Meta最新图像生成工具火了,竟能把梦境画成现实!
![]()
新智元报道

新智元报道
【新智元导读】在AI画画上,国外大厂已经卷上了新高度。这不,Meta也整了一个AI「画家」——Make-A-Scene。|还在纠结会不会错过元宇宙和web3浪潮?清华大学科学史系副教授胡翌霖,这次给你讲个透!
近日,Meta也整了一个AI「画家」——Make-A-Scene。

还以为只是用文字生成画作就这么简单吗?
要知道,仅是靠文字描述还有时候会「翻车」,就比如谷歌前段时间推出的「艺术家」Parti。
「一个没有香蕉的盘子,旁边有一个没有橙汁的玻璃杯。」

这次,Make-A-Scene可以通过文本描述,再加上一张草图,就能生成你想要的样子。
构图上下、左右、大小、形状等各种元素都由你说了算。

就连LeCun也出来力推自家的产品了,创意就不用说了,关键还「可控」!

Make-A-Scene有多厉害,不如一起来看看。
Meta的神笔马良
光说不练,假把式!
我们这就看看,人们究竟会怎么用Make-A-Scene,来实现他们的想象力。
研究团队将和知名的人工智能艺术家一起来进行Make-A-Scene的演示环节。

艺术家团队可谓阵容强大,包括Sofia Crespo、Scott Eaton、Alexander Reben和Refik Anadol等等,这些大师都有第一手的应用生成性人工智能的使用经验。
研发团队让这些艺术家们用Make-A-Scene作为创作过程的一部分,边使用边反馈。
接下来,我们就来欣赏一下大师们用Make-A-Scene创作出的作品吧。
例如,Sofia Crespo是一位专注于自然和技术交融的艺术家。她很爱想象从来没存在过的人造生命形式感,所以她使用Make-A-Scene的素描和文本提示功能,创造了全新的「混合生物」。

比如,花形的水母。
Crespo利用它的自由绘画功能,可以快速迭代新的想法。她表示,Make-A-Scene将有助于艺术家更好地发挥创造力,能让艺术家使用更直观的界面作画。
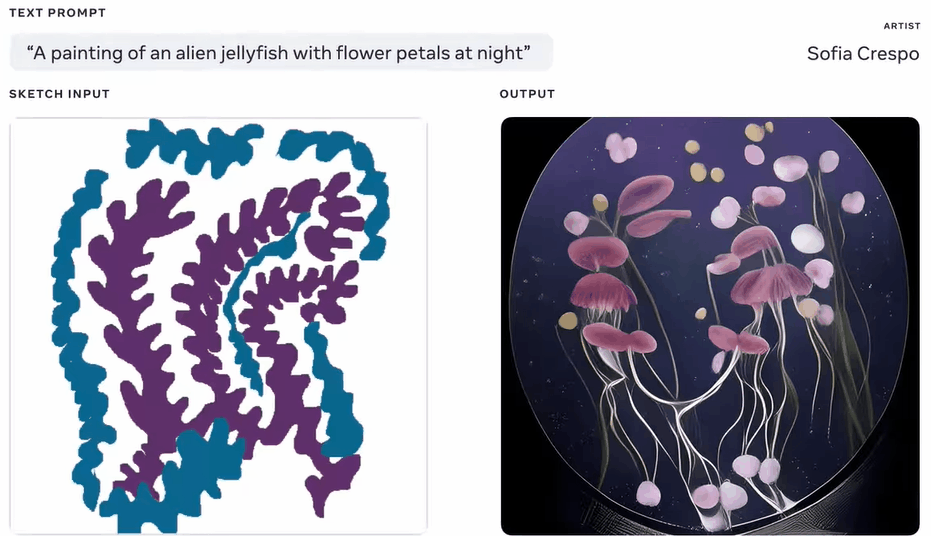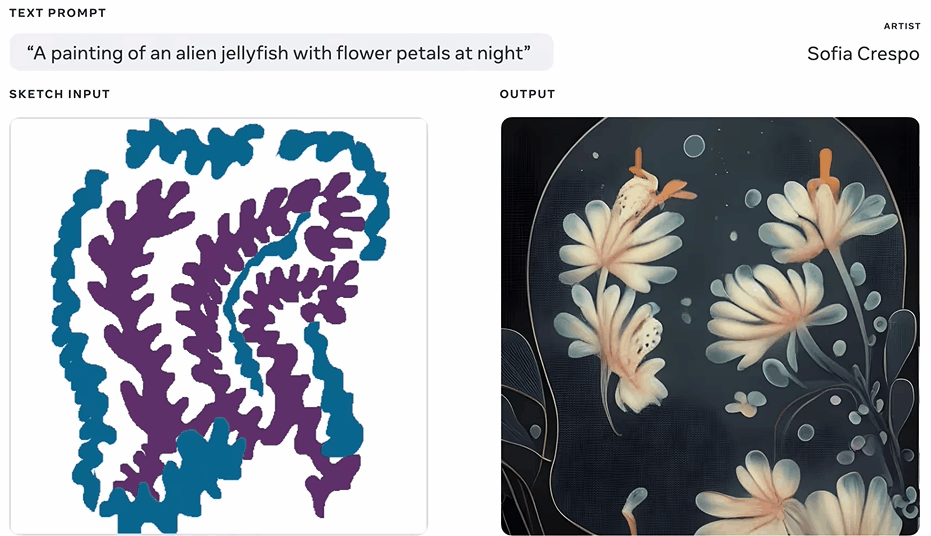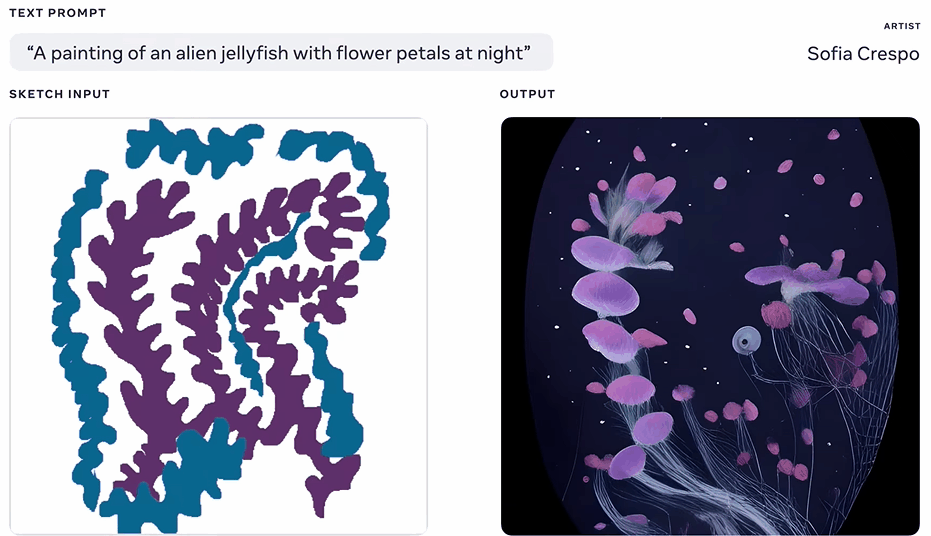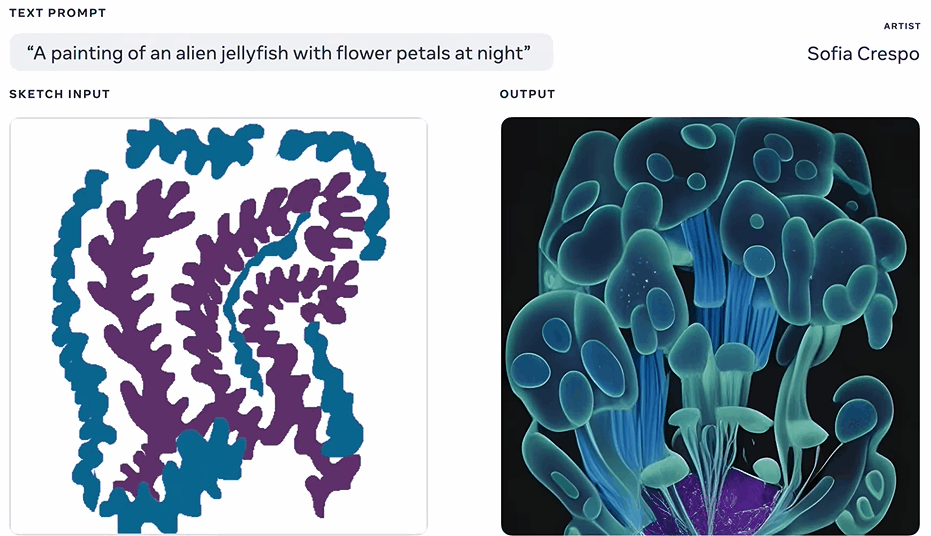
(花型的水母)
Scott Eaton是一位艺术家、教育家和创意技术专家,他的工作是调研究当代现状和技术之间的关系。
他用Make-A-Scene作为一种构成场景的方式,通过不同的提示来探索场景的变化,比如用类似「沙漠中沉没和腐烂的摩天大楼」这种主题来强调气候危机。

(沙漠中的摩天大楼)
Alexander Reben是一位艺术家、研究人员和机器人专家。
他认为,如果能对输出有更多的掌控,确实有助于表达自己的艺术意图。他将这些工具融入了他正在进行的系列作品之中。

而对于媒体艺术家和导演Refik Anadol来说,这个工具是一种促进想象力发展、更好地探索未知领域的方式。
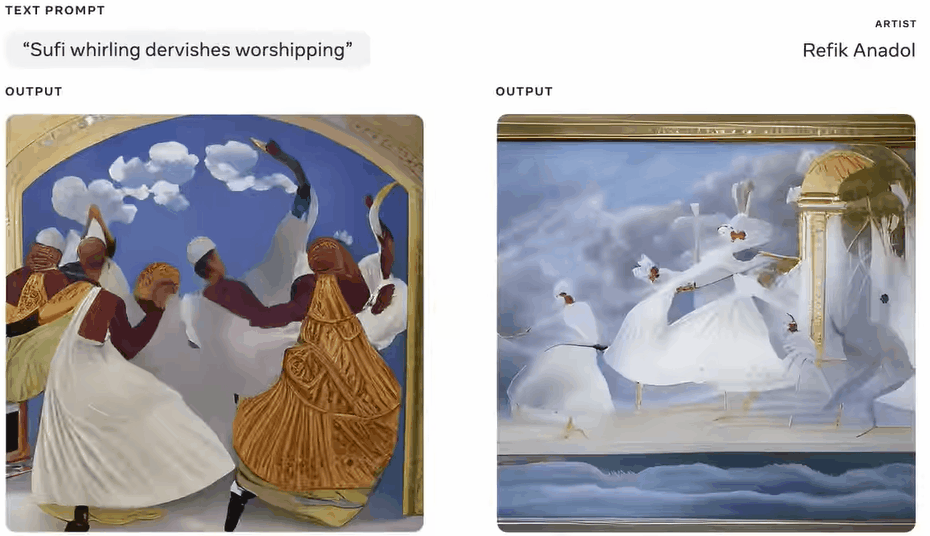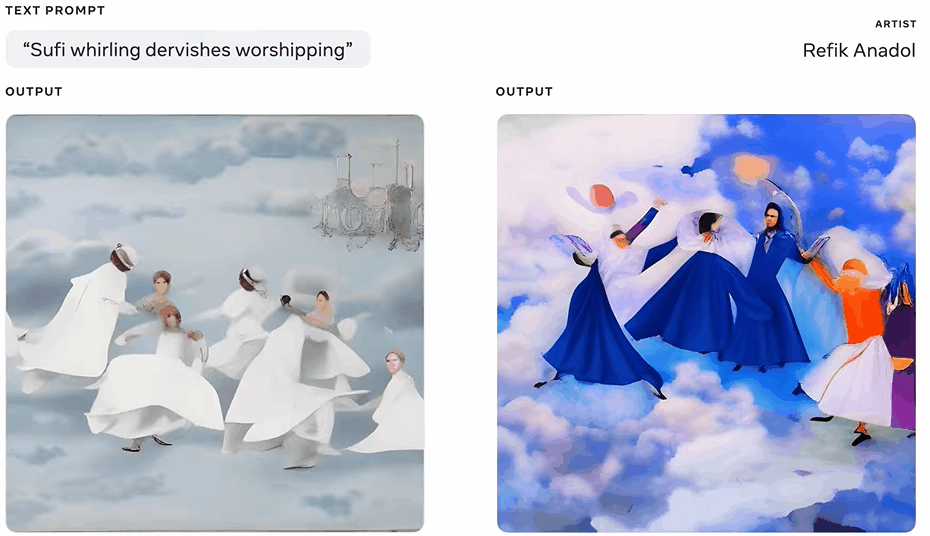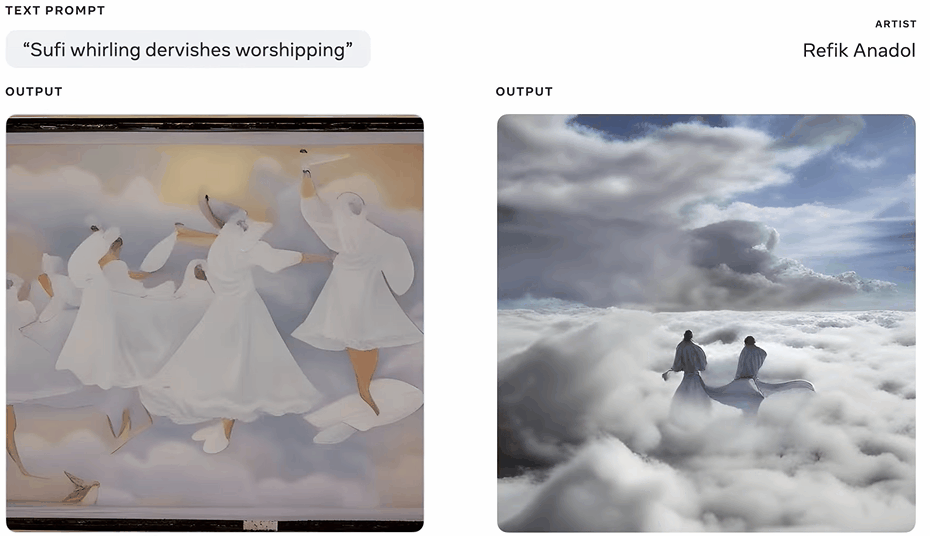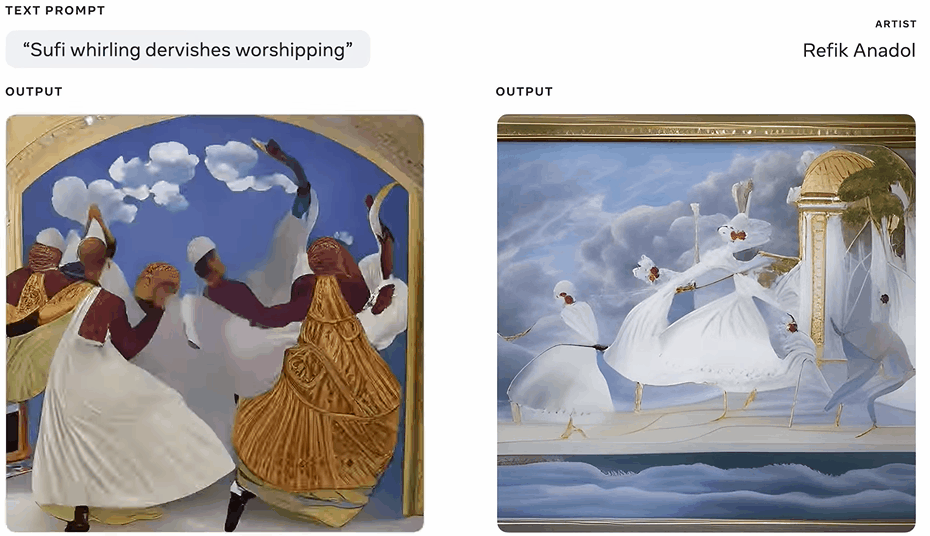
其实,这个原型工具不仅仅是为对艺术有兴趣的人准备的。
研究团队相信,Make-A-Scene可以帮助任何人更好地表达自己,包括那些没什么艺术细胞的人。
作为开始,研究团队向美达公司的员工提供了一部分使用权。他们正在测试并提供关于他们使用Make-A-Scene经验的反馈。
美达公司的项目经理Andy Boyatzis使用Make-A-Scene与他两岁和四岁的孩子一起创造艺术。他们用俏皮的图画把他们的想法和想象力变成了现实。
以下就是他们的作品~

一只五彩斑斓的雕塑猫~是不是很可爱。但是这个色调其实有点不忍直视,像小孩把一大坨橡皮泥瞎揉到一起。
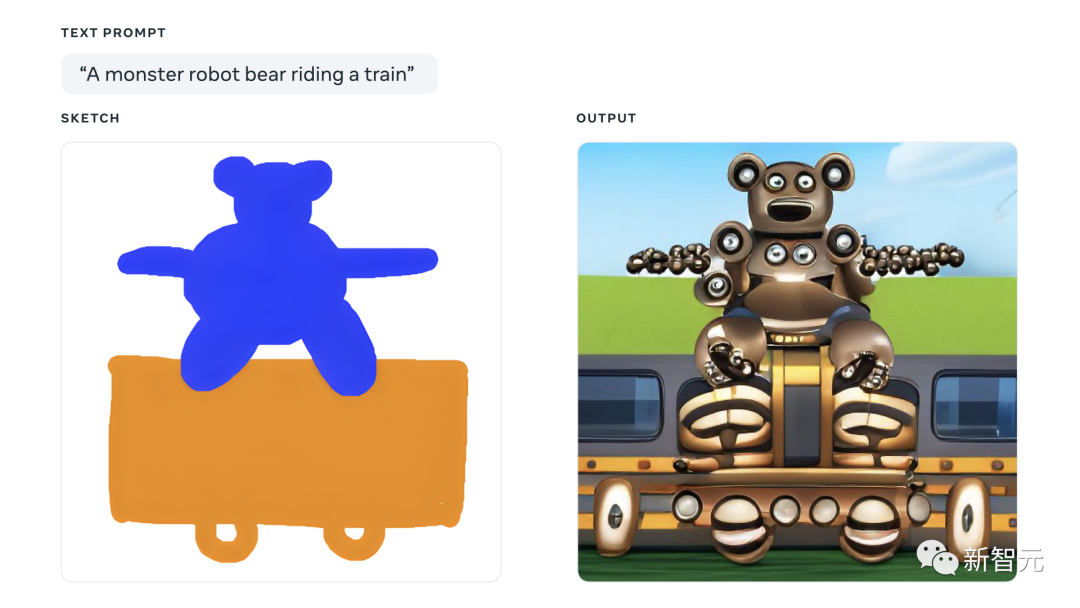
一只乘坐火车的怪兽熊。说真的,密恐患者抓紧绕行。小编看完这张图密恐直接窜到顶了。看看这诡异的胳膊,像脸一样的身子,像眼珠子一样的轮子...

一座山峰。讲道理,这张图蛮有意境的。但有没有感觉,远处的山和近处的小火车压根不是一个画风?

背后技术
虽然目前的方法提供了文本和图像域之间还算不错的转换,但它们仍然有几个关键问题没有很好地解决:可控性、人类感知、图像质量。
该模型的方法一定程度提高了结构一致性和图像质量。
整个场景由三个互补的语义分割组(全景、人类和人脸)组成。
通过组合三个提取的语义分割组,网络学习生成语义的布局和条件,生成最终图像。
为了创建场景的token空间,作者们采用了「VQ-SEG」,这是一项对「VQ-VAE」的改进。
在该实现中,「VQ-SEG」的输入和输出都是m个通道。附加通道是分隔不同类和实例的边的映射。边缘通道为同一类的相邻实例提供分离,并强调具有高度重要性的稀缺类。
在训练「VQ-SEG」网络时,由于每个人脸部分在场景空间中所占的像素数量相对较少,因此导致了重建场景中代表人脸部分(如眼睛、鼻子、嘴唇、眉毛)的语义分割频繁减少。
对此,作者们尝试在分割人脸部分类的基础上采用加权二元交叉熵人脸损失,更加突出人脸部分的重要性。此外,还将人脸部分的边缘作为上述语义分割边缘图的一部分。
作者们采用了在ImageNet数据集上训练的预训练VGG网络,而不是专门的人脸嵌入网络,并引入了表示重建图像和真实图像之间感知差异的特征匹配损失。
通过使用特征匹配,给VQ-IMG中的encoder和decoder分别添加额外的上采样层和下采样层,便可以将输出图像的分辨率从256×256进行提高。
想必大家对Transformer并不陌生,那么基于场景的Transformer又是什么呢?
它依赖于一个具有三个独立连续的token空间的自回归Transformer,即文本、场景和图像。
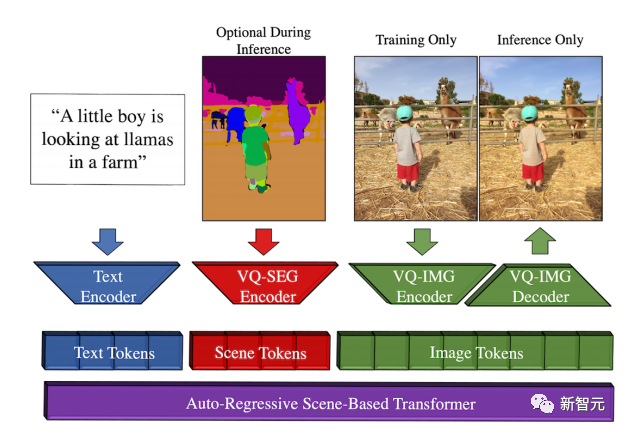
token序列由BPE编码器编码的文本token、VQ-SEG编码的场景token以及VQ-IMG编码或者解码的图像token组成。
在训练基于场景的Transformer之前,每个编码好的token序列都对应一个[文本,场景,图像]元组,使用相应的encoder提取。
此外,作者们还采用了无分类器引导,即将无条件样本引导到条件样本的过程。
该模型实现了SOTA结果。具体看一下和之前方法的效果对比


现在,研究人员还将Make-A-Scene整合了一个超分辨率网络,就可以生成2048x2048、4倍分辨率的图像。
如下:

其实,与其他生成AI模型一样,Make-A-Scene通过对数百万个示例图像进行训练来学习视觉和文本之间的关系。
不可否认的是,训练数据中反映的偏差会影响这些模型的输出。
正如研究者所指出的那样,Make-A-Scene还有很多地方有待提高。


