论文导读 | AI研究新利器Etymo,妈妈再也不用担心我找不到论文!

更多干货内容请关注微信公众号“AI 前线”,(ID:ai-front)
论文标题:
Etymo: A New Discovery Engine for AI Research
作者: W Zhang, J Deakin, N J. Higham, S Wang [The University of Manchester & JD.com]

全球科研产出的快速增长给信息检索带来了新的挑战。这个问题在 AI 研究领域尤为严重。例如在 arXiv (https://arxiv.og) 上,每周大约有 500 篇与 AI 相关的新论文出现。新论文的激增使研究人员很难跟进 AI 领域最新的进展。为了应对这一挑战,作者开发了 Etymo,一个面向学术搜索的全新发现引擎。
学术论文的影响力一般都用引用率来衡量,然而最新发表的论文是几乎没有引用的,所以很难判断他们的含金量。作者通过建立一个基于相似性的网络,并且利用网络的信息来完成信息索引的任务。那么如何对非超文本进行连接呢?作者从论文全文的分布向量表示中推断连接,即如果两篇论文的向量表示之间的夹角余弦相似度较高,就将这两篇文章连接起来。推断连接与引用网络较相似,但是超链接和生成连接之间的类比并不完美。自动生成的连接是噪声更多的信息源,并且更容易失效。
作者通过探索论文在社交媒体上的活动(例如在 Twitter 上被转发的数量),以及用户反馈的信息,对网络的连接进行增强或减弱,来提升排序算法,并且过滤掉不需要的论文。产生的结果图用于排序、推荐和可视化。作者结合 PageRank 和 Reverse PageRank(反向 PageRank)对论文进行排序。在反向 PageRank 中,作者将图的边进行方向反转,再计算 PageRank。作者设计了一个新的搜索界面,将搜索结果显示为一个项目列表和项目关系图。该新界面可以让读者快速锁定相关文献。
下图显示了 Etymo 的依赖图。
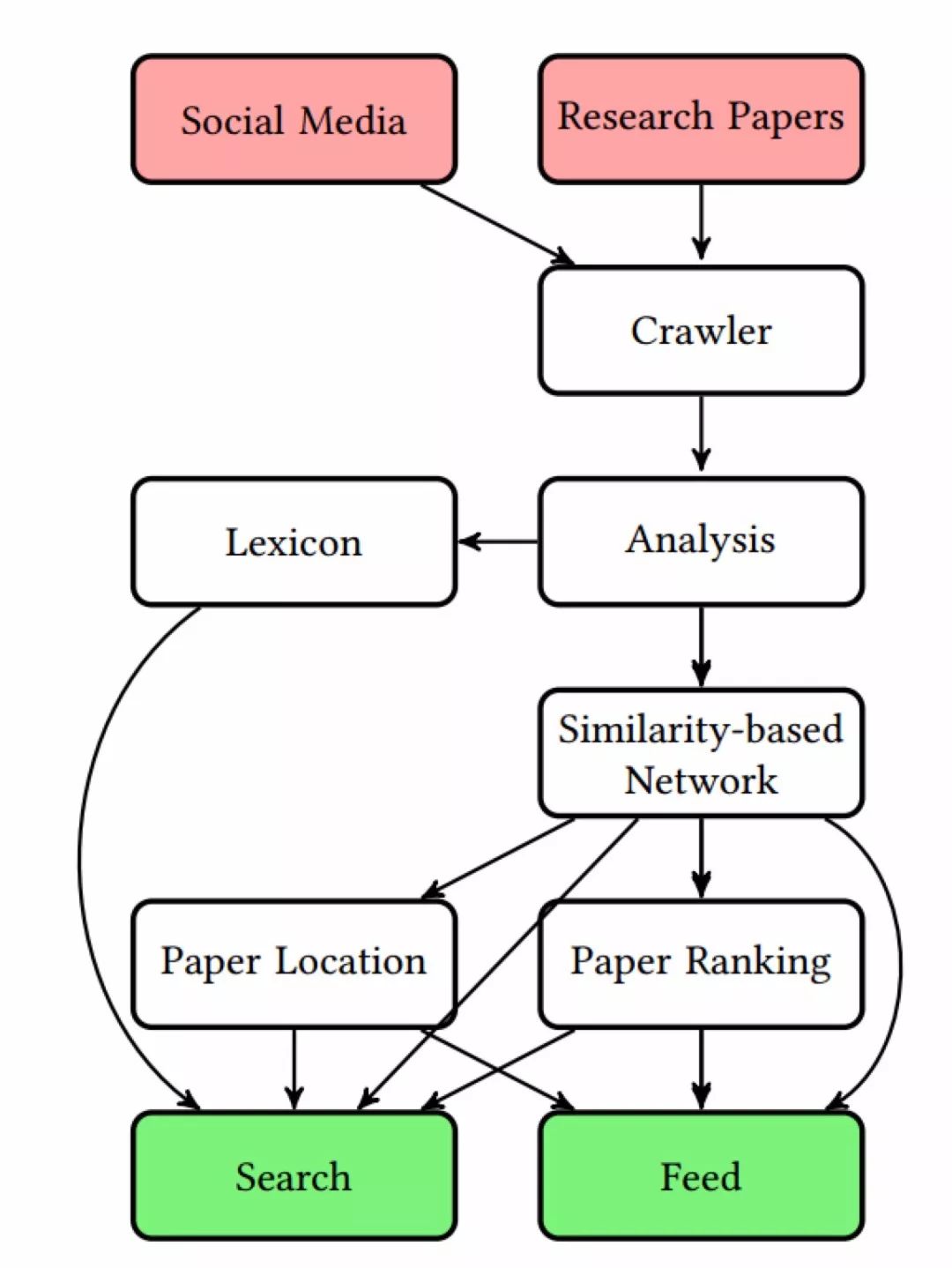
Etymo 用几个网络爬虫从不同的期刊网站下载论文。数据库中的每篇论文既有 PDF 版,也有 metaData 版本,包括作者姓名、期刊名、论文摘要以及发表日期。
在分析(Analysis)阶段,首先用 pdftotext 将 PDF 全文转换成文本,然后用 Doc2Vec 算法和 TF-IDF 算法将文档 d 表示为一个数学向量。内容类似的论文在向量空间中距离相近。该内容相似性信息随后被用于构建针对数据库中所有论文的基于相似性的网络(Similarity-based Network)。作者用这两种算法分别构建了两个网络,实验证明两个网络的结合具有最好的效果。作者使用 t-SNE 来确定论文位置(Paper Location),利用网络中心性算法对论文排序(Paper Ranking),一篇论文在网络中的节点度(和该节点相关联的边的条数)越高,该论文就越重要。TF-IDF 的全局词条权重生成了一个词库(Lexicon),随后应用于搜索中。Etymo 主要由一个搜索引擎(Search)和一个反馈引擎(Feed)构成,两个引擎的结果分别显示成列表和图示。
Etymo 有两个重要特性,能够帮助它产生更有用的搜索结果。
首先,Etymo 利用文档的向量表示来构建基于相似性的网络,在网络中论文作为节点,相似的论文互相连接。网络是自适应的,通过用户反馈机制:用户评分、点击以及 Twitter 转发次数来强化“正确的”连接,弱化“不重要的”连接。得到的网络随后用于排序和推荐。其次,作者设计了一个新的搜索界面,搜索结果不只通过传统的项目列表显示,还有反映论文之间关系的可视化图,以帮助读者快速找到相关论文,并对研究领域有一个整体的了解。
构建基于相似性网络的第一步是用数学向量表示文档。作者使用了文档的分布式表示算法 Doc2Vec,和词袋模型 TF-IDF,采用向量间的夹角余弦相似度来构建网络。该方法的一个潜在问题是它无法衡量论文质量的好坏,于是作者利用用户反馈来调整网络结构,为重要的论文赋予更高的权重。
数据库中每一个论文对都对应着一个相似度的值,如果相似度高于给定阈值,则将这两篇论文连接起来。对于新加入的论文,直接计算论文与数据库中全部论文的相似度,计算量过大,因此新加入的论文只与前 k 篇高质量论文计算相似度。
如果一篇论文含有大量与 AI 领域相关的关键词,那么即使论文质量不高,它在网络中的节点度也很高,在排序中也能得到很高的评分。针对这一问题,作者用投票来调整网络结构:(1)利用用户打星来增加节点连接边的权重,从而增加连接边的数量(节点度)。也就是说,得到用户评星多的论文,与其他论文的连接更多。(2)利用用户库来推断节点度:增加在某个用户的库中出现的论文之间的连接权重。(3)对于排序很靠前,但点击量很少的论文,弱化其节点度。
利用论文发表日期这一信息,将经过调整之后的无向网络转化成有向网络。这样,当网络中出现新论文时,如果这篇新论文与以前的论文有相似的内容,或者用户数据显示他们相关,那么界面就会同步“推荐”一篇以前的论文。
Etymo 的搜索结果不仅仅有列表,还有论文内容相似关系的可视化图。
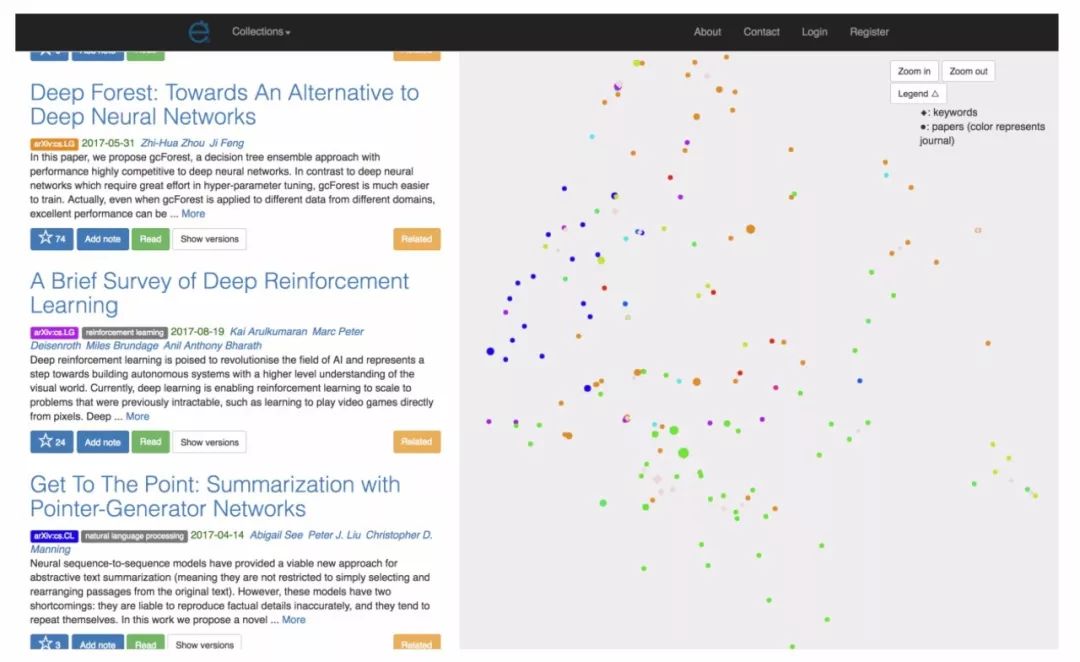
可视化结果节省了查找相关研究的时间。一般搜索结果显示的是搜索排名前 10 的论文,以及与他们相关的论文,但是传统的列表界面不能很好的显示出全部的信息,在 Etymo 中,用户可以同时查看列表中排名前 10 的论文并且在图示中找到相关论文。
Etymo 数据库中有超过 36000 篇文章,而且还在以每周 500 篇新文章的数量增长。分析阶段用的是 Amazon Elastic 云计算(Amazon EC2)m4.xlarge 平台实例,有 16 个 vCPU 和 64GB 内存。
Etymo 的数据库每天更新。更新时,首先用 Doc2Vec 和 TF-IDF 算法对每篇新文章建立表示向量。然后用 t-SNE 找到文章的位置,将 1000 维的表示向量降维到 2 维,即文章的坐标(x,y)。基于相似性的网络的节点数量对应数据库中文章的数量。实验中发现,基于网络的评分可以通过高亮重要文章来优化搜索结果。

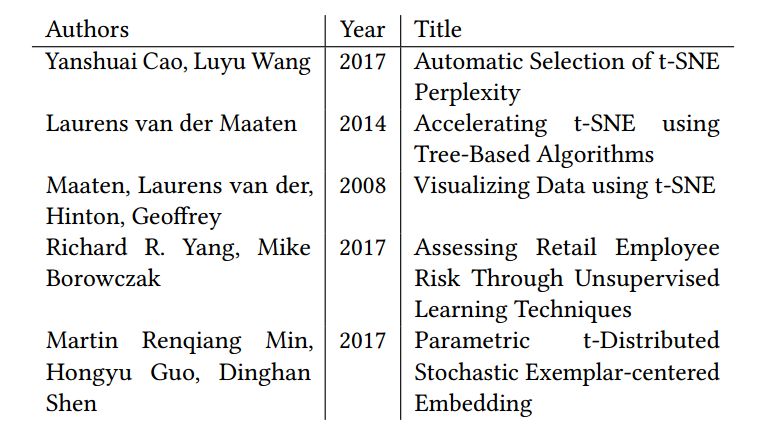
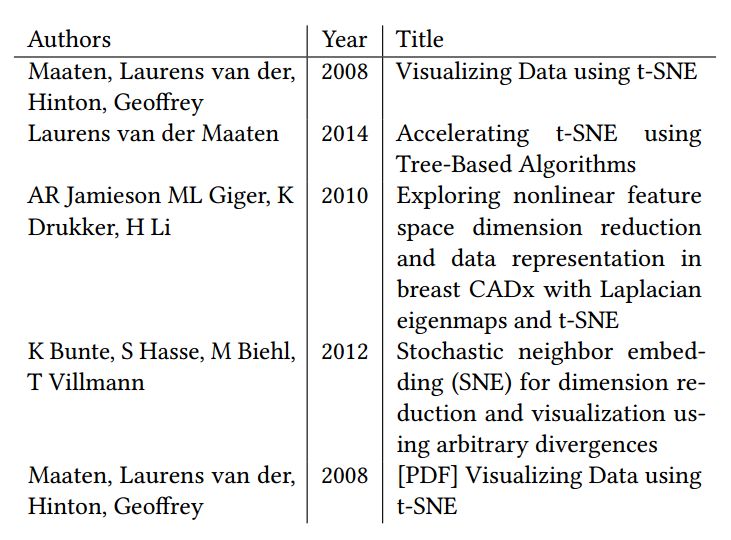
表 1 是在基于相似性的网络中采用 PageRank 和反向 PageRank 进行排序的,搜索关键词“t-sne”的前 5 个搜索结果。表 2 是不采用相似性网络的结果。Maaten 和 Hinton 的“Visualizing Data using t-SNE”是最早提出 t-SNE 的文章,可以认为是该关键词下重要性很高的文章。可以看出,采用基于相似性网络的搜索对于更重要的文章给出了更多权重。表 3 是 Google Scholar 搜索结果,与之相比,作者的搜索方法包括了最近新发表的论文。
科研过程中,在新论文被别的论文引用前,很难判断它的价值。Etymo 通过利用论文的完整内容和社交媒体数据,提出了一个基于相似性网络的方法来优化新发表论文的搜索结果。用户界面将结果列表和关系图结合起来,为研究人员发现感兴趣的新论文节省了大量时间。
论文原文链接:
https://arxiv.org/abs/1801.08573
Etymo 官方网站:
https://etymo.io
点击下方图片即可阅读

送书 | AI 插画师:如何用基于 PyTorch 的生成对抗网络生成动漫头像?

人工智能正在改变我们的生活。对于大多数的新手来说,如何入手人工智能其实都是一头雾水,比如到底需要哪些数学基础、是否要有工程经验、对于深度学习框架应该关注什么等等。
在《人工智能基础课》专栏里,王天一教授将结合自己的积累与思考,和你分享他对人工智能的理解,用通俗易懂的语言从零开始教你掌握人工智能的基础知识,梳理出人工智能学习路径,为今后深耕人工智能相关领域打下坚实的基础。

点「阅读原文」,免费试读精品文章。