ICCV 2019 开源论文 | 少量目标域样本下的图像翻译模型

作者丨薛洁婷
学校丨北京交通大学硕士生
研究方向丨图像翻译


概要
模型架构
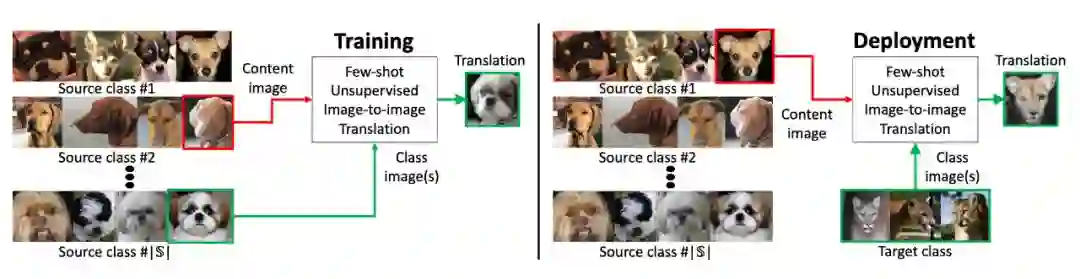
内容编码器的目的是将原域图像编码成内容向量
类别编码器是将 K 个原域图像映射至类别向量
解码器结合内容向量和类别向量生成出目标域图像(使用了 AdaIN)
损失函数

2. 重建损失,通过给生成器输入同一张图像的和
来限制生成器,鼓励其输出与输入完全一致的图像:
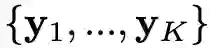 中提取的特征的均值之间的 L1 损失最小,这样做的原因是因为这里训练模型时都采用的是相似域内的图像,其特征也应该保持相似:
中提取的特征的均值之间的 L1 损失最小,这样做的原因是因为这里训练模型时都采用的是相似域内的图像,其特征也应该保持相似:

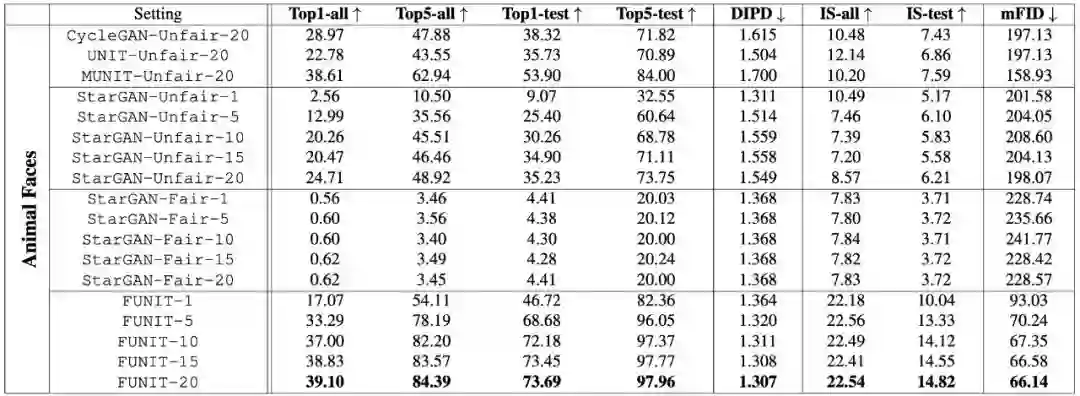
实验结果

总结
参考文献
[1].J.-Y. Zhu, T. Park, P. Isola, and A. A. Efros. Unpaired image-to-image translation using cycle-consistent adversarial networks. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), 2017. 1, 2, 3, 4, 5, 8
[2].Y. Choi, M. Choi, M. Kim, J.-W. Ha, S. Kim, and J. Choo. StarGAN: Unifified generative adversarial networks for multi-domain image-to-image translation. arXiv preprint, 1711, 2017.

点击以下标题查看更多往期内容:

让你的论文被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学习心得或技术干货。我们的目的只有一个,让知识真正流动起来。
📝 来稿标准:
• 稿件确系个人原创作品,来稿需注明作者个人信息(姓名+学校/工作单位+学历/职位+研究方向)
• 如果文章并非首发,请在投稿时提醒并附上所有已发布链接
• PaperWeekly 默认每篇文章都是首发,均会添加“原创”标志
📬 投稿邮箱:
• 投稿邮箱:hr@paperweekly.site
• 所有文章配图,请单独在附件中发送
• 请留下即时联系方式(微信或手机),以便我们在编辑发布时和作者沟通
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
关于PaperWeekly
PaperWeekly 是一个推荐、解读、讨论、报道人工智能前沿论文成果的学术平台。如果你研究或从事 AI 领域,欢迎在公众号后台点击「交流群」,小助手将把你带入 PaperWeekly 的交流群里。

▽ 点击 | 阅读原文 | 下载论文 & 源码

