:如何做优秀研究并写高水平论文?
第14期论文: 2020-02-10(8篇)
第13期论文:2020-1-21(共7篇)
第12期论文:2020-1-10(Pieter Abbeel一篇,共6篇)
第11期论文:2019-12-19(3篇,一篇OpennAI)
第10期论文:2019-12-13(8篇)
第9期论文:2019-12-3(3篇)
第8期论文:2019-11-18(5篇)
第7期论文:2019-11-15(6篇)
第6期论文:2019-11-08(2篇)
第5期论文:2019-11-07(5篇,一篇DeepMind发表)
第4期论文:2019-11-05(4篇)
第3期论文:2019-11-04(6篇)
第2期论文:2019-11-03(3篇)
第1期论文:2019-11-02(5篇)


