用机器学习预测混沌,未来的天气预报可能更准确
编者按:南美洲亚马逊河流域热带雨林中的蝴蝶,偶尔扇动几下翅膀,可以在两周以后引起美国得克萨斯州的一场龙卷风。这是有关“混沌”的最经典案例。环顾四周,我们的生存空间充满了混沌。那么,混沌究竟可否被预测呢?在如今的计算实验中,人工智能算法可以预测混沌系统的未来。

半个世纪前,混沌理论的先行者们发现了“蝴蝶效应”,让长期预测变得可能。即使对复杂系统进行微小的干扰,也会触发一系列变化,引起未来的巨变。由于无法精确地预测这些系统的状态以及它们的趋势,我们通常认为生活的世界是不确定的。
但现在,机器人可以试着解决这一问题。
据报道,目前科学家们已经可以用机器学习预测混沌系统的未来趋势,其他专家赞赏这种方式是非常具有突破性的,可以应用到更广的范围。
德国不来梅雅各布大学计算机科学教授Herbert Jaeger表示:“对于机器学习可预测的混沌未来,我非常震惊”。
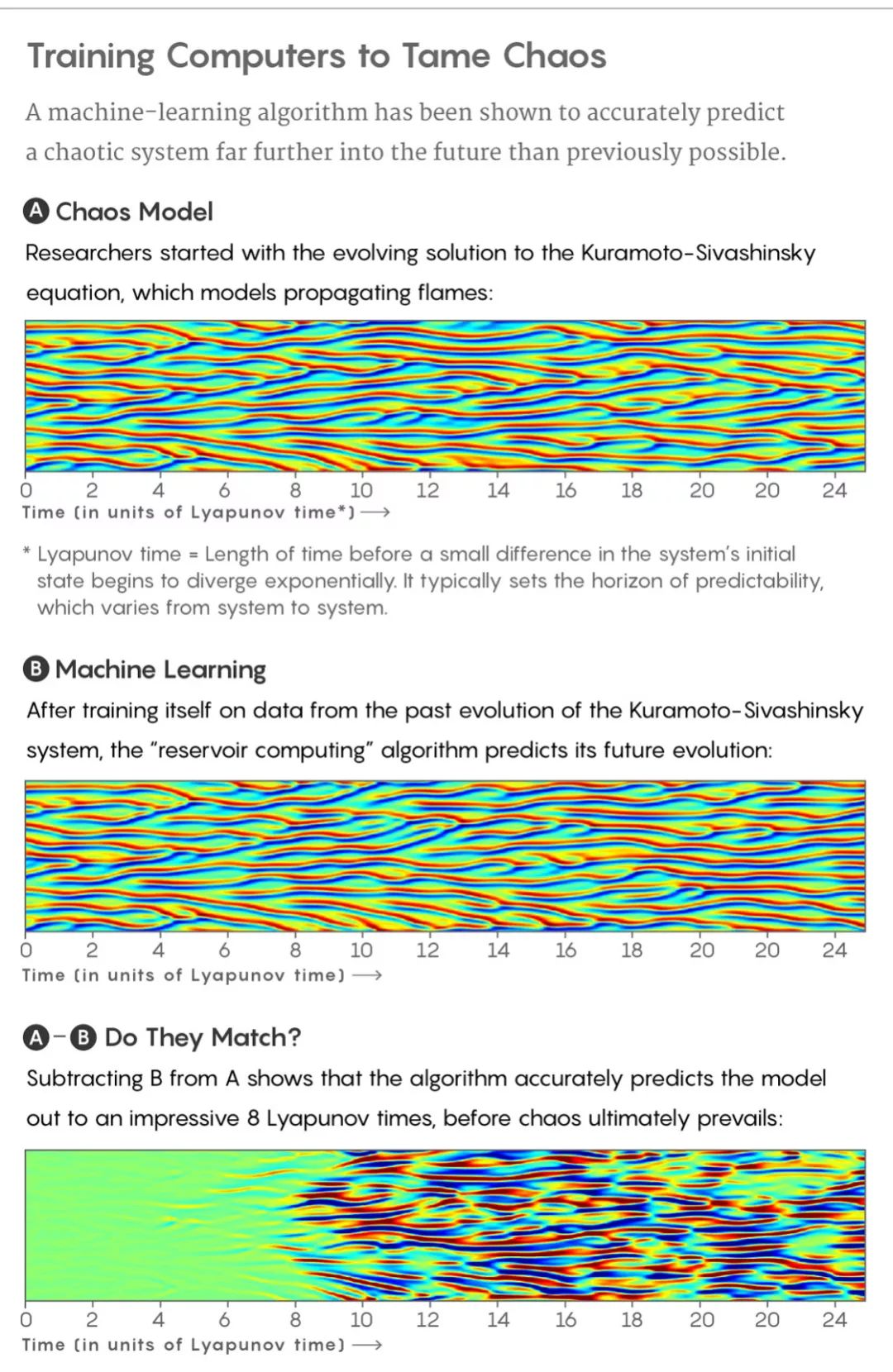
这项研究成果来自老牌混沌理论学家Edward Ott和四位来自马里兰大学的合著者。他们采用了一项名为reservoir computing的机器学习算法来“学习”名为Kuramoto-Sivashinsky等式的原型混沌系统的动力学(dynamics)。该等式的演变过程就像一个“火焰锋面(flame front)”,在可燃物中燃烧前进。这个等式还描述了等离子体中的漂移波和其他现象,并且成为“研究湍流和时空混沌的测试平台”,Ott的研究生、论文的主要作者Jaideep Pathak说。
用Kuramoto-Sivashinsky等式之前的数据对系统进行训练后,研究者们的reservoir computer就可以大致预测出火焰般的系统在八个“李雅普诺夫时间”后的状态。“李雅普诺夫时间”表示混沌系统中两个几乎相同的状态呈指数开始发散所需的时间。因此,它通常都设置了可预测性的范围。
马克思普朗克研究所的混沌理论学家Holger Kantz表示:“这非常不错,机器学习技术几乎可以预测未来的真相了。”
其实,算法本身根本不懂Kuramoto-Sivashinsky等式,它只能看到记录的数据。在很多情况下,这使得机器学习变得强大,描述混沌系统的方程是未知的,很难让动态学家对它们进行建模和预测。Ott和团队的成果则解决了这一问题,无需方程,只要有数据就足够了。“这篇论文告诉我们,未来有一天,我们也许可以用机器学习算法预测天气,而不依靠复杂的大气模型,”Kantz说道。
除了天气预报,专家表示机器学习技术还可以帮助监测心律失常,以预测可能发作的心脏病,或者监测大脑中神经元出现的异常放电,可能暗示癫痫的发作。更重要的是,它也可以帮助预测“疯狗浪(rogue wave)”,这种巨浪轻则威胁船只及人身安全,重则引起地震。
Ott非常希望这一新工具能提前预测太阳风暴,1859年9月1日和2日发生了有史以来最大的太阳风暴,它跨越太阳表面35000英里,全球各地都看见了极光,许多地区的通信系统遭到破坏,产生的电压也使供电系统瘫痪。如果这样强烈的太阳风暴发生在今天,它会严重损坏地球的电力设施。“如果有风暴预警,人们可以提前关闭电源,以免受到影响。”
He、Patrick和他们的同事Brian Hunt、Michelle Girvan和Zhixin Lu通过整合现有的工具取得了新成果。六七年前,当深度学习开始占领各图像、语音识别等AI任务时,他们开始研究机器学习,并思考如何将其应用到混沌上。在深度学习革命之前,他们就取得了不错的成果。最重要的是,在21世纪初,Jaeger和德国混沌理论学家Harald Haas利用随机连接的人造神经元网络学习了三个混沌共同变化变量的动力学。在对三组数字进行训练后,网络可以预测三个变量未来的值。但是,当有多个交互变量时,计算就不可用了。Ott和他的同事需要设计一个更有效的方案,使reservoir computing与大型混沌系统联系起来,这些混沌系统具有大量相关变量。例如,前进的火焰前方的每个位置都有三个不同方向的速度分量来跟踪。
研究人员花了几年的时间才找到直接的解决方案。Pathak说:“我们利用的是空间扩展的混沌系统中交互的周围区域。”这个周围区域指的是一个位置的变量会受到这位变量的影响,但二者距离并不很远。Pathak解释到:“通过使用它,我们基本上可以将问题分解开来。”也就是说,你可以同时解决两个问题,使用一个神经元储存器去学习系统的一个补丁,另一个储存器学习下一个等等。
只要计算机有一定的资源用于解决任务,就能用reservoir computing方式同时解决混沌系统中几乎任何大小的问题。
Ott向我们解释了reservoir computing的三个步骤,以预测蔓延的火焰为例。首先,你需要在火焰前方的五个点测量火焰的高度,等火焰燃烧过这个点后,再测量一下高度。然后将这些数据流输入到reservoir中随机选择的人工神经元里。输入的数据会激活神经元以及与之相连的神经元,最后通过网络输出一串数据。
第二步是让神经网络从最初输入的火焰数据中学习动力学。为了达到这一点,当你输入数据时,你同样需要控制reservoir中多个随机选择神经元的信号长度。如果将这些信号以五种不同的方式进行加权并组合,那么会产生五个数字作为输出。最终的目标是调整各信号的权重,直到让输出的结果与下一次的输入(之后测量的火焰高度)相匹配。Ott解释说:“理想情况应该是,输出与之后的输入相符。”
为了分配正确的权重,算法只是简单地将每组输出(或预测的五个点处的火焰高度)与下一组输入(或实际火焰高度)相比较。各种信号每次增加或减少的权重,保证无论以哪种方式都会输出五个正确的值。从上一个时间点到下一个时间点,随着权重的调整,对火焰的预测逐渐改进,直到算法能持续一次性预测正确火焰的状态。
“第三步,你就要做预测了,”Ott说道。存储器在学习系统的动力学后,了解了之后它会如何发展,也就是说网络会问它自己接下来会发生什么。输出的值被重新输入系统中,如此循环,预测五个点处的火焰状态。而其他存储器在此刻也在预测火焰其他地方的状态。
在他们一月份的论文中,研究人员表示,他们用Kuramoto-Sivashinsky方程预测火焰的方案与混沌最终实现的八个李雅普诺夫时间的实际情况完全符合,并且实际状态与预测状态发生分离。
预测混沌系统的常用方法是尽可能准确地测量其条件,使用这些数据校准现实模型,然后不断地更新。作为一个估计值,你必须准确测量1亿次初始条件,以预测未来八次的发展情况。
“这就是为什么机器学习是一种有用而强大的方法,”马克思普朗克学院的研究者Ulrich Parlitz说,他也像Jaeger一样,早在本世纪初就将机器学习应用到低维度的混沌系统中了。“我认为这种方法不仅适用于他们展示的例子,而且在一定程度上是通用的,可以用到很多处理过程和系统中。”在最近发表在Chaos上的一篇论文中,Parlitz和一位合著者用reservoir computing预测了“激励介质(excitable media)”的活动,例如心肌组织的活动预测。Parlitz认为更复杂、计算量更大的深度学习对这类问题能解决得更好。最近,麻省理工和瑞士联邦理工学院的研究者们利用LSTM神经网络,推出了与马里兰大学类似的成果。
Ott、Pathak、Girvan、Lu等人发表论文后,他们正努力让这一理论落地。在Chaos发表的一篇新论文中,他们证明了将数据驱动的机器学习方法和传统基于模型的预测混合,可以改进混沌系统(如Kuramoto-Sivashinsky方程)。Ott认为这是改进天气预报等预测性工作更可行的途径,因为我们并不总能拥有完整地高分辨率数据或完美的模型。“我们应该做的就是用好现有的知识,”他说,“如果我们有无知的地方,那就应该用机器学习填补空白。”
不同的系统李雅普诺夫时间的长短也不通,从毫秒到数百万年不等。时间越短,系统就越接近蝴蝶效应,相似状态分离地越快。在自然界中,混沌系统无处不在,它们有时更加混乱,有的变化得较慢。但奇怪的是,混沌本身很难确定。芝加哥大学的数学教授Amie Wilkinson说:“大多数动力学系统中的研究者都会用到这个术语,但他们在实际使用时却避免出现混沌。用混乱(chaotic)表示某物听起来有点儿俗气,因为它很吸引人的注意力,但是完全没有明确的数学定义和概念”对于这一点,Kantz也同意:“没有一个简单的概念定义它。”在某些情况下,调整系统中的单个参数能使其从混沌状态变为稳定状态,反之亦然。
Wilkinson和Kantz都用延伸和折叠定义了混沌。就像做泡芙时反复拉伸和折叠面团一样,每块面团在擀面杖的作用下水平伸展,向空间上的两个方向呈指数分离。然后折叠面团再压平,垂直向下压面团。Kantz说,天气、野火、太阳风暴和所有混沌系统都是这样的。“为了得到这种呈指数发散的轨迹,你需要拉伸,为了不达到无穷大,你需要折叠,”折叠来自系统变量中的非线性关系。
不同维度中的拉伸和压缩分别对应系统中正负李雅普诺夫指数。在Chaos的另一篇论文中,马里兰大学团队表示,他们的reservoir computer能成功地从数据中学习特征指数的值。究竟为什么reservoir computing能如此擅长处理混沌系统,目前尚未有明确的解释,只是因为计算机能自动调节数据对应的公式,直到这些公式符合系统的动态。事实上,这项技术表现得较好,Ott和马里兰大学其他的研究人员正计划用混沌理论更好地理解神经网络的内部机制。
原文地址:www.quantamagazine.org/machine-learnings-amazing-ability-to-predict-chaos-20180418/




