抢先 | 知识图谱论文清单,高阶炼丹师为你逐一解读

来源:开放知识图谱
本文干货,建议收藏。
精选6篇来自顶会知识图谱相关论文,带你快速了解知识图谱领域最新研究进展。
EMNLP 2018


论文解读 | 康矫健,浙江大学硕士,研究方向为知识图谱、自然语言处理
1. 论文动机
当前知识库补全的方法主要是将实体和关系嵌入到一个低维的向量空间,但是却只利用了知识库中的三元组结构 (<s,r,o>) 数据,而忽略了知识库中大量存在的文本,图片和数值信息。
本文将三元组以及多模态数据一起嵌入到向量空间,不仅能够使链接预测更加准确,而且还能产生知识库中实体缺失的多模态数据。
论文亮点如下:
通过不同的 encoders,将多模态数据嵌入成低维向量做链接预测;
通过不同的 decoders,能够产生实体缺失的多模态数据。
2. 模型
多模态数据的嵌入
1. 结构化数据:对于知识库中的实体,将他们的 one-hot 编码通过一个 denselayer 得到它们的 embedding;
2. 文本:对于那些很短的文本,比如名字和标题,利用双向的 GRUs 编码字符;对于那些相对长的文本,通过 CNN 在词向量上卷积和池化得到最终编码;
3. 图片:利用在 ImageNet 上预训练好的 VGG 网络,得到图片的 embedding;
4. 数值信息:全连接网络,即通过一个从的映射,获得数值的 embedding;
5. 训练:目标函数(cross-entropy):
其中:
是一个 one-hot 向量。如果知识库中存在 <s, r, o> 这个三元组,
值为 1,否则
值为 0。
是 <s, r, o> 模型预测出来的这个三元组成立的概率,它的值介于 0 到 1 之间。
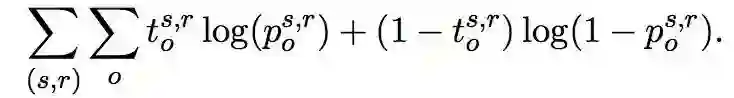
解码多模态数据
1. 数值和类别信息:利用一个全连接网络,输入是已经训练好的向量,输出是数值和类别,损失函数是 RMSE(数值)或者 cross-entropy(类别);
2. 文本:利用 ARAE 模型,输入是训练好的连续向量,输出是文本;
3. 图片:利用 GAN 模型来产生图片。
3. 实验
本文作者在 MovieLens-100k 和 YAGO-10 两个数据集上面引入了多模态数据,其中 MovieLens-100k 引入了用户信息文本,电影信息文本,电影海报;YAGO-10 也为实体引进了图片,文本,数值等信息。
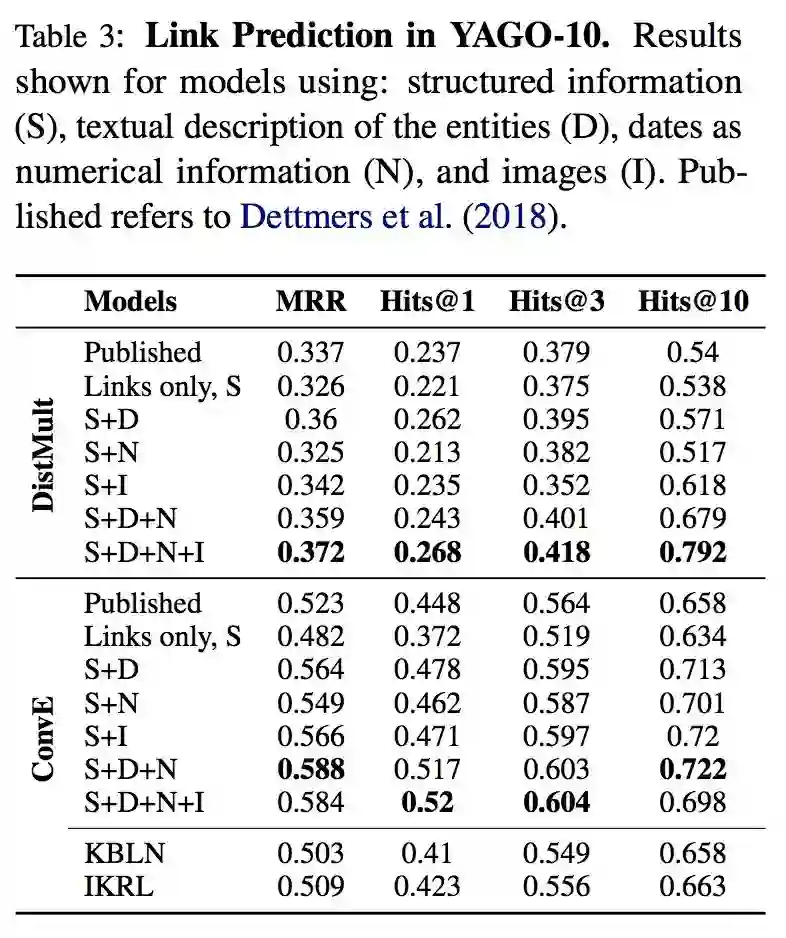
链接预测
可以看到在引入了实体文本描述,图片和数值之后,利用之前的嵌入模型,达到了 SOTA 的效果。
生成多模态数据
可以看到,引入了多模态数据之后,产生出来的文本和图片的质量比起仅仅依靠知识库原本就存在的三元组信息产生的文本和图片的质量要高。

4. 总结
本文的创新点是引入了多模态数据来做知识库中的链接预测和生成实体缺失的多模态数据。但是不足之处在于不知道到底引入的哪一部分多模态数据对最终的链接预测产生提升,以及产生的多模态数据质量不是很理想。这有待于后续工作的改进。
ISWC 2018


论文解读 | 曹二梅,南京大学硕士,研究方向为知识图谱、知识融合
信息抽取通常关注于抽取可辨识实体之间的关系,例如 <Monterey, locatedIn,California>。但是,除了说明具体实体之间的关系,文本中也经常含有计数信息,表明与某个实体有特定关系的对象的数量,而未提及具体对象本身,例如“California is divided into 58 counties”。这种计数量词可用于诸如查询应答,知识库管理等任务,但被先前的工作忽略了。
本文开发了第一个完整的从文本中提取计数信息的系统 CINEX,将知识库中的事实计数作为训练种子,采用远程监督的方法抽取文本中的计数信息。实验表明,在人工评估的 5 个关系上,CINEX 的平均抽取精度达到了 60%。在大规模实验上,对于 Wikidata 的 110 种不同关系,CINEX 能够断言 250 万事实的存在,比这些关系现有的 Wikidata 事实多 28%。
1. 概念
本文用 SPO 形式的计数语句(Counting Statement)来描述知识库中的计数信息,主要关注对于一个给定的 SP 对,参数 O 的数量。
计数语句的形式化表示为 <S, P, ∃n>,其中,S 是 subject,P 是 predicate,n 是一个自然数(包括 0)。例如,语句 “President Garfield has 7 children” 将表示成 <Garfield, hasChild,∃7>。在 OWL 描述逻辑中,上述语句的形式化描述如下:

2. 方法
CINEX 的目标是解决文本中计数量词的抽取问题,问题定义如下:
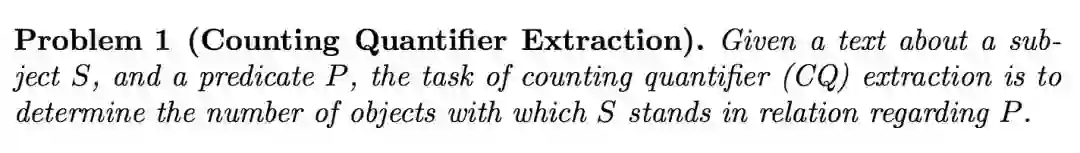
CINEX 将知识库中已有的事实计数作为种子,采用远程监督的方法抽取文本中的技术信息。远程监督作为知识库信息抽取的主要方法,也是解决本文问题的一种相当自然的方法。
不过,用远程监督解决计数信息抽取,需要解决以下几点挑战:
1. 种子质量:与通常意义下的 SPO 事实抽取不同,本场景下知识库的不完备不仅会导致训练种子数量的减少,还会导致系统地低估实际事实的数量。例如:知识库只知道特朗普的 3 个孩子,而实际上特朗普有5个,这会导致系统奖励 “owns three golf resorts” 这样的模式,而惩罚 “his five children”。
2. 数据的稀疏性:对于很多关系,文本表达计数信息的方式相当稀疏且高度倾斜。例如,一般人的 children 很少被提及;对于音乐家来说,赢得的第一个格莱美奖通常比之后的获奖更多被提及,因此对“他/她的第一个奖项”的模式会被给予过度的重视。还有,音乐乐队的成员数量通常约为 4,这使得很难学习到乐队成员数量非常大或非常小的模式。
3. 语言多样性:计数信息可以用各种语言形式表达,如冠词(“has a child”),基数词(“has five children”),序数词(“her third husband”),表数量的名词短语(‘twins’,‘quartet’),表存在与否的副词(‘never’,‘without’)。
CINEX 针对上述挑战给出了对应的解决方法:
对于挑战 1,CINEX 通过将数量的匹配条件放宽到比知识库事实计数更高的值,同时将训练种子限制于知识库中信息更完备的流行实体来处理。对于挑战 2,CINEX 使用信息熵来度量 numbers,过滤掉不提供信息的 numbers。对于挑战3,CINEX 通过仔细整合中间结果来处理。
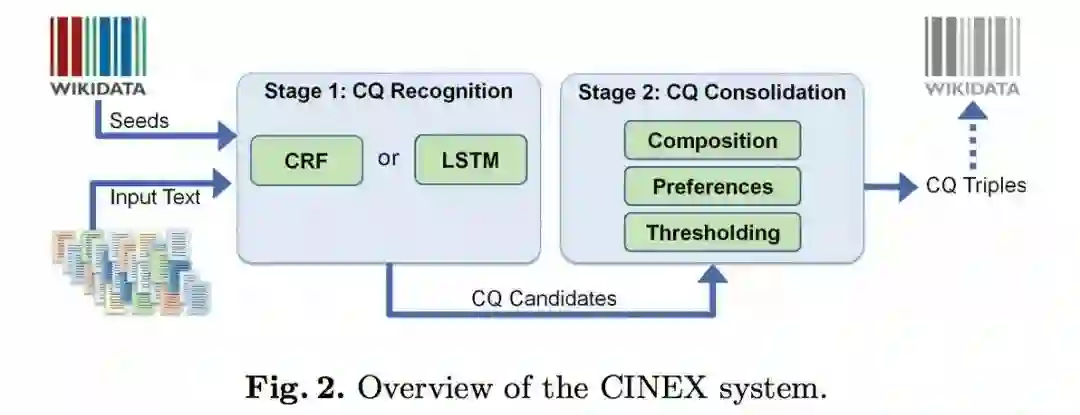
Fig.2 给出了 CINEX 系统的框架,系统将整体任务分为两个阶段:
计数量词的识别
CINEX 将其建模为序列标注问题,对每一个句子操作并且针对每一个谓词P单独学习。首先通过检测文本中指示计数信息的术语(基数,序数和数值项等)预处理输入的句子,再用 CRF++ 模型以及 bidirectional LSTM-CRF 模型为每个感兴趣的谓词 P 学习一个序列标注模型,用于计数量词的识别。
计数量词的合并
将第一阶段识别出的多个表示计数或者组合信息的中间结果,合并为对象数量的单个预测。
整合算法如下:
1. 对需要组合的计数信息求和,可信度得分设为被组合信息中最高的值;
2. 选择每一种计数信息的预测结果。对于基数词和数值项,选择高于设定阈值的计数信息中可信度得分最高的;对于序数词,不论可信度得分如何,总是选择可信度得分最高的;
3. 根据计数信息类型排序,根据如下顺序选择最终结果。
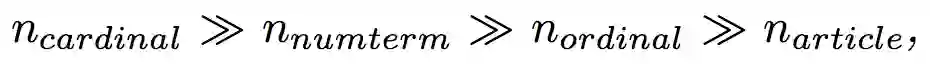
3. 实例
计数量词的识别
给定句子“Jolie brought her twins , one daughter and three adoptedchildren to the gala”,计数量词识别阶段预处理以及序列标注的结果如下:
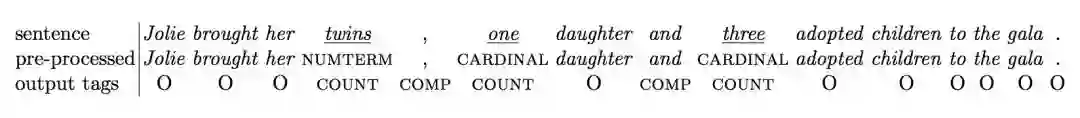
计数量词的合并
给定 SP 对 <AngelinaJolie, hasChild>,计数量词的识别结果如下:

整合算法第 1 步会合并句子中的计数信息 0.3 和 0.5,将其相加得到 0.5,句子中的计数信息 0.1 和 0.2 将相加得到 0.2。第 2 步 0.5 被选为可信度得分最高的基数词,0.8 被选为可信度得分最高的数值项,0.5 被选为排序最高的序数词。第 3 步,根据排序偏好以及设置的可信度阈值,基数词 0.5 或 0.8 将被作为最终预测结果。
4. 实验
数据集:Wikidata(知识库),Wikipedia(文本)。
实验结果
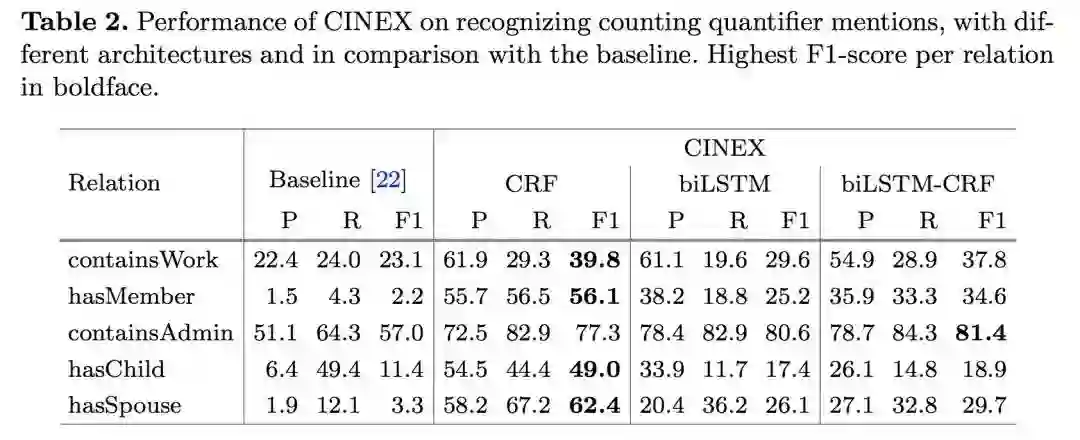
从 Table 2. 可知,计数量词的识别基于特征的 CRF 模型效果最好,神经网络模型容易过拟合。同时,CINEX-CRF 也是在整合和端到端任务中识别计数信息性能最佳的系统。
对于各种类型的计数术语,由 Table 4. 的实验结果可知,考虑数值项和冠词有利于改善覆盖率,考虑组合计数信息以及除基数词之外的其它类型术语,有利于提高准确性和覆盖率。
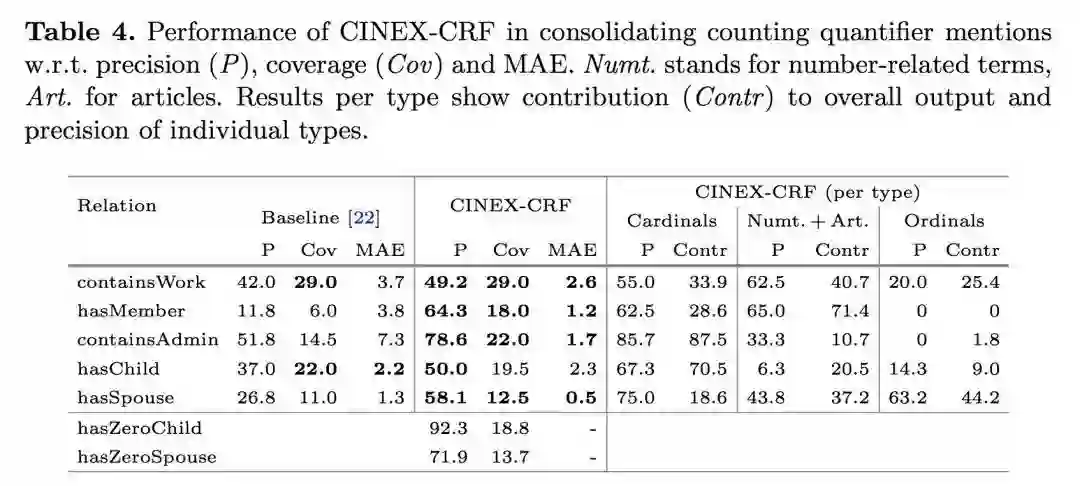
对于 Wikidata 的 110 种关系,CINEX 抽取了 851K 计数量词事实,断言了 250 万事实的存在,比这些关系现有的 Wikidata 事实多了 28.3%。
ACL 2018


论文解读 | 谭亦鸣,东南大学博士,研究方向为知识库问答、自然语言处理
1. 论文动机
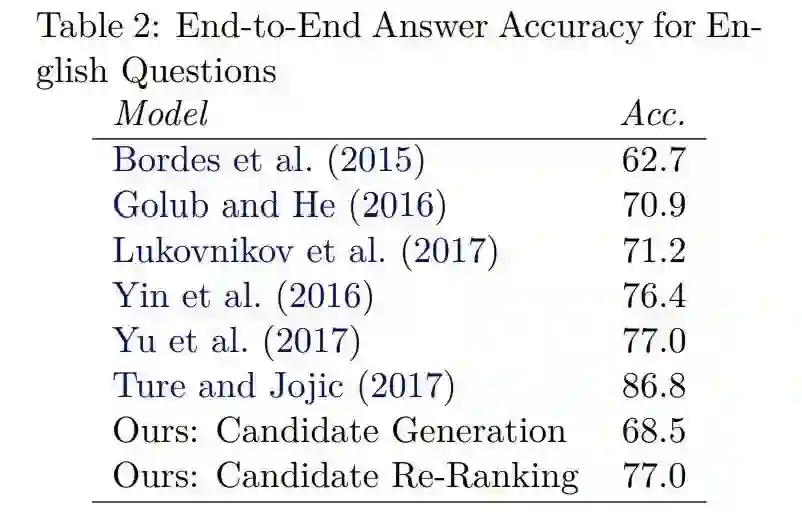
作者思考,如果一个人懂多个语言,那么只要他知道某一语言的某个事实,就能以它作为另一语言问题的答案,同时希望证明计算机是否也能做到这一点,并完成混合语言的简单问题知识问答任务(Code-Mix Simple Questions KBQA)。
所谓 Code-Mix 即是指 QA 中的问题不是由单一语言构成,以中英双语举例: “我怎么知道本文提出的 model 是否 work 呢?”
2. 方法
作者将提出的 CMQA 模型分为两个步骤:候选生成和候选重排序。
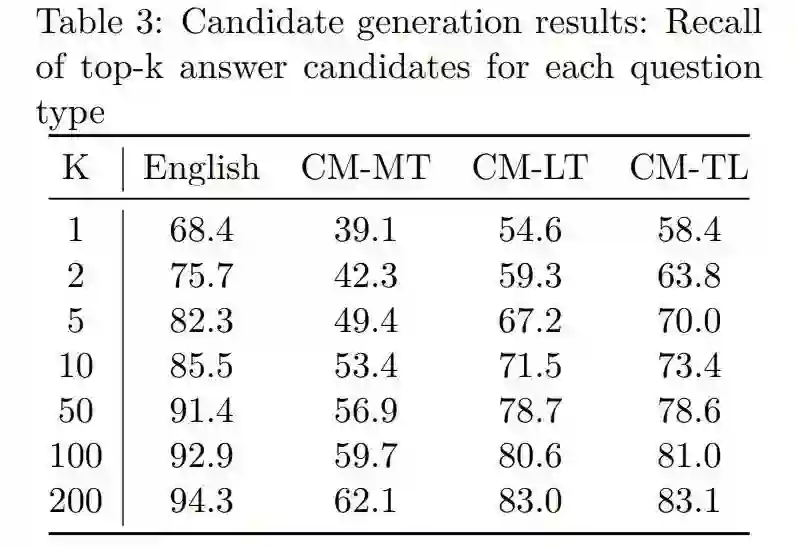
候选生成
这里的候选指的是 KB 中与问题相关的三元组,作者提出的思路是利用检索模式,缩小候选三元组的搜索空间。通过使用 Solr(一个开源的倒排索引查询系统),将 Freebase 中所有三元组编入索引,而后将 Question 作为检索的 Query 得到 top-k 个候选三元组,检索的排序打分参考 BM25。
注意:在这里检索仅支持英文,故混合语言问题中其他非英语成分对检索没有贡献,那么如果问题的 entity 是非英语的话,是否可能引入大量与问题无关的三元组呢。
候选重排序
本文的主要工作就是设计了一个重排序模型 Triplet-Siamese-Hybrid CNN (TSHCNN),采用 CNN(卷积网络)学习输入文本的语义表示。考虑到不同语言的词序差异性,作者认为 CNN 可以学习到输入文本中的词汇顺序特征以及短语顺序特征。
对于排序过程,文章将其抽象为一个多分类问题,即每个答案都是一个潜在类别,且对应的问题数量可能很小甚至为0,这里主要通过匹配目标实体和谓词来做答案筛选。直观思路是通过构建一个问题-答案间的相似度打分作为参照指标用于排序,作者在这里引入 Siamese Networks 方法完成上述目的。
整体模型框架如图:
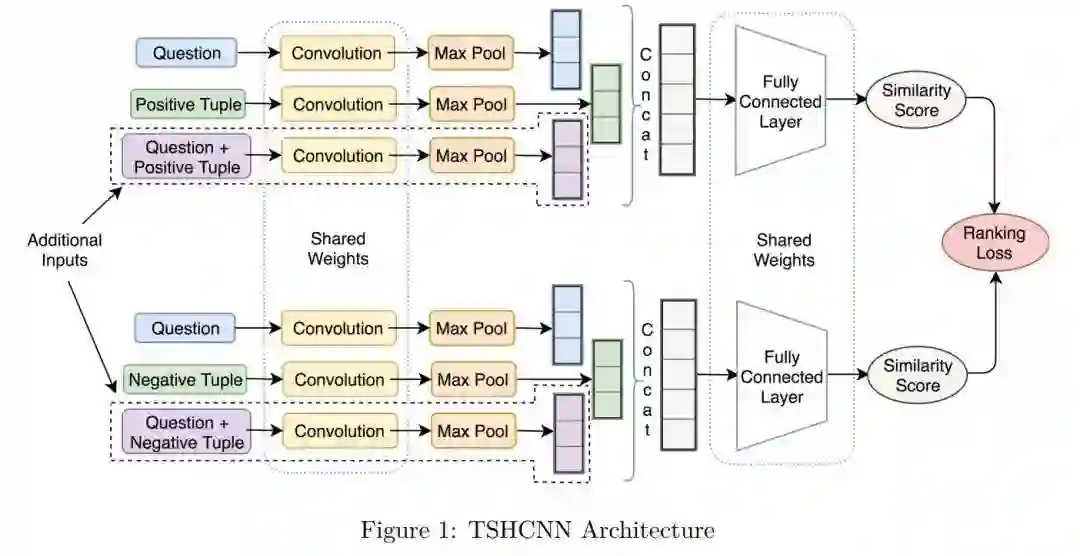
模型由两个通道组成,分别用于学习正例与负例,每一通道有三个输入:
1. 问题
2. 正(负)例样本
3. 由正(负)例样本与问题联合构成的附加输入
网络结构由卷积层->池化层->向量关联->全连接层构成,两个通道中对应位置的网络共享权重参数。
语言转换
处理多语言问题还是绕不开语义鸿沟,为了将两种语言关联起来,作者采用了双语词嵌入+K 近邻组合的策略,构建通用跨语言词嵌入空间,将双语词汇投影到该空间中,再引入 K 近邻方法构建双语词汇关联。
3. 实验
数据:SimpleQuestions (Bordes et al., 2015) dataset,75.9k/10.8k/21.7k training/validation/test。
词嵌入预训练:English,Hindi Fasttext (Bojanowski et al., 2016),English-Hindi bilingual Smith et al.(2017) to obtain。
自建数据集:Hindi-English混合语言问句,规模:250,简单问题,每句对应一个 Freebase 三元组。
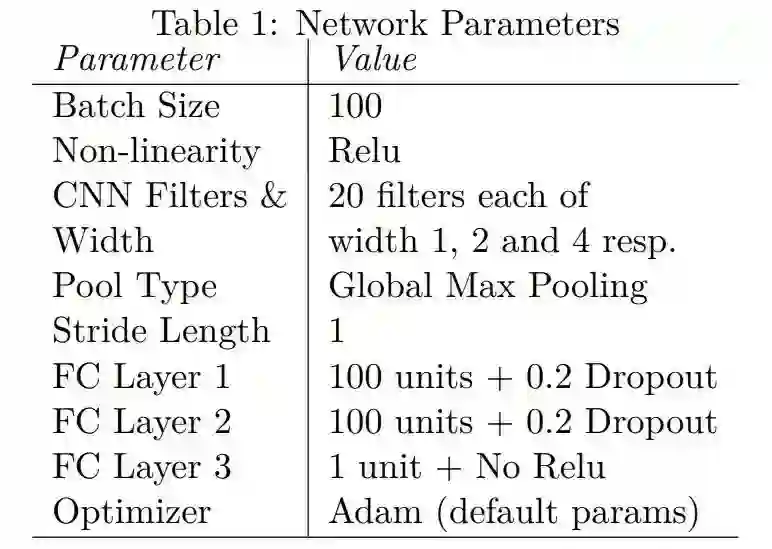
神经网络的超参数设定如图:
简单知识问答实验结果:
候选三元组生成实验结果:
双语端到端问答实验结果:
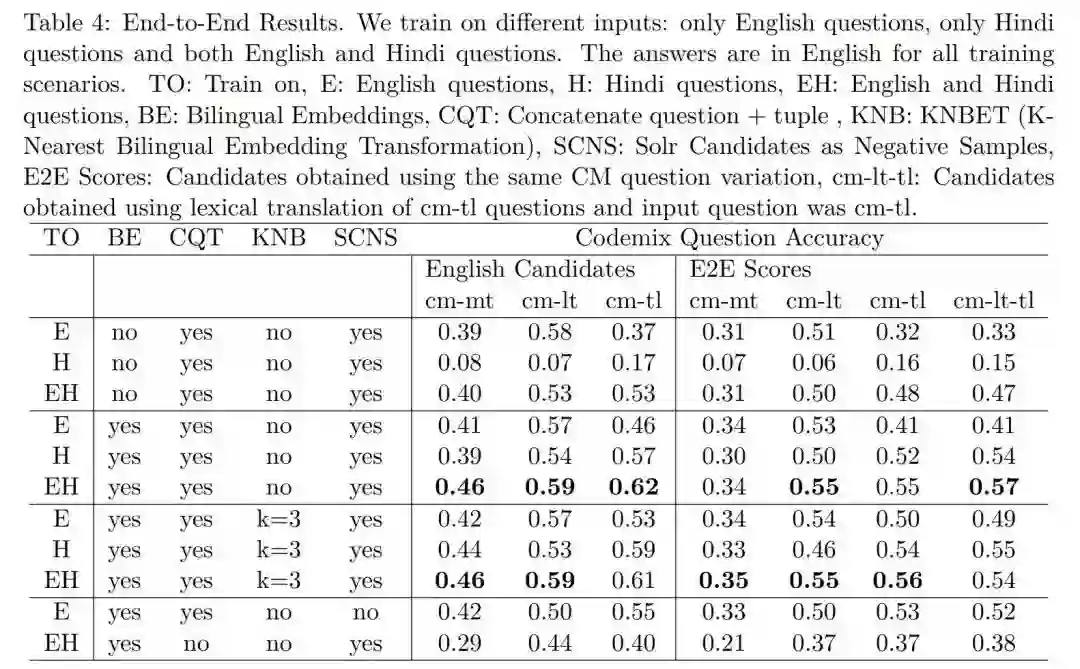
部分问答效果示例:

4. 总结
作者认为本文的贡献包括:
在基于“英语语料,有噪声的海地语监督,和不完美的双语词嵌入”情况下,成功回答了混合语言问题;
提出 TSHCNN 模型用于联合学习候选重排序;
构建了一组 250 规模的海地语-英语混合语言问题数据集,并且这个数据集的答案来源于 SimpleQuestion 数据集,且可以映射到 Freebase 知识库上;
本方法是作者所知目前第一个端到端的混合语言知识问答方法。
NAACL 2018


论文解读 | 李娟,浙江大学直博生,研究方向为表示学习
本文针对在生成负样本时有大部分负样本可以很好地和正样本区分开,对训练的影响不大,提出了使用生成对抗网络(GANs)的方法,解决生成的负样本不够好的问题。它是第一个考虑用对抗学习生成负样本的工作。
1. 方法
设计模型时,本文把基于概率的 log 损失的表示学习模型作为生成器得到更好的负样本质量;使用基于距离的边缘损失的表示学习模型作为判别器得到表示学习的最终结果。
由于生成器的步骤离散导致不能直接运用梯度反向传播,对此作者使用了一步强化学习设置,使用一个降低方差的强化方法实现这个目标。
方法上本文先列举了两种损失函数:
Margin loss function
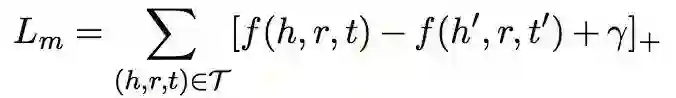
Log-softmax loss function
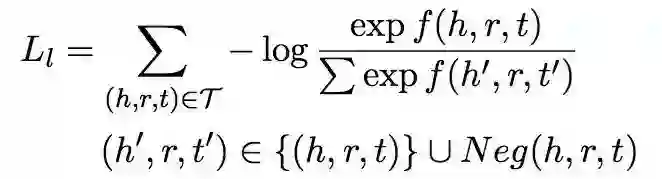
再通过分析均匀负采样的缺陷:等概率替换会使容易区分的负样本对学习的贡献较小,会让模型学到一些简单的特征,而不是尽可能去理解语义,对此作者认为使用 log 损失函数从替换实体得到的所有负样本中筛选出更有用的负样本很有必要。
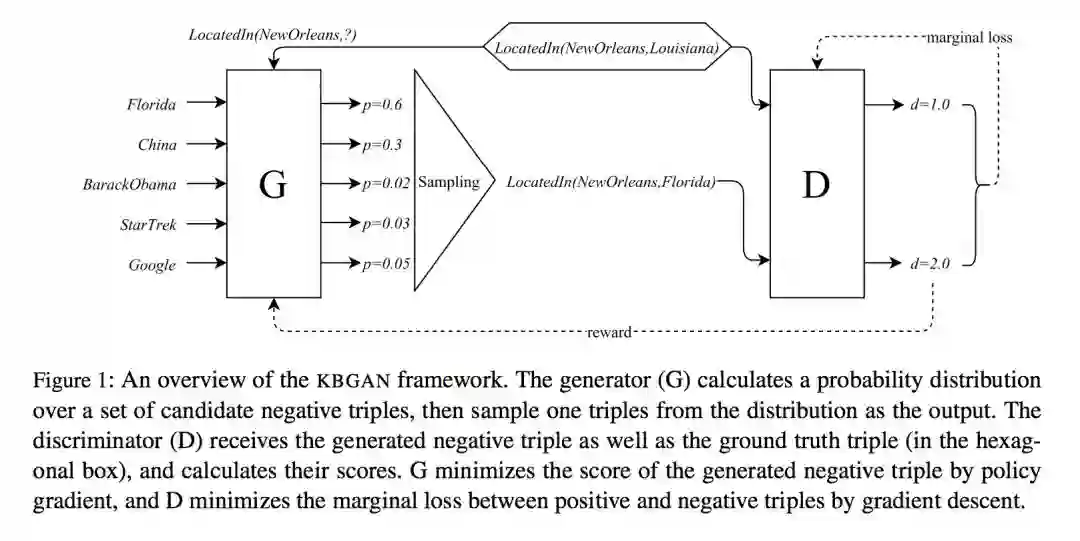
最后通过模型图我们发现论文使用 softmax 概率模型为生成器 G,通过概率分布进行采样;判别器部分 D 接收生成的负样本和 ground truth triple 并计算分数;G 通过梯度策略最小化生成的负三元组的分数,D 通过梯度下降最小化正样本和负样本的边缘损失。
假设生成器得到的负样本概率分布为
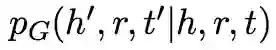
那么判别器的 score function 为:
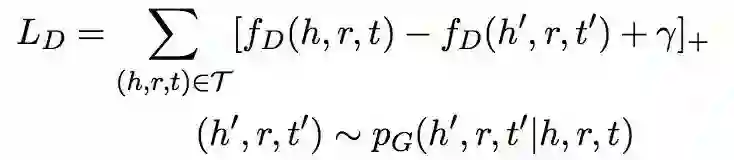
生成器的目标是最大化负距离的期望为:
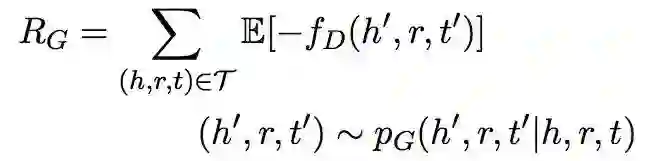
由于 RG 是一个离散采样步骤得不到梯度,本文借鉴了其他论文提到的梯度策略理论获取梯度进行优化。
这一部分论文把这个过程对标到强化学习,认为生成器是 agent,判别器是 environment, (h, r, t) 是 state,负样本概率分布 PG 是 policy,(h’, r, t’) 是 action,-f_D(h’, r, t’) 是 reward,认为是 one-step RL 是在每个 epoch,actions 不会影响 state,但每个 action 后会重新从一个不相关的 state 开始;为减小算法方差而不引入新参数,作者从 reward 减掉一个常量。
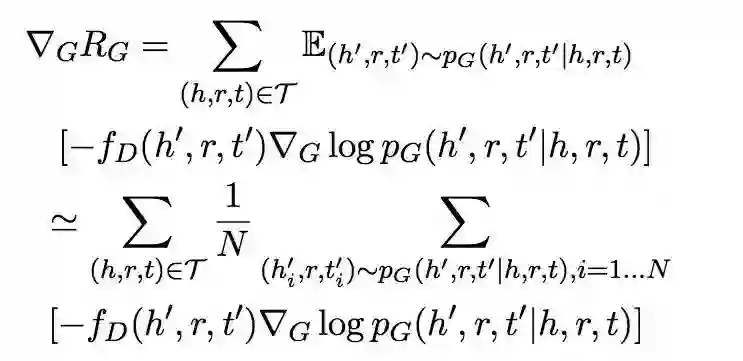
概率分布的计算使用以下公式,fG(h, r, t) 为生成器的 score function:
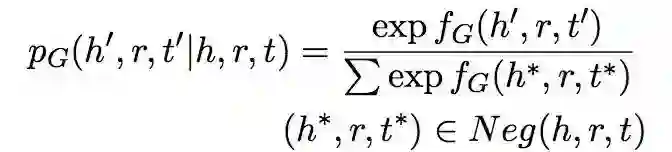
算法伪代码如下:

2. 实验
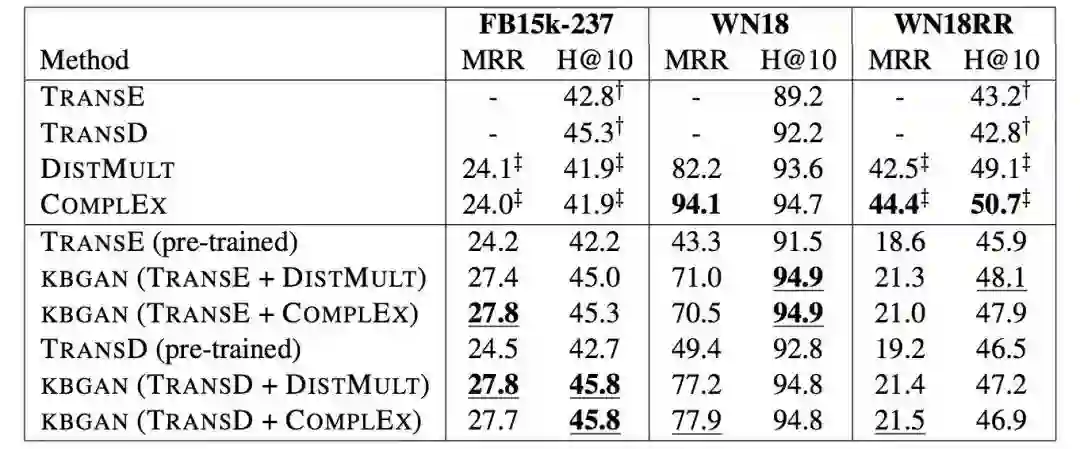
论文选用的数据集有 FB15K-237, WN18, WN18RR,结果发现使用 DISMULT 或 COMPLEX 作为生成器都不会对性能有较大影响,且 TransD, TransE 在 KBGAN 中很明显优于它们的 baseline。
ACL 2018


论文解读 | 张清恒,南京大学硕士,研究方向为知识图谱
1. 论文动机
知识图谱的嵌入表示在近几年已经成为一个非常活跃的研究领域,众多相关方法相继被提出,这些嵌入方法是将知识图谱中的实体和关系表示成同一向量空间中的向量。虽然知识图谱的嵌入表示在各种任务中被广泛应用,但是对嵌入表示的几何理解尚未被探索,本文旨在填补这项空白。
本文深入分析知识图谱嵌入表示的几何形状,并分析其与任务性能和其他超参数之间的关联。通过在真实数据集上进行广泛的实验,本文发现了一些值得注意的现象,例如不同类别的嵌入方法学习到的嵌入表示在几何形状上存在明显差异。
2. 度量标准
ATM
ATM(alignment to mean)是指向量集合 V 中的一个向量 v 与平均向量的余弦相似度。
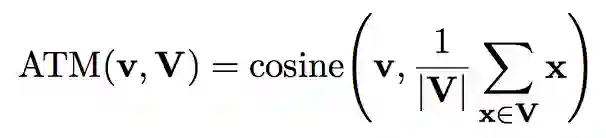
Conicity
Conicity 是指向量集合 V 中所有向量 ATM 的平均值。
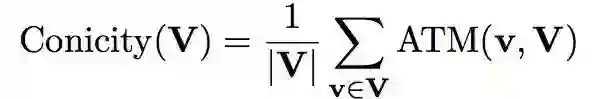
VS
VS(vector spread)是指向量集合 V 中所有向量 ATM 的方差。
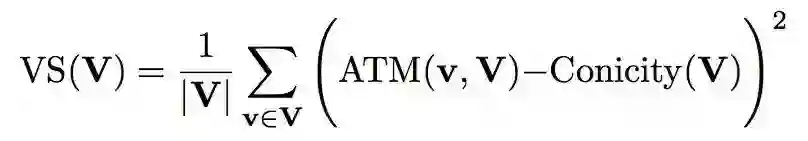
图 1 给出了一个实例来帮助理解这几个指标,图中是一个三维坐标系(展示的点是随机生成的),左图表示的是高锥度(conicity)和低向量分散度(VS)的情形,而右图表示的是低锥度和高向量分散度的情形。
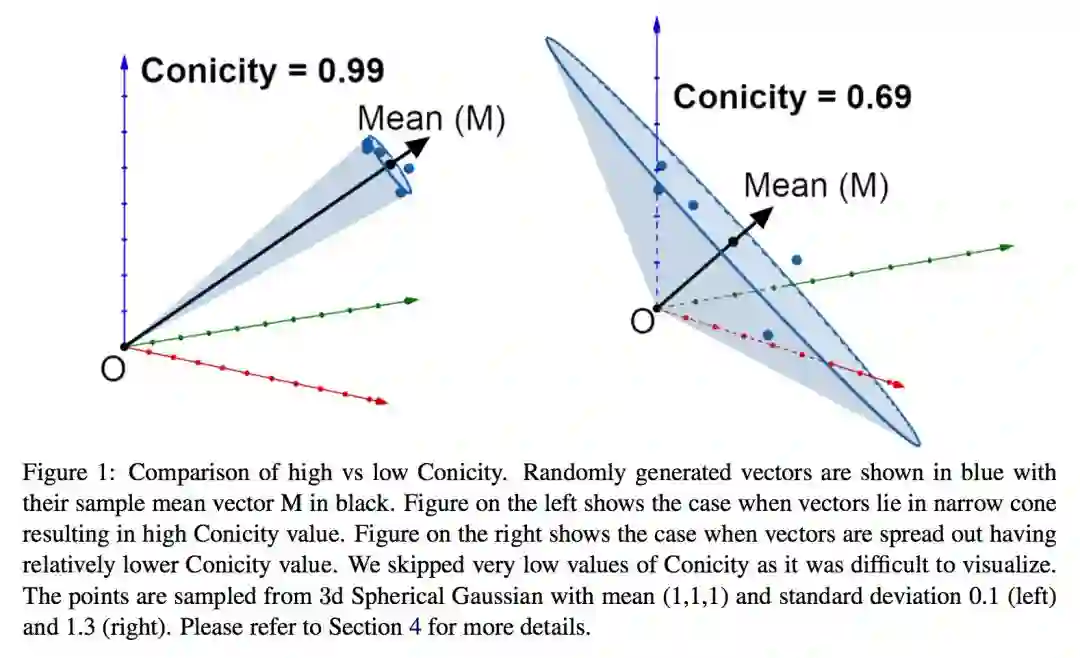
AVL
AVL(average vector length)是指向量集合 V 中所有向量的平均长度( L2 范数)。
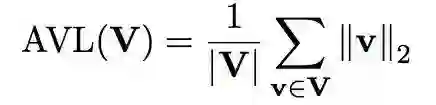
3. 实验分析
本文主要考虑 6 个知识图谱的嵌入表示模型,并把 6 个方法分为两类。一类是加法(additive)模型,有 TransE [2]、TransR [3] 和 STransE [4];另一类是乘法(multiplicative)模型,有 DistMult[5]、HolE[6] 和 ComplEx[7]。同时,本文采用了两个常见数据集 FB15K 和 WN18。
本文主要从以下 4 个发现展开实验分析:
3.1 模型类型对几何形状的影响
不同模型在实体向量的几何形状上存在明显差异。乘法模型的 ATM 值均为正值且向量分散度较低。加法模型此形成鲜明对比,加法模型的 ATM 值正负皆有且分布较为均衡,同时向量分散度较高。
这说明乘法模型得到的嵌入向量不是均匀的分散在向量空间中,而加法模型得到的嵌入向量则是均匀的分散在向量空间中。
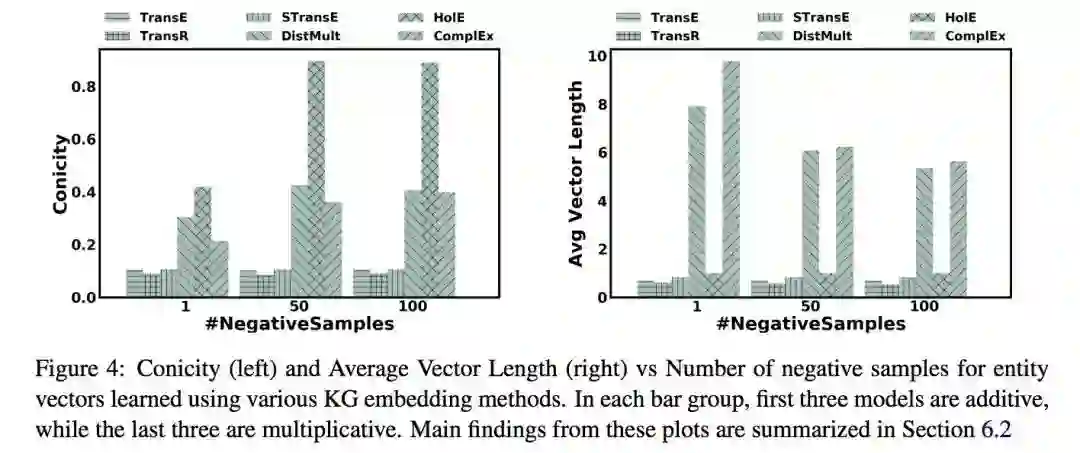
3.2 反例数量对几何形状的影响
乘法模型的锥度(conicity)随着反例数量的增加而增大,而加法模型的锥度对反例数量不敏感。在平均向量长度(AVL)方面,乘法模型中的 DistMult 和 ComplEx 随着反例数量的增加而减小,HolE 则几乎没有变化,这是因为 HolE 把实体向量限制在了单位球内。所有加法模型的 AVL 也对反例数量不敏感,而它们也有和 HolE 类似的限制。
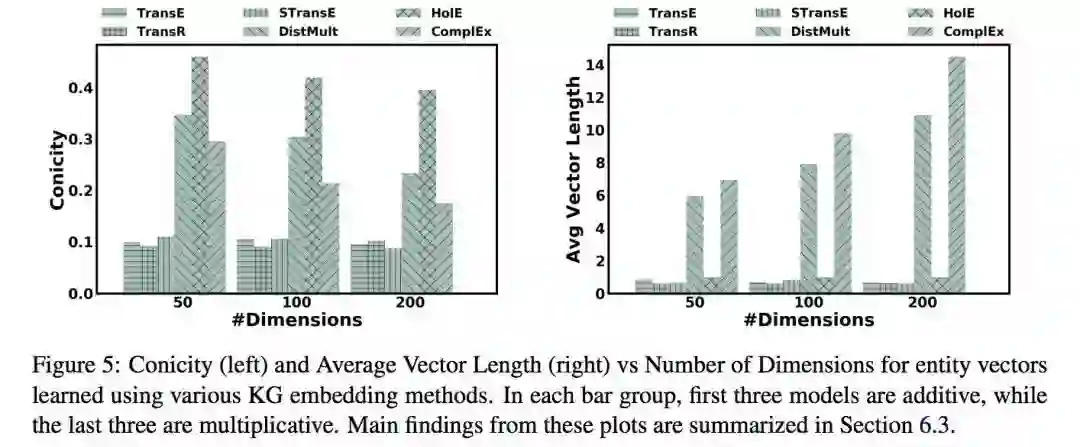
3.3 向量维数对几何形状的影响
随着向量维数的增加,乘法模型的锥度呈现出下降的趋势,而平均向量长度则呈现出上升趋势。加法模型的锥度和平均向量长度则对向量维数不敏感。
3.4 几何形状与性能的联系
本实验以链接预测任务为例,采用与 TransE 相同的实验设定。当反例数量相同时,锥度小的乘法模型的性能更优;当反例数量增加时,乘法模型表现更好。加法模型的性能与锥度并无太大关系。
在平均向量长度方面,对于除 HolE 之外的乘法模型而言,当反例数量一定时,平均向量长度越大性能越好;而对于加法模型和 HolE 而言,平均向量长度与性能的关系并不显著,这个现象是由于这些方法使用单位向量长度来限制嵌入向量所导致的。

参考文献
[1] Chandrahas, Aditya Sharma, Partha Talukdar: Towards Understanding the Geometry of Knowledge Graph Embeddings. ACL 2018: 122-131.
[2] Antoine Bordes, Nicolas Usunier, Alberto Garciaduran, Jason Weston, Oksana Yakhnenko: Translating Embeddings for Modeling Multi-relational Data. NIPS 2013: 2787-2795.
[3] Yankai Lin, Zhiyuan Liu, Maosong Sun, Yang Liu, Xuan Zhu: Learning entity and relation embeddings for knowledge graph completion. AAAI 2015: 2181-2187.
[4] Dat Quoc Nguyen, Kairit Sirts, Lizhen Qu, Mark Johnson: STransE: anovel embedding model of entities and relationships in knowledge bases.NAACL-HLT 2016: 460-466.
[5] Bishan Yang, Wentau Yih, Xiaodong He, Jianfeng Gao, Li Deng: Embedding Entities and Relations for Learning and Inference in Knowledge Bases. ICLR2015.
[6] Maximilian Nickel, Lorenzo Rosasco, Tomaso Poggio: Holographic embeddings of knowledge graphs. AAAI 2016: 1955-1961.
[7] Theo Trouillon, Johannes Welbl, Sebastian Riedel, Eric Gaussier, Guillaume Bouchard: Complex embeddings for simple link prediction. ICML 2016: 2071-2080.
IJCAI 2018


论文解读 | 谭亦鸣,东南大学博士,研究方向为知识库问答、自然语言处理
本文关注基于知识图谱嵌入(后文全部简称为知识嵌入)的实体对齐工作,针对知识嵌入训练数据有限这一情况,作者提出一种 Bootstrapping 策略,迭代标注出可能的实体对齐,生成新数据加入知识嵌入模型的训练中。
但是,当模型生产了错误的实体对齐时,这种错误将会随着迭代次数的增加而累积的越来越多。为了控制错误累积,作者设计了一种对齐样本编辑方法,对每次迭代生成的对齐数据加以约束。
1. 论文动机
目前面向知识库的实体对齐研究中,基于知识嵌入的方法取得了比传统策略更好的实验效果。但是对于知识嵌入的实体对齐,仍然存在着一些挑战。
其一:虽然近年单知识库知识嵌入研究成果颇丰,但面向知识对齐的嵌入工作仍有很多待研究的空间。
其二:基于知识嵌入的实体对齐往往依赖已有对齐作为训练数据,虽然有研究表示仅需少量对齐样本即可完成模型训练 [Chen et al. 2017],但有限的训练数据依然会影响知识嵌入的质量以及实体对齐准确性。
2. 方法
对齐引导的知识嵌入
作者将实体对齐视为分类问题,目标就是从基于知识嵌入的实体表示中(包括有标注对齐实体,及无标注实体),找到最有可能的实体对齐(最大对齐似然)。
对于知识嵌入,在 translation-based 的基础上,针对对齐问题,作者对目标函数做出如下改进:
由基本知识嵌入目标函数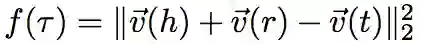
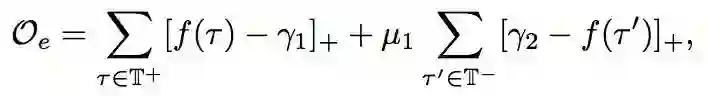
其中 [f(x)]+表示 max(f(x), 0),γ1, γ2>0 是两个超参,μ1 是个平衡参数,这里使用的负例通过随机替换正例中的部分得到。
Bootstrpping实体对齐方法
本方法的目的是最大化对齐似然,并符合 1 对 1 的对齐约束,在这种设定下,对于一组实体对齐 (x, y),y 被视为是 x 的标签(我个人是这样理解的)。故该问题建模为以下形式:
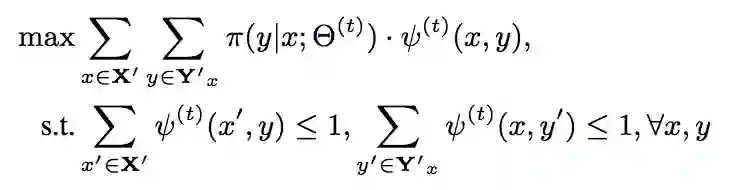
其中表示第 t 次迭代得到的实体嵌入,Y’ 表示对于 x 存在的候选对齐样本集合。
是一个标记函数,当 (x, y) 构成一组对齐的时候其函数值为 1,否则为 0。当得到新的对齐实体时,将其作为增量添加到训练集中用于下一次迭代。
考虑到新生成的对齐样本可能引起矛盾,这里作者使用的策略是对比出现矛盾的对齐实体,取对齐似然更高的样本保留,计算形式为:
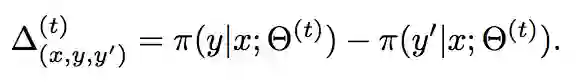
结果大于 0 时保留 (x, y) ,反之选择 (x, y’ )。
利用全局信息
这里的全局信息指全部实体样本存在对齐(有标注)的概率分布情况,作者将其定义为以下表示:
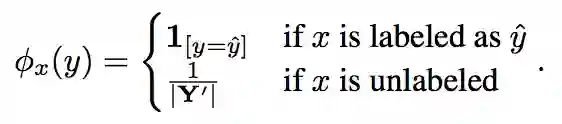
以此为基础,作者构建了一个负对数似然函数,用于强化原始样本中对齐实体对知识嵌入的优化。
添加全局信息函数后,整体目标函数扩充为以下形式:
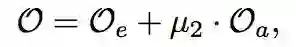
3. 实验
作者列出了自己的实验配置,并开源代码供读者研究使用。

数据方面使用 DBP15K 和 DWY100K 两个数据集。

最后,综合实验结果看来,这确实是目前最好的对齐模型。






