【斯坦福大学AI】BERT, ELMo, & GPT-2:上下文化的单词表示是怎样的?

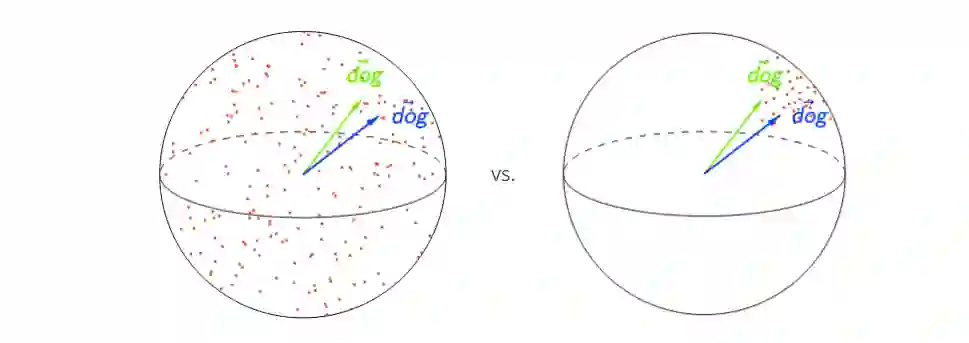
在ELMo、BERT和GPT-2中,上层比下层产生更多特定于上下文的表示。但是,这些模型对单词的上下文环境非常不同:在调整了各向异性之后,ELMo中相同句子中的单词之间的相似性最高,而GPT-2中几乎不存在。
平均而言,在一个词的上下文化表示中,只有不到5%的差异可以用静态嵌入来解释。因此,即使在最佳情况下,静态词嵌入也不能很好地替代上下文词。不过,上下文表示可以用来创建一种更强大的静态嵌入类型:BERT的低层上下文表示的主要组件比GloVe和FastText要好得多!如果你有兴趣沿着这些线阅读更多,看看:
The Dark Secrets of BERT (Rogers et al., 2019)
Evolution of Representations in the Transformer (Voita et al., 2019)
Cross-Lingual Alignment of Contextual Word Embeddings (Schuster et al., 2019)
The Illustrated BERT, ELMo, and co. (Alammar, 2019)
http://ai.stanford.edu/blog/contextual/
专知便捷查看
便捷下载,请关注专知公众号(点击上方蓝色专知关注)
后台回复“CWR” 就可以获取《【斯坦福大学AI】BERT, ELMo, & GPT-2:上下文化的单词表示是怎样的?》专知下载链接



登录查看更多
相关内容
Arxiv
3+阅读 · 2019年2月11日
Arxiv
15+阅读 · 2018年10月11日



相关VIP内容
相关资讯
相关论文
Arxiv
3+阅读 · 2019年2月11日
Arxiv
15+阅读 · 2018年10月11日