【CVPR2021】基于对比预测的缺失视图聚类方法

背景:实际应用中,由于数据采集和传输过程的复杂性,数据可能会丢失部分视图,这就导致了信息不完备下的视图缺失问题(Incomplete Multi-view Problem, IMP)。例如在线会议中,一些视频帧可能由于传感器故障而丢失了视觉或音频信号。针对该问题,过去十多年已提出了一些不完全多视图聚类方法(Incomplete Multi-view Clustering, IMC)并取得了显著效果。但IMP仍面临两个主要挑战:1)如何在不利用标签信息的情况下学习一致的多视图公共表示;2)如何从部分缺失的数据中还原完整的数据。
http://pengxi.me/wp-content/uploads/2021/03/2021CVPR-completer.pdf
创新:针对上述挑战,受近期Tsai等在ICLR2021上发表的工作所启发,本文提供了一个新的不完全多视图聚类见解,即不完全多视图聚类中的数据恢复和一致性学习是一体两面的,两者可统一到信息论的框架中。这样的观察和理论结果与现有的将一致性学习和数据恢复视为两个独立问题的工作有很大的不同。简要地,从信息论角度出发,互信息能用于量化跨视图表示间的一致性,而条件熵可用于量化跨视图的可恢复性。因此,一方面,最大化互信息与最小化条件熵将分别增加共享的信息量与数据的可恢复性。另一方面,同时最大化互信息与最小化条件熵两个目标又互为补充,相互促进。与Tsai等人的工作的不同之处在于,他们主要是在信息论框架下利用预测学习改进对比学习的性能,没有如本文一样考虑到缺失视图下的一致性和可恢复性的学习。
方法:基于上述观察,论文提出了对偶预测范式并将其与对比学习结合,通过一个新的损失函数实现了跨视图一致性与可恢复性的联合优化。提出的损失函数包括三部分:1)视图内重构损失,主要用于学习各个视图数据的视图特殊表示,由一系列独自的自编码器重构损失组成;2)跨视图对比学习损失,通过最大化不同视图间的互信息学习多视图一致性;3)跨视图对偶预测损失,通过最小化视图表示的条件熵进而实现视图数据恢复。
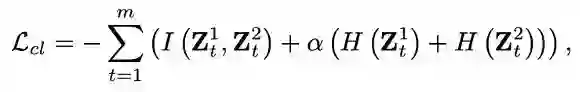
论文提出的方法如图3所示,首先通过各个视图的特殊化自编码器获取隐空间表示,然后在两个视图的隐空间进行对比学习与对偶预测学习。整个框架的所有部分协同合作,端到端地联合训练。训练完成后,将各个视图的表示连接起来,再使用如k-means等方法进行聚类。
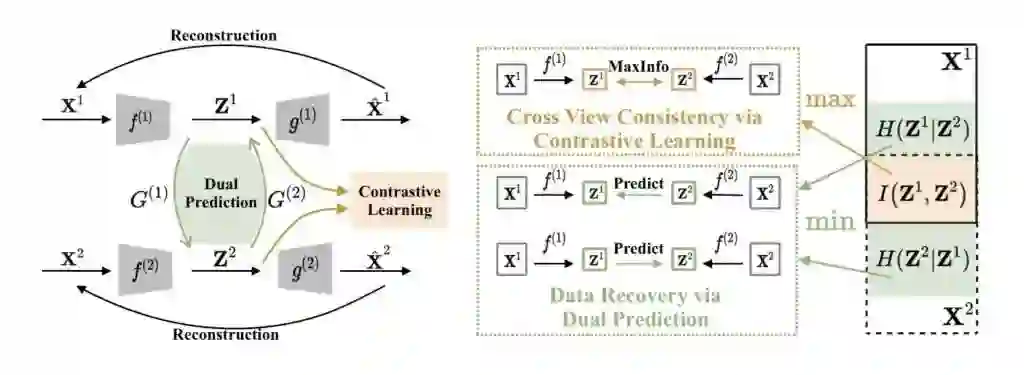
图3.整体框架图
结果:为验证算法的有效性,论文在四个广泛使用的多视图数据集上进行对比实验。使用的数据包括:Caltech101-20、LandUse-21、Scene-15和NoisyMNIST。对比算法包含浅层以及深度学习方法。表2给出了定量比较的结果,从中可看出:1)在数据有缺失的情况下, COMPLETER在Caltech101-20、Scene-15和NoisyMNIST上分别超过最好的对比方法3.07%、4.37%和14.68%的NMI。此外,在ARI方面,COMPLETER在Caltech101-20和NoisyMNIST上相比最佳的对比方法上实现了超过50%的性能提升;2)在数据不缺失的情况下,COMPLETER仍显著优于几乎所有的对比方法。
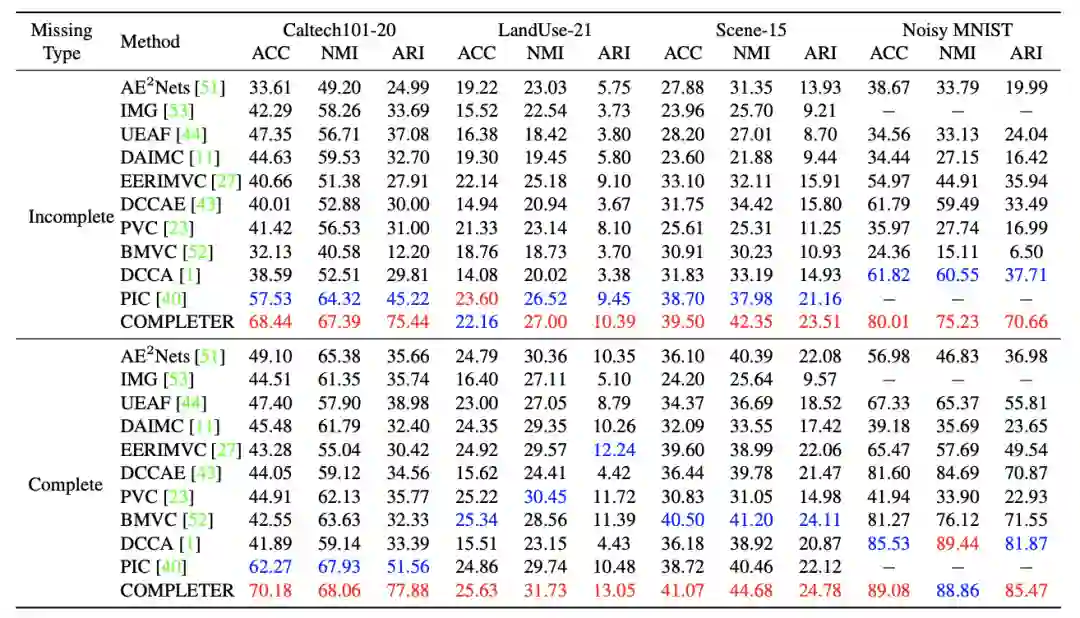
表2.对比实验。表中,缺失模式“Incomplete”表示50%的数据有缺失,“Complete”表示数据完整。红色与蓝色分别标记出最优与次优的结果。
综上:为从有缺失的多视图数据中学习公共表示,本文从信息论角度将一致性学习和数据恢复视为一体两面的两个问题。提出的统一框架将有望为理解一致性学习和数据恢复提供新的见解。
‘
专知便捷查看
便捷下载,请关注专知公众号(点击上方蓝色专知关注)
后台回复“MCCP” 就可以获取《【CVPR2021】基于对比预测的缺失视图聚类方法》专知下载链接





