如何用人工智能帮你找论文?

本文转自微信公众号:芝兰玉树
作者 | 王树义
传统的关键词检索论文,浩如烟海的结果让你无所适从?试试人工智能检索引擎。根据你的研究兴趣和偏好,便捷而靠谱帮你找论文。
▌烦恼
进入一个新领域,读论文是必然途径。
读者一般会遇到2个问题:
如何获取论文全文;
如何筛选该读哪些论文。
在信息匮乏时代,第一个问题就会难倒许多人。
好在近年来,人们有了获取全文的更多渠道。
例如在物理、数学和计算机科学等领域,绝大多数新研究成果,都会首先发在arXiv这个预印本平台上。

解释一下,预印本是指你的论文写好,可以先发上来,然后再投给会议或者期刊。
在同行评议过程完成之前(这个时间段长短不一,真的有按年计算的),别人可以抢鲜读到你的工作成果,同时你上传预印本的行为也申明了自己的知识产权。
这样一来,人们就更关注第二个问题了:如何找到自己需要的论文?
这个问题越来越难以解决。
因为论文太多了。
发展较快的领域,尤其如此。
例如人工智能领域,自从深度学习(Deep Learning)成为了显学,大批量的研究者就涌了进来。一时间好不热闹。
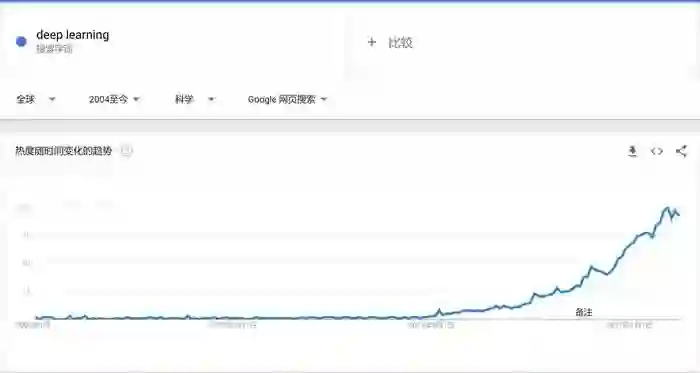
这么多的论文里,你该读哪些?以什么顺序来阅读?
要圆满解决这些问题,你可能需要拥有一张完整的领域知识地图。
可惜,人类的阅读速度,都跟不上新论文的发表速度了。几乎没有哪个人能拥有这张知识地图(而且还恰好愿意为你提供咨询服务)。
这给初学者造成了非常严重的困扰。
有人会告诉你:多读。
读到你不再是初学者,就好了。
这个建议放在今天,恐怕还是要被信息的洪流淹没。
正如庄子说的那样:
吾生也有涯,而知也无涯。以有涯随无涯,殆已!
幸好,恰恰是人工智能技术的发展,使得人们有了更加强大的武器,来应对海量论文奔涌而来的困局。
本文为你介绍一款基于人工智能的arXiv论文检索与推荐引擎,来帮助你处理论文查找和筛选问题。
▌检索
我为你推荐的这个论文检索引擎,叫做arXiv-sanity。
这是首页的样子。
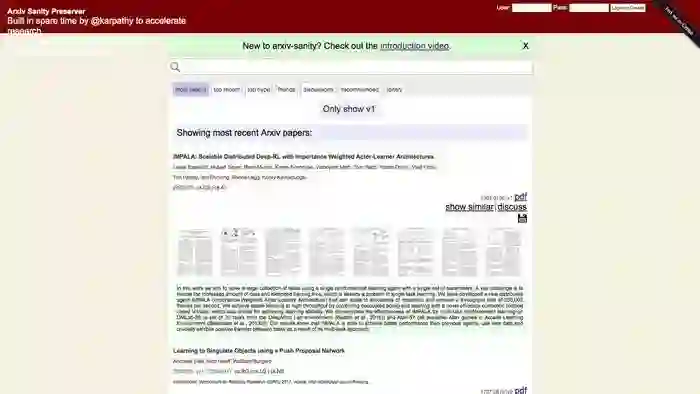
第一次使用的时候,建议你点击这个链接(https://youtu.be/S2GY3gh6qC8)查看介绍视频。
为了使用这个检索引擎,你需要创建一个账户。
别怕麻烦,10几秒钟就能完成。只是你需要把密码记录下来,以免下次忘记。
这是我账户创建完毕的样子。

我们来对比一下,arXiv和arXiv-sanity中,依据关键词检索论文的结果有什么差异。
在arXiv里面,搜索“keras”,结果是这个样子的。

看着中规中矩,对吧?
而在arXiv-sanity中搜索同样的关键词,结果是这样的:
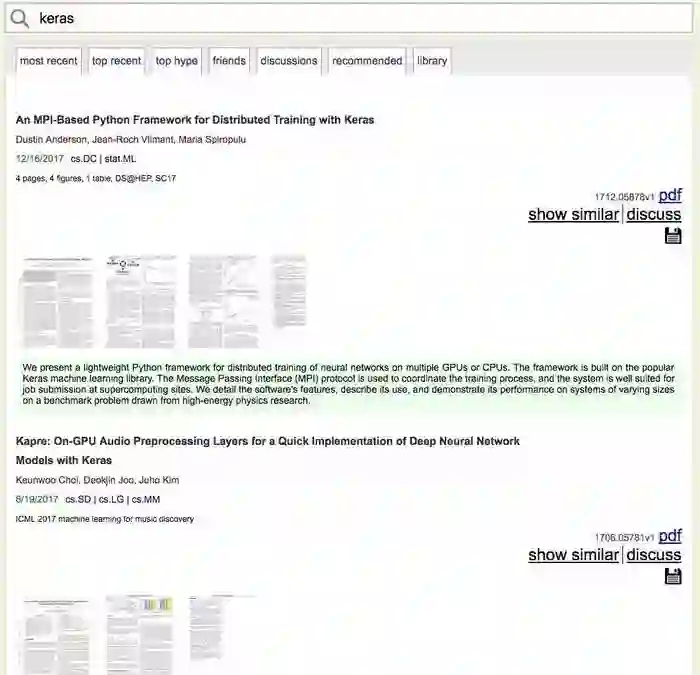
arXiv-sanity的搜索结果以更加可视化的形式呈现。你不仅可以看到标题、作者等信息,而且还可以直观看到其中正文的预览图。
这样一来,一眼扫过去,你就可以观其大略,发现某篇论文是否符合你的口味。
我的研究生应该会比较喜欢这个功能。这样他们寻找候选翻译论文的时候,就能尽量避开公式太多的了。
基于关键词的检索是最为基本的功能。
我们来看看其他服务。
▌群体
一篇论文写得如何?其他用户可能会有评论。
点击“Discussions”按钮,你就能查看评论,从而了解他人眼里,论文的优点与不足了。
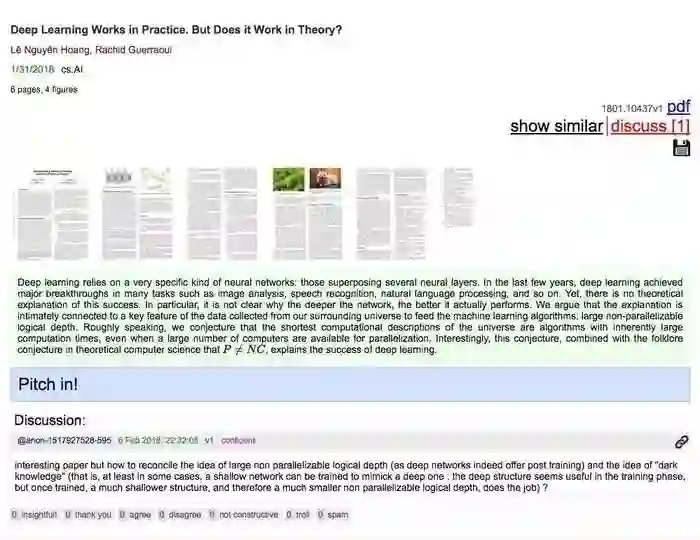
如果你暂时还没有确立自己的研究方向与兴趣,也没有关系。
这套论文检索系统充分利用了人类用户的群体智慧(crowd wisdom),即观察和分析他人的行为,来帮你找到可能感兴趣的论文。
尝试一下,点击屏幕上方的“top recent”按钮。
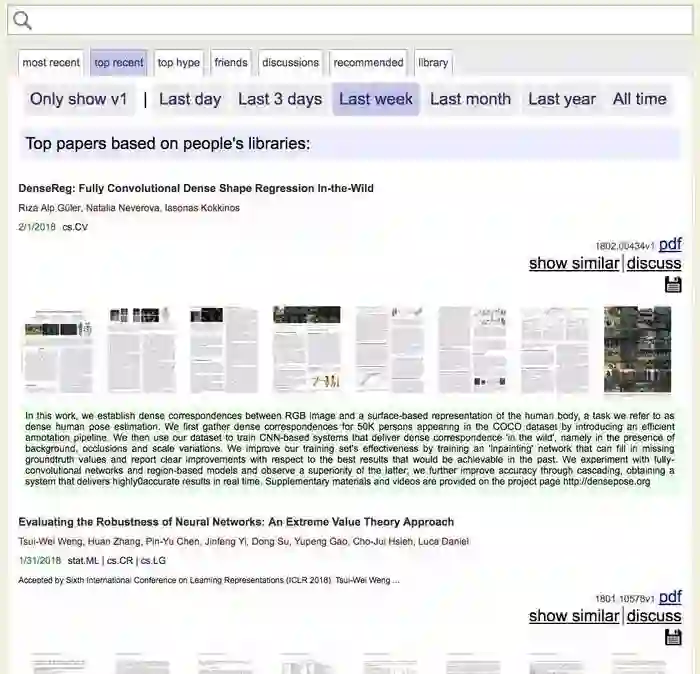
系统会根据他人在文献库收藏的情况,为你推荐一周内最受欢迎的论文。
当然你也可以自己选择时间尺度。我们来尝试一下“All Time”(全部时间段)。
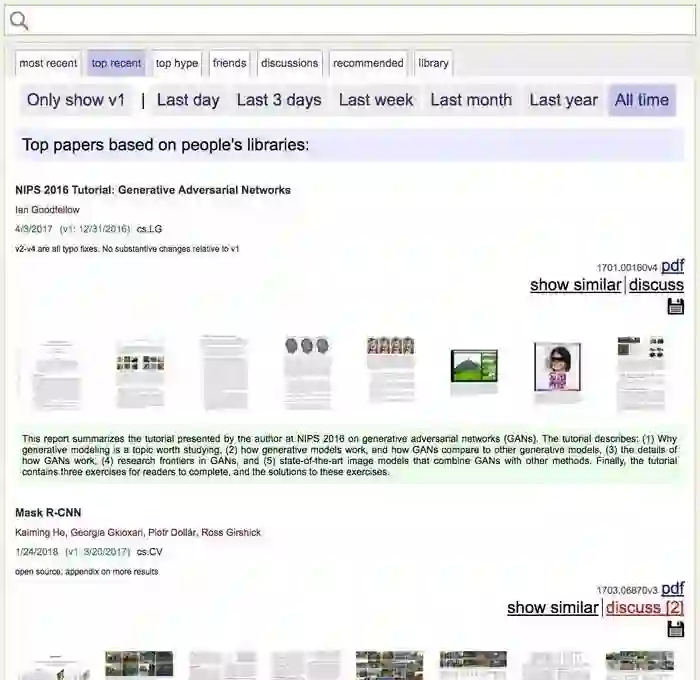
深度学习领域大牛Ian Goodfellow的论文NIPS 2016 Tutorial(发表于2017年)排在第一位。
但是使用这个检索系统的人毕竟还有限。少数人的关注,可能不足以说明问题。
没关系,这个系统还和社交媒体平台Twitter链接了起来。
点击屏幕上方的“top hype”按钮,你会看到以下界面。
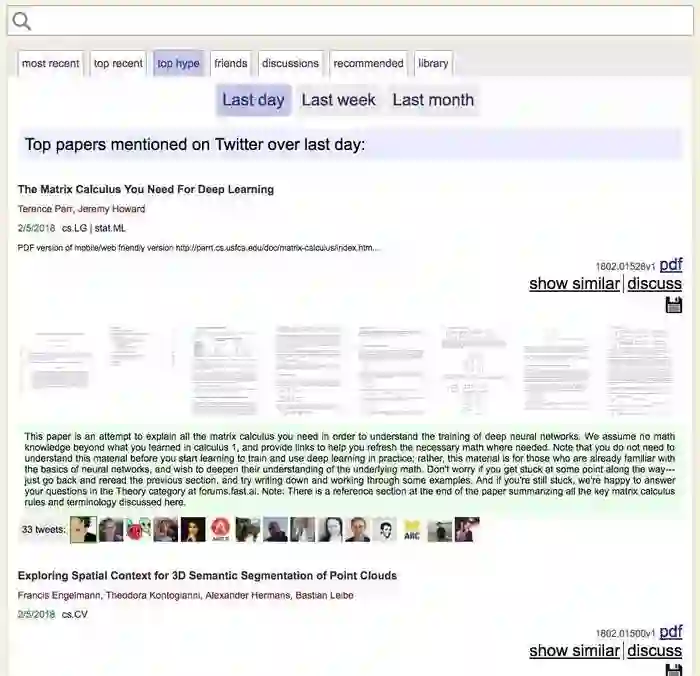
你可以试试把鼠标滑动到某个Twitter用户头像上,直接看TA说了什么。

当然,社交媒体平台上的数据,也并非完全相关与可靠。但是对于科研内容的评价和传播来说,社交媒体数据(评论、转发等)还是比较有参考价值的。
毕竟,愿意研究论文的人,大致上还是有一定的学术基础,并且比较珍视自己的名誉,因此胡乱评价的概率较低。
将检索平台自身的收藏数量和社交媒体推荐相互印证,你就不难找到一些引领趋势的研究成果。
可是,这些成果虽然代表了流行程度和受关注度,却未必符合你的胃口。
这就该人工智能上场了。
▌智能
你可以通过文章内容的相似性寻找符合口味的论文。
回到我们刚刚检索“Keras”的第一个结果下,点击“show similar”,就能看见以下分析结果。
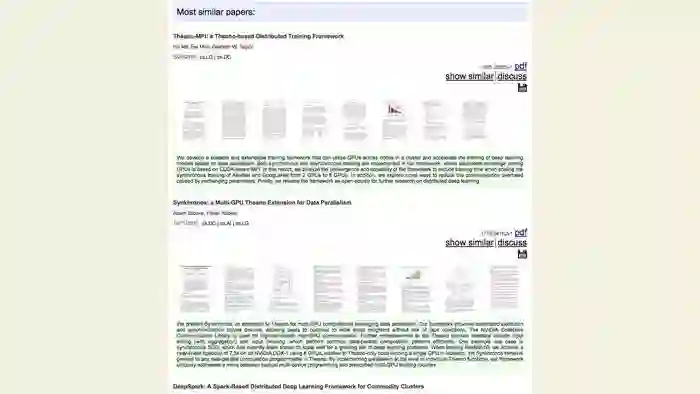
系统通过自然语言处理后,认为与该研究相关的文章都被列出来了。
我们检索的Keras是一种深度学习框架,结果标题中出现Theano也是。看来机器帮我们找的相似性还是比较靠谱的。
比起人工推荐同类研究论文,arXiv-sanity这样的计算机系统可以不知疲倦地随时监测,实时发现新的结果,并且及时通知用户。
这样一来,你做文献综述的时候,心里就会更有底了。
我们来看看更智能的应用——论文推荐。
如果说相似结果查找还不过是照猫画虎,论文推荐可就是见微知著了。
在检索结果中,咱们选择一些感兴趣的论文,将它们存入到自己的独立文献库(Library)中。点击那个软盘模样的存盘按钮就可以。

被收藏的文章,存盘按钮变成了蓝色。
进到我们的文献库里看看。
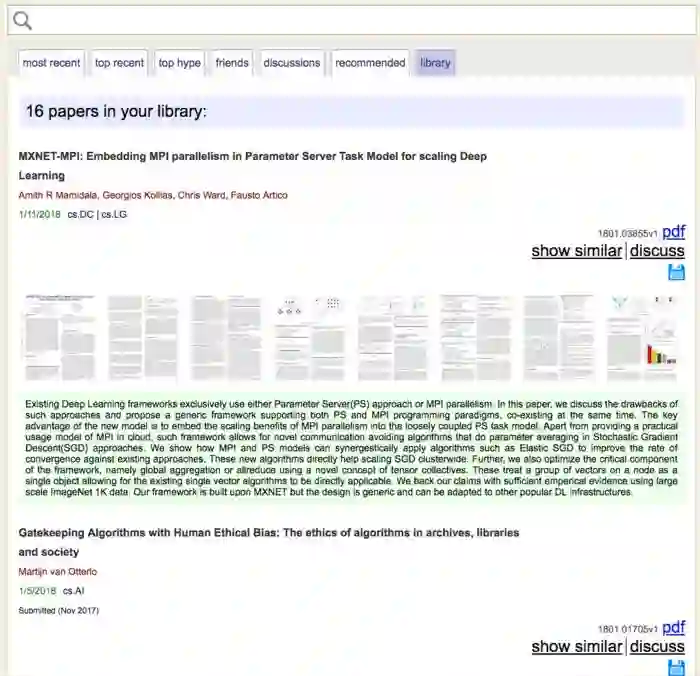
你的检索、阅读和保存等动作都在给arXiv-sanity系统传递信号。
依据这些信息,以及其他用户的使用习惯和偏好数据,平台就可以分析你的研究兴趣,并且可以推荐文章给你了。
推荐的论文,也可以选择时间范围。这样不管你是希望找到经典文献,还是“喜新厌旧”,都可以各取所需。
推荐结果的准确度,与你传递给平台的信息,以及其他用户的行为数据积累,都是相关的。一般来说,你用得越多,文献库中积累的论文越多,推荐结果就会越精准。
▌限制
尝试一段时间后,你可能注意到了,arXiv的首页上,左上角有些白色文字。
因为底色原因,可能看不太清楚,这里我给你清晰列出:
Serving last 41211 papers from cs.[CV|CL|LG|AI|NE]/stat.ML
后面那些奇怪的代码,是什么意思呢?
它们其实是arXiv这个预印本平台上的论文分类编号。
具体来说,它们的含义如下:
cs.CV: Computer Vision and Pattern Recognition 计算机视觉与模式识别;
cs.CL:Computation and Language 计算语言学;
cs.LG:Learning 机器学习(计算机科学);
cs.AI:Artificial Intelligence 人工智能;
cs.NE:Neural and Evolutionary Computing 神经与演化计算;
stat.ML:Machine Learning 机器学习(统计学)。
这样,你大体就能了解arXiv-sanity平台上包含的论文类别了。
本文写作时,该平台检索论文的范围为41211篇。
你可能对这里论文的数量嗤之以鼻——也太少了吧!
确实不多。
但是近年来相关论文数量增长趋势明显。
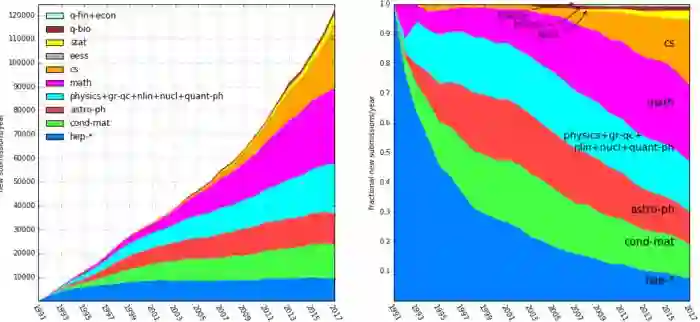
目前人工智能领域的最优秀作者,论文写作后首发平台都是arXiv。这样一来,arXiv-sanity便可以立即检索到这篇文章。
如果你研究相关领域,可以在有鱼的地方钓鱼,不轻易放过好文献。
但这些智慧功能,仅能局限在arXiv人工智能领域文章推荐吗?
不是。
点击首页右上角的“Fork me on Github”按钮,你可以看到arXiv-sanity的Github源代码。
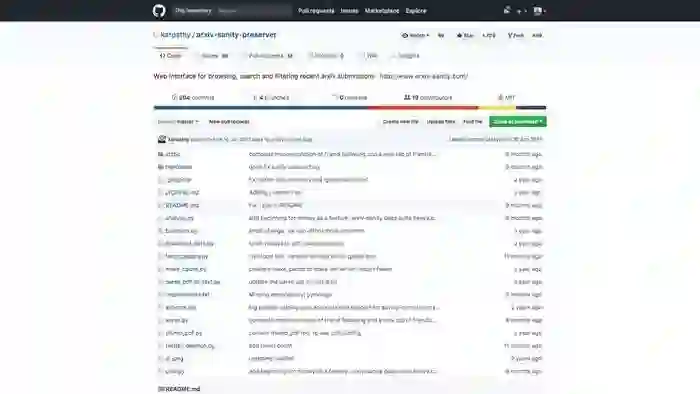
作者Andrej Karpathy说得非常清楚:

你可以用他提供的源码,对任意的arXiv文章子集进行智能化检索服务。
你可以把服务搭建在自己的电脑上,也可以部署在亚马逊AWS这样的云平台上面。
回过头去,看看arXiv论文都包含哪些学科,我知道你一定很不满足。

你的专业,有可能不在arXiv涵盖的范围内。
这样的论文能不能用arXiv-sanity的服务呢?
很遗憾。答案在目前还是否定的。
因为arXiv-sanity的智能,是建立在全文可获取的前提下的。
可是,目前世界上很多的论文版权,还牢牢地掌握在几大出版商手中。
下载论文全文并用来提供公众服务,是挑战他们底线的行为,往往会遭到严厉的打击。
天才少年Aaron Swartz的人生悲剧,就是这样酿成的。

但是至少,我们看到了一种未来发展的可能性。
▌英雄
作为附加内容,我给你介绍一下:我是怎么发现arXiv-sanity这个好用的论文检索服务的。
毕竟授人以鱼,不如授人以渔嘛。
原因很简单,我看到资料介绍,说它的创建者是Andrej Karpathy。

我立即确认,这个检索工具一定很靠谱。
因为Andrej Karpathy是个深度学习领域的达人。
Andrew Ng的课程中,有过对他的专访,放在了“深度学习英雄”(Heroes of Deep Learning)系列中。
你可以点击这个链接(http://sina.lt/fn96)查看这段访谈。
在我自己的课程中,也曾经介绍过他开发的char-rnn模型(https://github.com/karpathy/char-rnn)。
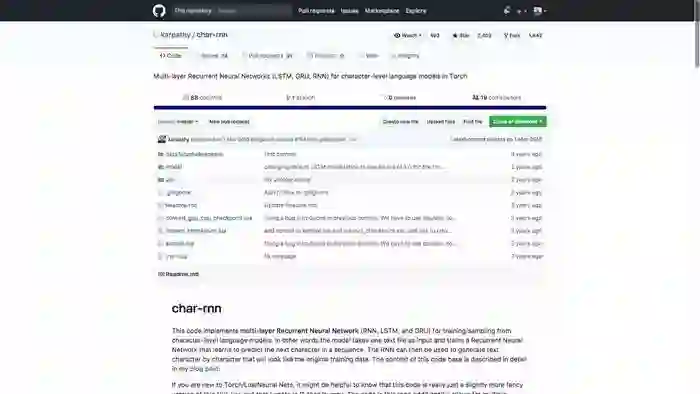
这个模型能干什么呢?
很多。
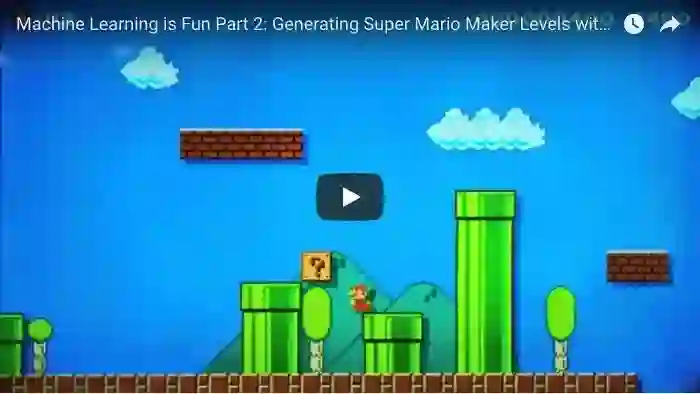
其中之一是,制作游戏关卡,哄人类玩家玩儿。
在学习了《超级马里奥兄弟》的32个关卡后,机器自动生成了下面这个场景构建:

玩儿起来的效果如何?你可以点击这段视频的链接(https://youtu.be/_-Gc6diodcY),自己评判一番。
正因为Andrej Karpathy这种超强技术实力,和长期不断的内容输出,人们对他开发的论文智能检索系统,才会有如此高的信任度。
▌讨论
你之前是如何检索文献的?使用过哪些好工具?有没有查找自己感兴趣论文的小窍门呢?欢迎留言,把你的经验和思考分享给大家,我们一起交流讨论。
如果你对我的文章感兴趣,欢迎点赞,并且微信关注和置顶我的公众号“玉树芝兰”(nkwangshuyi)。
如果本文可能对你身边的亲友有帮助,也欢迎你把本文通过微博或朋友圈分享给他们。让他们一起参与到我们的讨论中来。
新一年,AI科技大本营的目标更加明确,有更多的想法需要落地,不过目前对于营长来说是“现实跟不上灵魂的脚步”,因为缺人~~
所以,AI科技大本营要壮大队伍了,现招聘AI记者和资深编译,有意者请将简历投至:gulei@csdn.net,期待你的加入!
如果你暂时不能加入营长的队伍,也欢迎与营长分享你的精彩文章,投稿邮箱:suiling@csdn.net
AI科技大本营读者群(计算机视觉、NLP、Python、AI+金融方向)正在招募中,后台回复:读者群,联系营长,添加营长请备注姓名,研究方向。



☟☟☟点击 | 阅读原文 | 查看更多精彩内容




