【比赛获奖方案开源】中文短文本实体链指比赛技术创新奖方案开源
【导读】人工智能相关比赛的获奖方案,无一不是在某一具体问题上拥有独到的理解和踏实的实现的。每次小编阅读比赛获奖方案,都能明显感受到我与强者的距离。这次为大家带来获奖方案来自2019「全国知识图谱与语义计算大会-中文短文本实体链指」。shouc
【任务介绍】
实体链指(Entity Linking)是NLP领域的基础的任务,一般与实体识别(Entity Recognition)深度绑定在一起。一般的Pipline为:对于一个给定的文本,先用ER识别出其中的实体,然后再用EL将该实体与给定知识库中的对应实体进行关联。
以上任务在中文环境,以及短文本(微博、文章标题)场景下变得越发困难。主要原因如下:(1)口语化严重,导致实体歧义消解困难;(2)短文本上下文语境不丰富,须对上下文语境进行精准理解;(3)相比英文,中文由于语言自身的特点,在短文本的链指问题上更有挑战。
2019年的全国知识图谱与语义计算大会,开设了「中文短文本实体链指比赛」旨在尝试在该领域做一些突破。具体的比赛任务如下:
输入:
输入文件包括若干行中文短文本。
示例:
输入:
{
"text_id":"1",
"text":"比特币吸粉无数,但央行的心另有所属|界面新闻 · jmedia"
}
text_id 为文本序号,text字段为单条输入文本
输出:
输出文本每一行包括此中文短文本的实体识别与链指结果,需识别出文本中所有mention(包括实体与概念),每个mention包含信息如下:mention在给定知识库中的ID,mention名和在中文短文本中的位置偏移。实体链指结果,结果为json格式,包含text_id、text和mention_data三个字段,text_id和text字段与输入一一对应,mention_data字段为链指结果,每个mention必须包含kb_id、mention和offset三个字段,分别对应知识库实体id、mention名以及mention在字符串中的偏移。
示例:
输出:
{
"text_id":"1",
"text":"比特币吸粉无数,但央行的心另有所属|界面新闻 · jmedia"
"mention_data":[
{
"kb_id":"278410",
"mention":"比特币",
"offset":"0"
},
{
"kb_id":"199602",
"mention":"央行",
"offset":"9"
},
{
"kb_id":"215472",
"mention":"界面新闻",
"offset":"18"
}
]
}
说明:
对于实体有歧义的查询 ,系统应该有能力来区分知识库中链接的候选实体中哪个实体为正确链指的实体结果。例如,知识库中有3个不同的实体都可能是『比特币』的正确链指结果,但在给定的上下文中,有足够的信息去区分这些候选实体哪个才是应该被关联的结果。
【获奖解决方案】
AlexYangLi 同学,近日在Github上开源了他们的解决方案,该方案荣获中文短文本实体链指比赛技术创新奖。
方案开源地址: https://github.com/AlexYangLi/ccks2019_el
如下是AlexYangLi 同学对其方案的介绍:
整体设计思路
本次比赛我使用的是 pipeline 的方式解决实体链接问题,即先进行实体识别,而后进行实体消歧。由于中文缺少显式的词语分割符,基于词序列的实体链接容易受分词错误影响。但基于字序列的实体链接又无法充分利用句子中单词的语义信息。因此本次比赛的整体设计思路是在子序列输入的基础上,加入额外的信息来增强字的语义表达,即使用 enhanced character embedding 解决中文短文本实体链接问题。具体而言,对于实体识别,由于要求所识别的实体必须存在于知识库中的 mention 库,因此考虑加入 mention 库匹配信息;而对于实体消歧,在同一文本中出现的不同 mention 的 representation 应该不同,因此考虑加入 mention 的位置信息。
实体识别
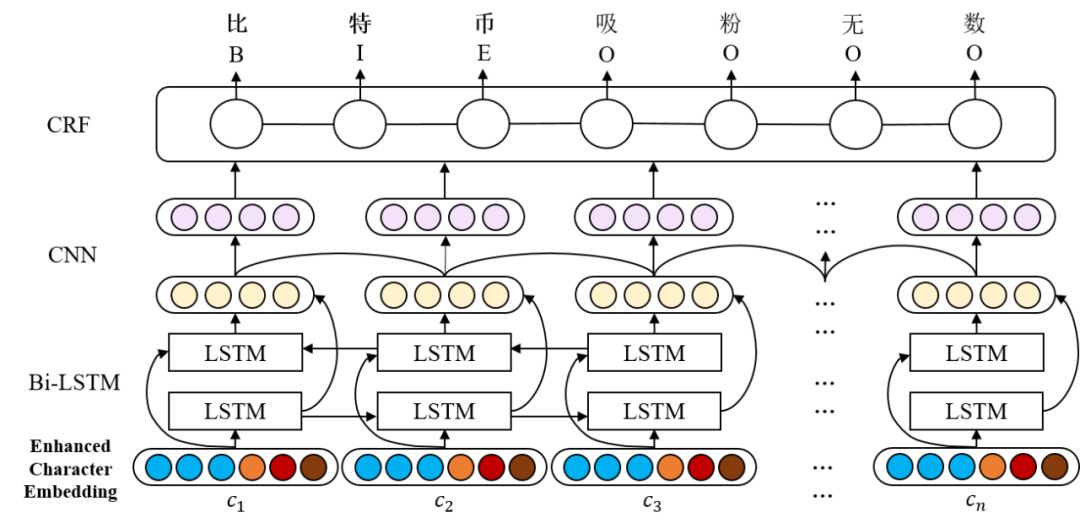
实体识别我采用经典的 BiLSTM+CNN+CRF 序列标注模型,输出使用 BIOES 标注。而在输入层上,我们除了使用字向量序列作为基础输入,还在此基础上拼接了一系列具有丰富语义信息,有助于识别实体 mention 边界的 embedding。拼接的 embedding 主要有:
c2v
使用word2vec的方法对训练语料的字序列进行训练,得到300维的字向量。这是实体识别模型的基础输入。
bert*
从在大规模语料上训练的预训练语言模型,如 bert,ernie,bert_wwm 也可以得到768维的字向量。
bic2v
邻接字bigram向量。将训练语料切成bigram字序列,如句子
“比特币吸粉无数”会被切成序列:['比特', '特币', '币吸', '吸粉', '粉无', '无数'],然后使用word2vec的方法进行训练得到50维的邻接字bigram向量。间接引入mention库匹配信息的embedding
我们将
kb_data中所有的 alias 词典(即 mention 库)视为用户词典,导入至 jieba 后对文本进行分词,这样能最大程度保证 mention 作为一个完整的词被分割出来,然后我们加入以下embedding:w2v@c字符所在词向量。分词得到训练语料的词序列后,我们先使用word2vec的方法进行训练,得到300维的词向量。然后我们为每个字都拼接上其所在的词的词向量,这样来自同一个 mention 的字都具有相同的词向量,有利于实体识别。
cp字符所在词的位置特征向量。我们使用 BMES 标记字符在词中的位置。如句子
“比特币吸粉无数”被 jieba 切成的词序列为:['比特币', '吸粉', '无数'],则字符的位置信息将会被标注为[B, M, E, B, E, B, E]。我们为这四个标记分别随机初始化一个50维向量,然后在模型训练时再进行优化。cp2v位置感知的字符向量。将字序列与对应的位置标注序列结合起来,如上例的
“比特币吸粉无数”将会得到序列:['比B', '特M', '币E', '吸B', '粉E', '无B', '数E']。我们使用word2vec的方法对这些加入了位置信息的字序列进行训练,得到位置感知的字符向量。可以看到,每个字加入了位置标注信息后,都会有4个不同的向量。直接引入mention库匹配信息的embedding
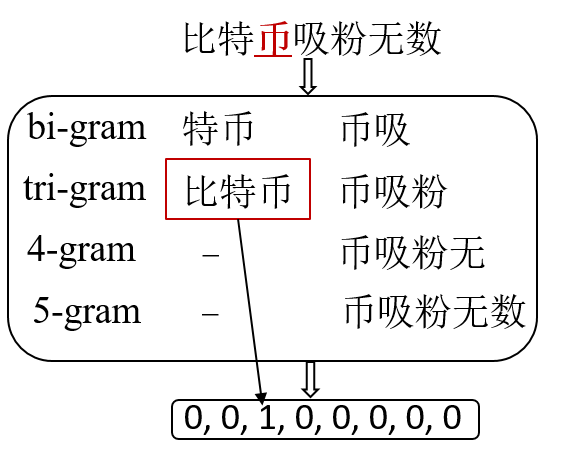
ngram-match
ngram匹配特征向量。我们将以每个字为首(尾)的 bi-gram, tri-gram, 4-gram 等与 mention 库进行匹配,得到 one-hot 向量。如下图例所示,考虑对“币”的 n-gram,发现只有以“币”为尾的 tri-gram “比特币”能够与 mention 库匹配。max-match
双向最大匹配特征向量。我们将 mention 库作为分词词典,使用双向最大匹配分词算法找出所有候选 mention。如句子“比特币吸粉无数”使用双向最大匹配算法后会得到分词序列:['比特币', '吸粉', '无数'],然后我们使用 BMEO 标注('O'表示不是mention)将序列标注为[B, M, E, B, E, B, E]。我们为这四个标注分别随机初始化一个50维向量,然后在模型训练时再进行优化。
实体消歧
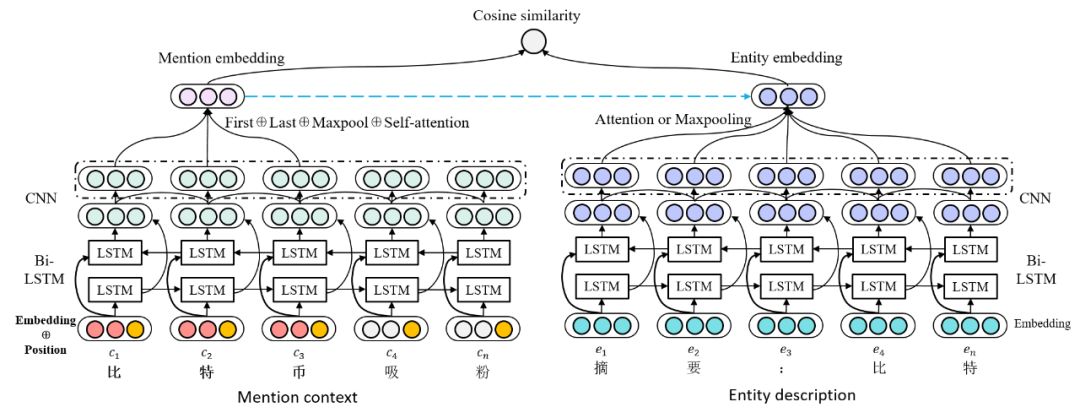
实体消歧使用语义匹配的思路,我们使用待消歧文本以及知识库中候选实体所有三元组拼接起来的实体描述文本作为匹配文本对,使用神经网络对它们进行建模得到各自的 representation,然后使用 cosine 相似度进行匹配度打分,选择得分最高的候选实体输出。神经网络框架大体是 BiLSTM+CNN,由于待消歧文本与候选实体描述文本的长度相差较大,我们没有使用孪生网络结构。下面重点介绍 mention embedding 和 entity embedding 如何生成。
mention embedding由于在同一文本中可能存在不同的mention,他们的 representation 也应该是不同的。如
“唱歌的李娜和打网球的李娜是同一个人吗?”中的两个李娜就对应着不同的实体,对它们的建模也应该不一样。因此我们考虑加入 mention在文本的位置信息,主要有两种方法:首先,我们在字向量序列输入的基础上,拼接上每个字与 mention 的相对位置向量,以反映他们与 mention 在距离上的紧密程度。相对位置向量一开始会被初始化成50维的向量,而后随着网络进行优化。
经过 BiLSTM+CNN 后,我们只选取 mention 部分的输出序列来产生 mention embedding。具体而言,我们将 mention 输出序列中第一个字向量、最后一个字向量、 maxpooling 向量以及使用 self-attention 得到的向量进行拼接,最后通过一层简单的全连接层得到 mention 表达。
entity embedding得到 BiLSTM+CNN 输出的隐藏向量序列后,我们尝试了两种方法来得到 entity embedding:

对隐藏向量序列进行maxpooling,选择时间步上值最大的进行输出。
考虑 entity 描述文本每个字与 mention 的相似度,使用 mention embedding 与隐藏向量序列进行 attention 计算,而后使用隐藏向量的加权和结果作为 entity 表达。我们主要尝试了 3 种 attention 权重的计算方式:
训练细节训练实体消歧模型时,我们采用的的损失函数是 L(m, e+, e-) = max(m+score(m, e-)-score(m, e+), 0),其中 m 是 margin 的意思,即正确实体与 mention 的匹配得分要比错误实体的匹配得分至少高出一个 margin 的大小。实验里我们设置 margin 为 0.04。此外,我们会为每个正确实体采样 n 个错误实体(即负样本),实验中我们发现 n 取 4 或 5 最佳。
集成
为了提分,我们还采用了两种模型集成的方式。
weight averaging在训练单模型的时候,当模型训练了一定的 epochs 之后,模型逐渐接近(局部)最优点。这时候我们复制一份模型的权重 wa 在内存中。当新的一轮迭代结束之后,会产生一份新的模型权重 w,然后我们按照以下公式更新 wa:
从公式上我们可知,这种方法实际上便是对模型训练的最后几次迭代产生的模型进行参数上的平均。这种方式产生的模型更加“平滑”,总是要比训练得到的最好模型更优。
output averaging我们还尝试了对不同模型的输出取平均的方法来进行集成。下面是关于实体识别与实体消歧的不同模型的设置:
对于实体识别模型,我们对除了 c2v 外的输入 embedding 进行 ablation 实验发现它们对 performance 的贡献程度是为 w2v@c > bert* > max_match > ngram_match > cp > bic2v ≈ cp2v。因此考虑加或不加 bic2v 和 cp2v 向量,以及使用何种预训练语言模型(3种),我们可以产生在输入特征上有所不同的实体识别模型。
对于实体消歧模型,考虑是否添加相对位置向量,是否使用CNN,以及 entity embedding 的产生方式,我们也可以得到在模型结构上不同的实体消歧模型。

更多内容,请到方案开源库中查看。
-END-
专 · 知
专知,专业可信的人工智能知识分发,让认知协作更快更好!欢迎登录www.zhuanzhi.ai,注册登录专知,获取更多AI知识资料!

欢迎微信扫一扫加入专知人工智能知识星球群,获取最新AI专业干货知识教程视频资料和与专家交流咨询!

请加专知小助手微信(扫一扫如下二维码添加),加入专知人工智能主题群,咨询技术商务合作~

专知《深度学习:算法到实战》课程全部完成!560+位同学在学习,现在报名,限时优惠!网易云课堂人工智能畅销榜首位!

点击“阅读原文”,了解报名专知《深度学习:算法到实战》课程




