取代人类医生?AI给你做的诊断你敢信吗

翻译 | ziqi zhang
编辑 | Donna,波波
Luke Oakden-Rayner 是澳大利亚知名学府阿德莱德大学的在读医学博士生、放射线学专家,曾发表过多篇医疗人工智能方面的论文。他在顶级杂志《Nature》上发表的一项研究成果显示,其团队开创性地研发出可以预测人类寿命的仪器。他一直在追逐医疗AI领域的发展,从今年5月份开始,他写了一系列的博客来介绍这一领域的最新研究进展,目前更新到了第三篇,其系列博客的名字就叫《人类医学的终结 - 医学AI研究最前沿》(The End of Human Doctors – The Bleeding Edge of Medical AI Research)。今天给大家介绍第一部分,希望你可以从中领会到人工智能对医疗领域的影响。
接下来几天,我们会陆续放出同系列另外两篇。欢迎继续关注人工智能和医疗这个热点话题。
今天的话题:机器学习最终是否会代替人类医生?
我们要探讨的这篇论文,它采取的方法,绝对可以比以往任何一种方法都好。本来我想在一篇博客里讨论好几篇类似的论文,可惜每一篇论文都有很多值得人们深思的地方(这篇文章就已经占了3000字了),所以每一篇论文我将花整个篇幅去深度探讨和理解。然后我将在几周里分开讨论这些文章,于是就产生了我博客中关于医疗人工智能这个系列专题。
对于本次话题,我非常感谢 Lily Peng博士,这篇论文的作者之一,他对我提出的许多问题做出了非常充分的解答。
这里先奉上一份简单的总结:
TL:DR
google(和他们的合作者)训练了一个系统,可以检测糖尿病视网膜病变(全世界5%的失明由它引起),该系统能够像一个眼科医生一样做出诊断。
这是一个有用的临床任务,它可能不会节省很多的费用,也不会在医疗自动化以后取代医生,但是它的提出有很大的人文情怀。
他们使用了13万个视网膜图像进行训练,比公开的数据集大了1到2个数量级。
他们使用阳性案例丰富了他们的训练集,在某些程度上抵消了不平衡的数据分布带来的影响。
由于大多数深度学习模型都是针对低分辨率的图像,所以原数据被下采样处理,丢弃了90%以上的像素值,然而我们无法评测这样做是否有利。
他们雇佣了一组眼科医生来对图像进行标注,可能会花费数百万美元,这样做的目的是为了使标注更准确,避免出现误判。
第5点和第6点是造成当前所有深度学习系统错误率高的原因,而且这个问题很少被谈及。
深度学习之所以比医生更有优势,是因为它们可以在各个“操作点”上运作,相同的系统可以执行高灵敏度筛选和高特异性诊断,不需要再加额外的训练。
这是一个很棒的研究内容,人们能够很容易的理解,并且在文本和补充中有很多有用的信息。
这项研究似乎符合目前FDA对510(k)批准的要求。虽然这项技术不太可能通过,但是该系统或衍生物在未来的一两年内很可能加入到临床的实践当中去。
免责声明:本文主要针对大众化的群体,包括机器学习领域的专家、医生等。相关专家们可能会觉得,我对一些概念的理解很肤浅,可是我还是希望他们能在自己研究领域之外找到更多有趣的新想法。还有一点要强调的是,如果这篇文章里有任何说错的地方,请读者告诉我,我会及时改正。
在讨论之前,我想提醒大家,虽然从2012年开始,深度学习就逐渐发展成一种研究者经常使用的方法,但是五年之内我们并没有在医学中使用这种方法,为了安全起见,我们的医疗人员也通常比技术的发展落后一步。大家了解到这个背景以后,就可以想象到现在取得的一些成果更是令人难以置信,而且我们应该客观地认识到,人工智能对医疗的发展只是一个开始。
在论文中提出了,医疗自动化已经实现了突破性的进展,我会在本文中简单回顾一下,也适当地增加了一些有用的知识。我会进一步介绍这个研究,在介绍之前先花几分钟时间说明几个关键性的问题:
任务——这项任务是临床任务吗?如果实现自动化,在医疗实践过程中会面临多大的干扰呢?为什么选择这项特定的任务呢?
数据——如何收集和处理需要的数据?数据怎么处理才能符合医学实验和监管的要求呢?我们需要深入了解医疗人工智能对大数据的要求。
结果——人工智能将战胜医生还是打成平手?他们究竟测试了什么?我们还能有什么其他的收获吗?
结论——这个结果有多大的影响力?我们还可以进一步得到其他的结论吗?
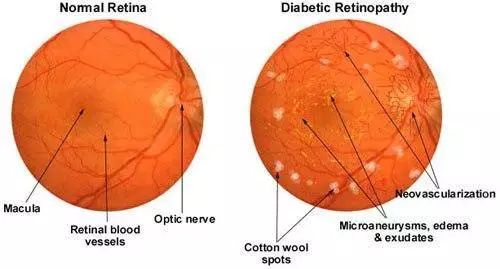
糖尿病视网膜病是造成失明的一个重要病变,其成因是由于眼睛后部的细小血管损伤的造成的。医生可以通过观察眼睛后部的血管进行诊断,这其实是一项感知任务。
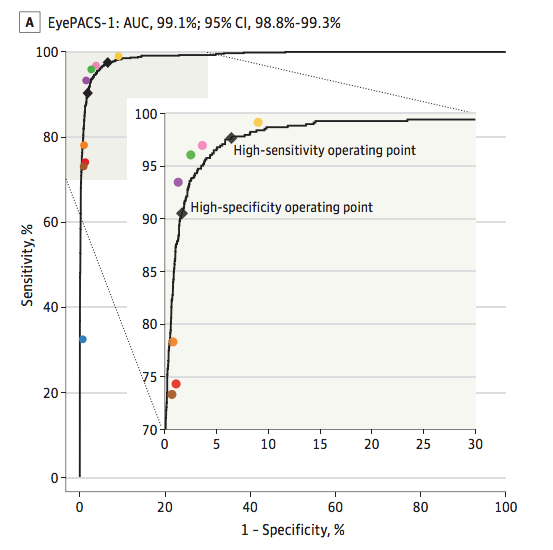
图二 这是所谓的ROC曲线,是判断疾病诊断系统的最佳方式之一。 通过计算曲线AUC下方的面积,能够将灵敏度和特异度结合在单一的指标中。99.1%是非常好的。
费用:他们雇用了一组眼科医生来标注他们的数据,一共有50万个标签需要去标注。如果按照正常的看病价格去支付医生,大概需要数百万美元。这笔费用比大多数创业公司的成本还要多,而且他们肯定无法接受只有一个单一数据集的标注任务。 从统计的角度考虑,数据就是力量。对于医疗人工智能来说,只有金钱才能产生这么多数据。换句话说,金钱就是力量。
任务:他们能够从眼睛的照片中检测到两类以上的“可视眼病”(中度或者重度视网膜病变),甚至更严重的视网膜病变和黄斑水肿。这些都是临床上非常重要的任务。最重要的是,这些任务涵盖了大多数医生在看糖尿病患者眼睛时在做的工作。当然,这个系统检测不出罕见的视网膜黑色素瘤,但是对于日常的眼睛检查,这是一个可以很好模拟医生的系统。
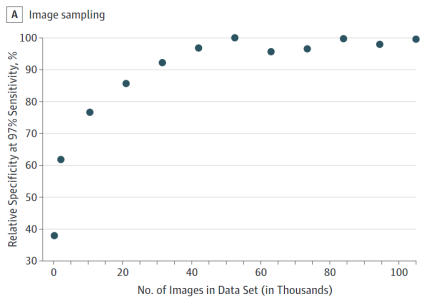
图三 数据集中图像的数量(单位:千)
另外,我还注意到“中度或者重度”疾病的训练数据是普通的3到4倍。绝对数据较少(约9500例vs 34000例),而且关于流行眼病的数据也较少(9%为阳性,30%为阳性)。
但是,这种扩增较少的数据类型的方法只有在有更多的阳性案例情况下才有效,这种情况并不常发生。现在已经有了一些解决不平衡数据的方法,但是仍然没有找到一个解决不平衡数据的最佳方式。
深度学习能对高分辨率图像有更好的训练效果吗? 低分辨率的图像是否适用于所有的医疗任务呢? 从技术的角度来看,我们是否可以在深度学习中采用高分辨率图像呢?
这些系统和医生相比有一个主要的优势:人类医生在假设的ROC曲线上有一个单一的操作点,这是基于他们经验的灵敏度和特异性的平衡,并且很难用任何可预测到的方式去改变。相比之下,深度学习系统可以在ROC曲线的任何地方运行,不需要再加额外的训练。你可以在诊断模式和筛选模式之间进行切换,而且不需要额外的费用,这种灵活性真的太酷了!在实际的临床测试中非常有用。
如果这个用人工智能进行眼部病变筛检的技术能得到推广,那么它人类的影响会非常大。在许多发展中国家,糖尿病病情日益严重,但是眼科专家奇缺。鉴于图像处理在低分辨率的图片上上成功率跟高,如果能将该系统与低成本且易于使用的手持式视网膜摄像机结合起来,可以挽救数百万人的生命。
作者:Luke Oakden-Rayner
原文链接:
https://lukeoakdenrayner.wordpress.com/2017/05/24/the-end-of-human-doctors-the-bleeding-edge-of-medical-ai-research-part-1/
热文精选
重磅 | 2017年深度学习优化算法研究亮点最新综述火热出炉
深度学习框架哪家强?(TensorFlow/Caffe/MXNet/Keras/PyTorch跑分测试)





