小米知识图谱团队斩获CCKS 2020实体链指比赛冠军

“CCKS 2020:面向中文短文本的实体链指任务”是由中国中文信息学会语言与知识计算专业委员会主办,该比赛主要面向中文短文本的实体链指,简称 EL(Entity Linking)。即对于给定的一个中文短文本(如搜索 Query、微博、对话内容、文章/视频/图片的标题等),EL 将其中的实体与给定知识库中对应的实体进行关联。

比赛任务
面向中文短文本的实体链指,简称 EL(Entity Linking)。即对于给定的一个中文短文本(如搜索 Query、微博、对话内容、文章/视频/图片的标题等),EL 将其中的实体与给定知识库中对应的实体进行关联。
输入:中文短文本以及该短文本中的 mention 和其在中文短文本中的位置偏移。
输出:输出文本此中文短文本的实体链指结果。每个结果包含:实体 mention、其在中文短文本中的位置偏移、其在给定知识库中的 id,如果为 NIL 情况,需要再给出实体的上位概念类型。

相比于长文本拥有丰富上下文信息能辅助实体的歧义消解,短文本的实体链指存在很大的挑战,包括:
(1)比赛数据集主要来自于:真实的互联网网页标题数据、视频标题数据以及用户搜索 Query。存在口语化严重、语序错乱、错别字多等问题,导致实体歧义消解困难
(2)短文本上下文语境不丰富,须对上下文语境进行精准理解
(3)相比英文,中文由于语言自身的特点,在短文本的链指问题上更有挑战

引言
实体链指的主要目标是识别上下文中的名称指代哪个现实世界中的实体。具体而言,实体链指是将给定文本中的一个指称项映射到知识库中的相应实体上去,如果知识库尚未收录相应实体,则返回空实体。
最近有不少这方面的优秀工作。Ganea O E& Hofmann T. [1] 开创性地在 EL 中引入 Entity Embedding 作为信息,利用 Attention 机制来获得 Context 的表征,通过实体间的一致性,和 Mention 到 Entity 的 LinkCount 先验概率联合消歧。
Le, P., & Titov, I. [2] 不仅仅考虑 Local/Global 的影响,同时将实体的关系也考虑进 Embedding 中,对 Entity,Mention,Relation 元组进行 Embedding,借用 ESIM 思想进行对多关系加权处理,并使用网络进行匹配操作。
Raiman JR&Raiman OM [3] 认为当我们能预测出实体 Mention 的 Type,消歧这个任务就做的差不多了,主要利用 Type System、Type Classifier 和 LinkCount 来达到消歧的目的。
Sil et al. [4] 不但利用包含 Mention 的句子和 Wiki 页面的相似度,还加入了细粒度的相似度计算模型,将几种相似度作为神经网络的输入,避免了句子中不相关单词对 Mention 消歧的影响。综合来看,实体链接不仅要考虑 Text 的文本信息、KB 的信息、消歧后的一致性,还需要根据具体的业务场景采用不同的方案,需要灵活的运用 LinkCount、Context、Attributes、Coherence 这四大特征。
我们针对百度发布的面向中文短文本的实体链指任务,设计的多因子融合实体链指模型。首先采用了预训练的 BERT 来对短文本中的指称项进行类别预测,利用预测的类型构建一个 NIL 实体,和其他候选构成完备候选实体集,然后对每一个候选实体进行多方位的特征因子抽取,利用一个多层感知机将多个特征因子融合打分,最后根据每一个候选实体和文本的关联分数进行排序,选择分数最高的候选实体作为实体消歧预测结果。

模型策略
指称项分类
指称项分类是主要基于 BERT 模型,输入数据文本,指称项的起始位置。输入文本,经过 BERT 模型编码,取 CLS 位置的特征向量、指称项开始和结束位置对应的特征向量,三个向量拼接,经过全连接层,最后 Softmax 激活得到指称项的类别概率分布。模型结构如图 1:
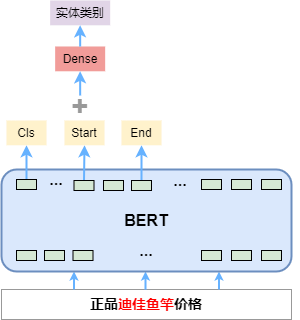
▲ 图1 实体分类模型图
其中优化主要改进的点包括:
(1)二次训练:训练集合中非 NIL 部分的分类数据与 NIL 的分布不同,直接与 NIL 部分的数据一起训练会导致模型整体预测 NIL 实体的准确率下降,而直接用 NIL 部分的数据训练则有些训练数据较少的类会训练的不充分。所以我们采用二次训练的方法,第一次的时候使用了训练集中非 NIL 的部分,训练两个 Epoch,然后再在这个基础上去训练 NIL 部分。
(2)对抗学习:对抗训练是对抗防御的一种,它构造了一些对抗样本加入到原数据集中,希望增强模型对对抗样本的鲁棒性。我们在模型训练的时候加入了对抗学习,所使用的对抗学习方法是 Fast Gradient Method(FGM) [5]。
(3)模型融合:本次使用了 4 个 BERT 预训练模型。模型融合的方法是使用多折的方法训练了一个基于 MLP 的分类模型。
候选实体获取
利用实体的 Alias 字段生成 Mention 和实体的映射表,实体的 Alias 的属性值即为该实体的 Mention,包含该 Mention 的所有实体组成候选实体集合。在候选实体获取时,从 Mention 和实体的映射表中,取出该 Mention 的候选实体集合,然后指称项的类别构成的 NIL 实体组成完备候选实体集。这样组成的完备候选实体集中,必有一个正确的实体和文本中的指称项关联。训练时,指称项的类别来自标注文本中 Kb_id 对应的实体类型,预测时,指称项的类别由 3.1 部分描述的指称项分类模块预测得到。
为了后续使用方便,我们将完备候选实体集中的实体属性进行拼接,处理成实体的描述文本。由于 Type 字段,义项描述和摘要字段的信息重要且占比较大,描述文本中都按照 Type、义项描述、摘要和 Data 中其他 Predicate、Object 对的顺序进行拼接。
例如文本"永嘉厂房出租"中“出租”对应的候选实体 Id 和描述文本为[["211585", "类型:其他|简介:动词,收取一定的代价,让别人在约定期限内使用|外文名:rental|拼音:chū zū|解释:交纳租税|中文名:出租|举例:出租图书|日本語:レンタル|标签:非娱乐作品、娱乐作品、小说作品、语言、电影、字词"], ["304417", "类型:车辆|描述:辞源释义|简介:出租车,供人临时雇佣的汽车,多按里程或时间收费,也叫出租车|外文名:Taxi、 Cab、 Hackies|粤语:的士|台湾名:计程车|拼音:chūzūchē|中文名:出租车|新加坡名:德士|标签:交通工具、社会、生活"], ["NIL_Other", "类型:其他|描述:未知实体"]],其中“211585”和“304417”为检索到的候选实体集合,NIL_Work 为生成的候选实体,一起组成了“出租”在该文本下的完备候选实体集。
实体消歧
针对实体消歧任务,目前最常用的方法是将其视为二分类问题。对每一个候选实体进行多方位的特征因子抽取,将这些特征因子利用一个多层感知机模型进行融合打分,预测每一个候选实体和指称项的关联分数。最后对这些分数进行排序,由于我们在候选实体获取阶段,构建的是完备候选实体集,那么必有一个正确候选实体,所以在排序后选择 Top1 即可作为指称项的关联实体。
特征因子抽取的抽取包括上下文相关特征和上下文无关特征,其中上下文相关特征包括指称项和候选实体的关联概率计算,多个指称项之间的关联概率计算等,上下文无关特征包括实体的流行度、实体的类型等。
这里起到关键作用的特征就是指称项和候选实体的关联概率。指称项和候选实体的关联概率和语义相似度计算的区别在于需要指明文本中待消歧的指称项。我们利用标记符在文本中直接标记出指称项的位置,指明待消歧的指称项。输入文本和候选实体描述文本,在文本的指称项开始和结束位置添加标记符,经过 BERT 模型编码,取 CLS 位置的特征向量,经过全连接层,最后 Softmax 激活得到文本中指称项和候选实体之间的相关性。求指称项和候选实体关联概率的模型结构如图 2 所示。
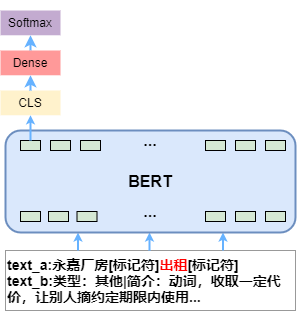
▲ 图2 实体链接模型图
另外我们在实体消歧模块也尝试加入对抗学习来提高模型的鲁棒性,其中对抗学习的方法是 FGM。不同的 BERT 预训练模型抽取的特征不同,为了丰富特征,本模块采用了 19 个特征因子来从不同方面刻画指称项和候选实体的相关性。这 19 个特征如下表 1 所示,分别为:

▲ 表1 实体消歧特征
特征因子融合的方法是使用多折的方法训练了一个 MLP 的模型。将所有数据集分成 n 份,不重复地每次取其中一份做测试集,用其他四份做训练集训练模型,训练得到 n 个模型。预测时,取 n 个模型的预测结果的平均值,作为预测结果。

比赛结果
CCKS 2020 中文短文本的实体链指比赛,限定在给定的标注数据和知识库中。标注数据均通过百度众包标注生成,准确率 95% 以上。标注数据集主要来自于:真实的互联网网页标题数据、视频标题数据、用户搜索 Query。
每条标注数据包含 Text,Text_id 和 Mention_data 字段,Mention_data 里面包含连接的 Mention,Offset 以及 Kb_id 字段。知识库包含来自百度百科知识库的约 39 万个实体。知识库中每行代表知识库的一条记录(一个实体信息),每条记录为 Json 数据格式。
指称项分类模型训练中使用二次训练的方法 F1 提升了约 1%,使用对抗学习 F1 提升了约 0.5%,模型融合后在 Dev 数据上 F1 值达到了 90.02%。具体参数和验证数据集下结果如下表:
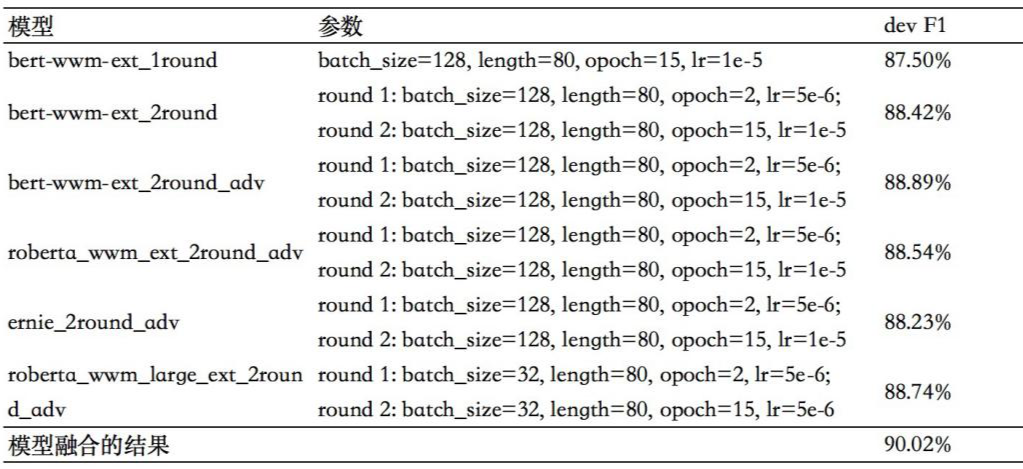
▲ 表2 实体分类参数以及结果
实体消歧模型共抽取了 19 个特征因子,使用多折的方法训练了一个 MLP 的模型对这些特征因子进行融合,融合后在 Dev 数据上 F1 值达到了 89.29%。具体参数和验证数据集下结果如下表:


总结与讨论
本文对实体链指消歧做了一些探索。利用指称项类型预测,构建 NIL_type 实体,解决无链接指代预测问题,同时利用 BERT、对抗学习、特征融合等训练方法极大地提高了实体消歧的准确率,获得了比赛的第一名以及创新奖,相关论文已被 CCKS 2020 收录。
比赛也为小米的后续研究指明了方向。比如当前方法没有充分利用其它指称项的侯选实体信息,对其他指称项信息的利用仅仅停留在名称层面。另外,可以利用一些特征,先对候选实体进行一次排序,选择排序前几的候选实体进行下一步的消歧,这样分层消歧在候选实体过多的情况下不仅可以提高准确率,还能提高消歧效率。

参考文献
更多阅读




#投 稿 通 道#
让你的论文被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学习心得或技术干货。我们的目的只有一个,让知识真正流动起来。
📝 来稿标准:
• 稿件确系个人原创作品,来稿需注明作者个人信息(姓名+学校/工作单位+学历/职位+研究方向)
• 如果文章并非首发,请在投稿时提醒并附上所有已发布链接
• PaperWeekly 默认每篇文章都是首发,均会添加“原创”标志
📬 投稿邮箱:
• 投稿邮箱:hr@paperweekly.site
• 所有文章配图,请单独在附件中发送
• 请留下即时联系方式(微信或手机),以便我们在编辑发布时和作者沟通
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
关于PaperWeekly
PaperWeekly 是一个推荐、解读、讨论、报道人工智能前沿论文成果的学术平台。如果你研究或从事 AI 领域,欢迎在公众号后台点击「交流群」,小助手将把你带入 PaperWeekly 的交流群里。





