深入剖析:为什么MobileNet及其变体(如ShuffleNet)会变快?

极市导读
从MobileNet等CNN模型的组成部分出发,本文剖析了它们如此高效的原因,并给出了大量清晰的原理图。
Introduction
在高效的模型中使用的组成部分
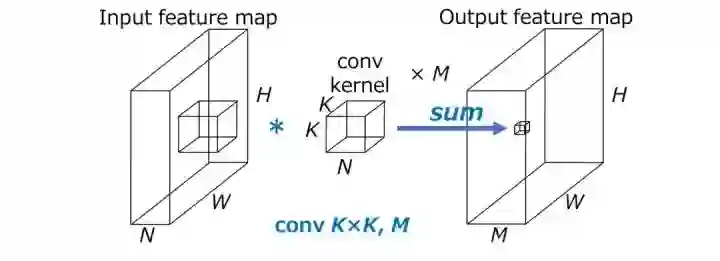
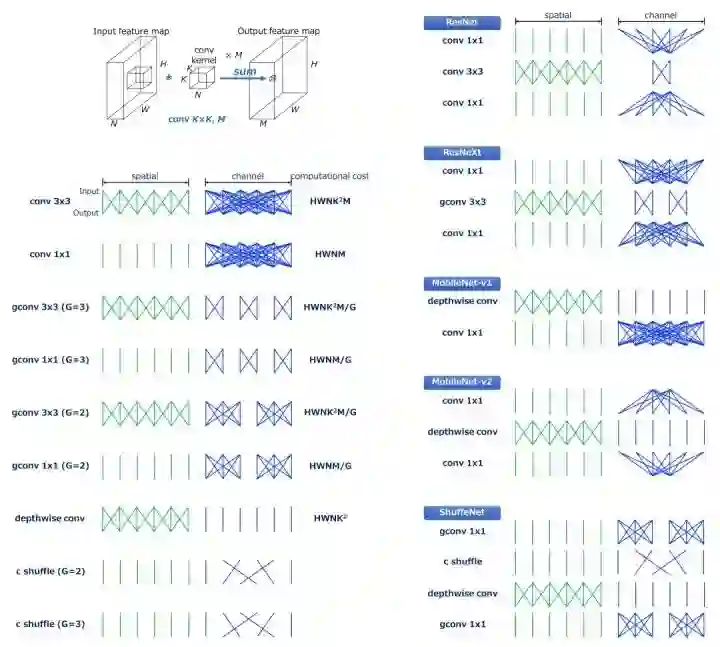
卷积


分组卷积(Grouped Convolution)




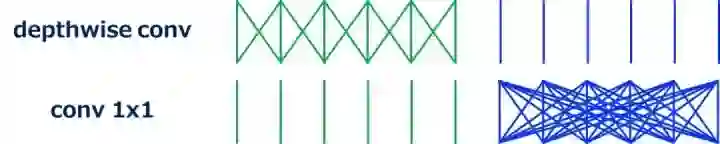
深度可分离卷积(Depthwise Convolution)

Channel Shuffle


Efficient Models
ResNet (Bottleneck Version)

ResNeXt
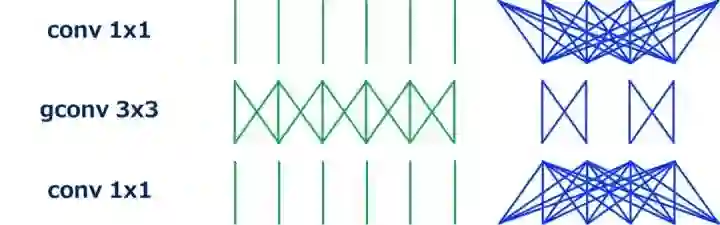
MobileNet (Separable Conv)
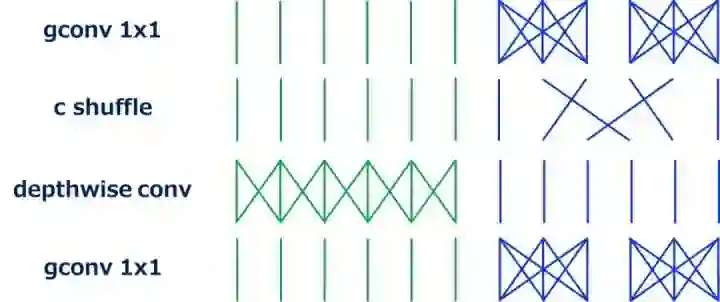
ShuffleNet
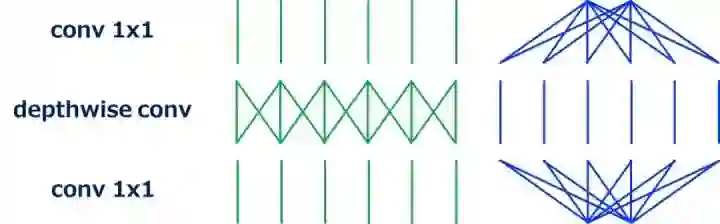
MobileNet-v2
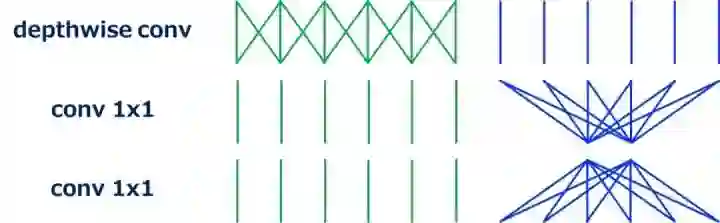
FD-MobileNet
参考资料
推荐阅读




登录查看更多
相关内容

相关VIP内容
相关资讯
相关论文