Science:领导决策的计算和神经生物学基础

来源:思影科技
摘要:最近,来自苏黎世大学的Micah G. Edelson等人在SCIENCE上发文,他们将基于知觉和价值决策的模型结合起来,以评估被试对每一个决策行为的个人效用,从而梳理出选择领导或服从的潜在动机。
最近,来自苏黎世大学的Micah G. Edelson等人在SCIENCE上发文,他们将基于知觉和价值决策的模型结合起来,以评估被试对每一个决策行为的个人效用,从而梳理出选择领导或服从的潜在动机。
研究者还用脑成像技术来检验领导决策的神经生物学基础。该研究确定了责任规避在行为和神经生物学层面上对领导者决策的影响,并发现责任规避普遍存在,即如果他人的福利受到威胁,决策者就会减少做出决定的意愿。研究者发现个体的基本偏好、风险趋向、损失厌恶和信息模糊等因素并不能解释责任厌恶(责任规避),研究者认为它是由一种二阶认知过程驱动的,反映出当其他人的福利受到影响时,决策者对最佳选择的确定性的需求增加。
最后,研究者认为他们所构建的模型估计了处理不同选择成分的大脑区域之间信息流动的水平,这为理解在责任厌恶和领导评分中个体差异的神经生物学提供了新见解。
关键词:决策 责任规避 任务态fMRI DCM 动态因果 回归预测
在现实生活中,领导者在进行有关组织的决策时,必须为他人承担责任,比如把士兵派入战场上,或者你为你的孩子挑选一所学校,都有一个基本的属性:为他人的结果承担责任。这一责任在首相和将军们的角色中,以及在公司经理、教师和家长的日常角色中都是固有的。而且这些决策将影响个人、甚至组织和国家的福祉。因此,研究者试图理解领导决策潜在的行为、计算和神经生物学机制。
方法:
实验
为此,研究者设计了一个实验,使其能够区分领导决策是与基本偏好、风险趋向、损失或信息模糊有关,还是通过一个单独的机制影响领导责任感从而影响领导决策。被试最初被分成四组。为了增强个体间关系而设计了组织形成任务(见补充方法2.1.1),每个被试都独立于其他组成员完成了基线选择任务。
在这项任务中,被试在每次试验中决定是否接受或拒绝一场涉及收益和损失概率的赌博任务(图1A和附录S1)。研究者考虑到现实的决策情景下,很难得知成功的确切概率,所以这项任务包括了许多关于收益和损失的模糊概率的试次。然而,为了区分个人对风险趋向和信息模糊的态度,这项任务也包含了精确概率已知的试验。在领导者决策(授权)任务(图1B)中,被试面对的是与基线任务相同的赌博,但是现在他们可以选择自己做决定(例如举荐自己为领导者)或服从小组的决定。
领导者决策任务有两种类型的试次,即自我试验和小组试次,在自我试次中,只有进行决策的被试的奖励受到影响,而其他组织内成员的奖励没有受到影响。而在小组试次中,决策结果影响了每个组内成员的收益。而且对于每一个匹配的基线和委托试验,两个小组成员不会看到相同的部分得失概率分布(图1 c)。研究者以此在两个独立的被试样本中收集并分析了这些决策数据:第一个数据集只探查了决策的行为数据,而第二个数据集,研究者不仅探查了行为实验的数据,也对神经成像数据进行了采集和分析。
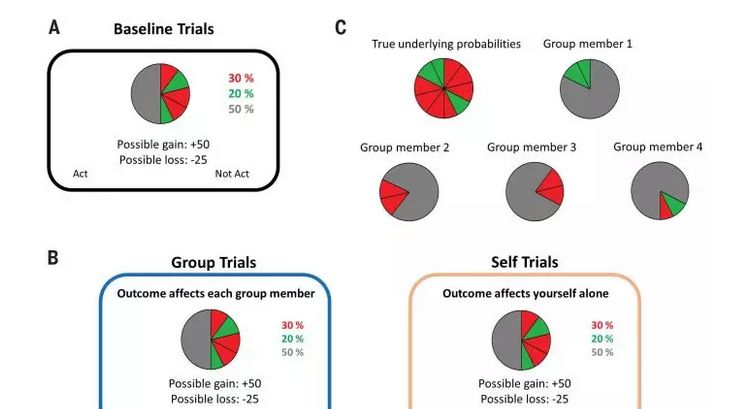
图1.实验设计
磁共振数据的处理与分析
磁共振数据使用Philips 3T扫描仪采集,TR为2204ms,体素大小为3*3*3mm。数据预处理使用SPM 12完成,具体步骤包括:去除前5张全脑像、头动校正、时间层校正、两步配准(T1像配准)、空间平滑。随后剔除了头动大于3mm的被试。一阶分析中,作者构建了三种GLM模型:
(1)第一种GLM只区分小组试次和自我试次,此外还考虑了RT、SVd、p(l|u),分别表示反应时、主观价值差异、决定做领导的概率;
(2)第二种GLM类似于第一种,除了区分小组试次和自我试次,还区分选择类型(服从小组决定还是独自做决定);
(3)第三种GLM和第二种也类似,又增添了一个表示信息优势的参数。二阶分析(组分析)使用T检验,把责任规避作为协变量,得出了各种情况的激活脑区,结果进行了多重比较校正。随后作者构建了DCM模型,以便利用DCM模型参数来预测责任规避和领导力得分。DCM模型的构建选用了4个时间序列(分别来自mPFC、aIns、TG、TPJ,参见表S3),这些脑区都对应GLM模型各种contrast的峰值点。回归模型选择了弹性网络回归,并进行了留一交叉验证。总而言之,大致过程为:预处理、一阶分析、二阶分析、构建DCM、预测。
分析与结果:
基线偏好与领导能力
研究者分析了基线任务中的风险趋向、损失和信息模糊是否与领导得分(量表测量)有关。研究者发现其关系并不显著(补充材料表1和图2)。此外,个体的信息优势的敏感性、响应时间和选择一致性的都与领导得分相关不显著(补充材料表S1和补充结果1、2和7)。
决策权和控制权偏好的作用
无论是在自我试次中还是在小组试次中的每一项决策,都要求被试选择是自己做出决定,还是放弃做出选择的权利,并遵循小组其他成员的集体判断。研究者发现与不重视个人决策权的被试相比,高度重视维护其私人决策权的被试在自我试次中表现出相对较低的延迟率。
研究者还发现被试一般倾向于在自我试次中保持对自己结果的控制,并且愿意在具有信息优势的情况下服从小组决定(mean = 62.7%; Wilcoxon signed-rank test versusa random-choice null hypothesis, zscore = 6.0, P = 2 × 10-9)),但是,在自我试次中控制选择的比例与个人领导得分无关(图2A)。
此外,研究者发现领导者被试就像在自我试次中一样,更倾向于保持对群体结果的控制。然而,被试对结果的控制偏好和领导得分之间相关不显著(图2B)因此,对偏好决策权利和对自我或他人的控制并不能解释在领导得分上的个体差异,这表明可能还有其他不同的动机力量在起作用。
领导和责任规避
大多数被试更倾向于逃避责任,即大多数被试在小组试次的服从选择多于自我试次(Wilcoxon signed-rank test, zscore = 5.4, P = 5 × 10-8)。因此,研究称之为“偏好责任规避”。最重要的是,那些表现出较少责任感的人的领导得分更高(图2 C;r =-0.46, P = 2 × 10-4)。为了验证其生态效度,研究者收集了来自被试的真实的领导行为(在强制服兵役期间获得的等级和在童子军组织中的领导经验,补充方法2.3.4)。责任规避是与这些现实生活中的领导表现有显著相关的唯一因素(图2D,r=0.49,P=0.02)。而且,研究者根据原始行为样本的基础上计算出的参数预测了fMRI样本(第二个独立样本)的领导分数的得分。fMRI样本预测的领导分数确实与这些被试的经验观察结果有显著的相关性(图2E,r = 0.44, P = 0.004; 补充的结果。)
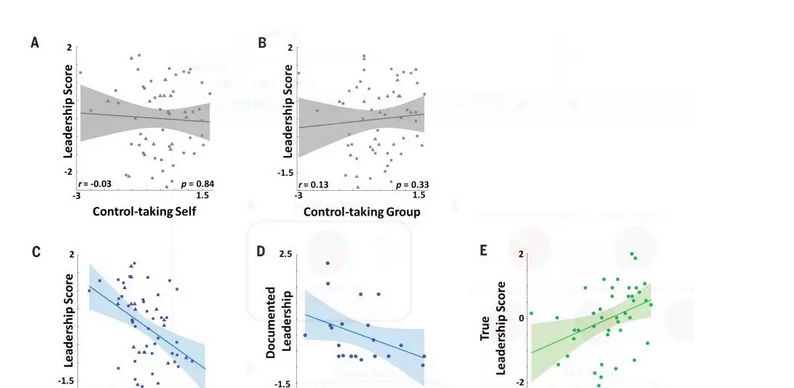
图2.责任规避的行为证据
责任规避
研究者为了了解责任厌恶的认知驱动过程,通过建模来进一步确定潜在的责任规避机制。研究者发现服从选择的模式(图3A)和反应时间(图3B)提供了一个初步的线索。研究者估计了被试的偏好参数(例如使用前景理论模型(补充方法3.1; 对风险、损失、模糊和概率权重的态度)还请参阅补充结果9),并使用这些参数来计算在试次中接受和拒绝选项之间的主观价值差异。
研究者发现当主观价值差异较低时,反应时间是最高的。在给定的试验中接受(或拒绝)赌博是最好的选择时,参与者通常是自己做决定,而不是让团队来决定。然而,当不能以损失、风险和模糊来判断什么时最佳选择时(确定性低),即主观价值的差异很小时,被试更频繁地服从于群体。服从阈值是由接受和拒绝赌博之间的关键的主观价值差异定义的(例如在图3 C的垂直线条中,主体在不同的位置之间切换)。因此,不愿承担责任的被试在在小组试次中要求最好的选择是具有更高确定性,这就等于在小组试次中更大的差别阈限(图3C和D)。
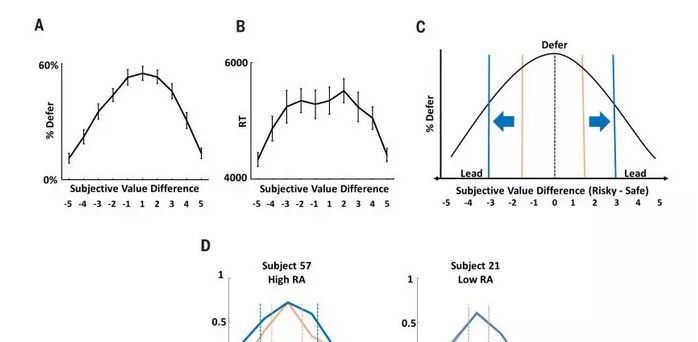
图3.服从行为的模式
计算模型解释领导行为和责任规避
研究者建立了一个计算模型,在这个模型中,个人偏好参数和他们的服从阈值是根据他们在自我和小组试次中的行为同时估计的。如果标准的偏好在不同的条件之间有很大的差异,而服从阈值保持不变,那么对责任的规避最好的解释是传统偏好的变化。然而,如果传统的偏好估计在群体和自我试次中保持不变,而服从阈值则各不相同,那么责任规避可以归因于服从阈值的变化,以及关于服从的相对效用的信念。
计算模型准确地捕捉了决策行为的模式(图4A和B;请参见表S2中的表S2和参数恢复练习的模型比较结果)。这使研究者能够使用它来确定决策过程的哪些潜在因素受其他人收益的影响。对不同条件下的模型参数的直接测试表明,小组试次导致了服从阈值的增加(mean change (±SD) is 1.26 (±0.23);posteriorprobability of a difference between the conditions is >0.999),但没有影响任何其他模型参数(图4 C)。
因此,对他人负责并没有改变参与者处理关键决策相关信息的方式,比如奖励大小、风险或信息模糊性,而是导致了服从阈值的变化,这又表明被试对小组中最佳选择的确定性需求更高。几乎所有的被试在小组试次中的服从阈值都相对于自我试验增加(图4D)。此外,这些在服从阈值上的个体水平变化与领导得分相关(r= -0.46,P= P = 3 × 10-4),且更稳定的阈值与更高的领导得分相关。
研究者的研究结果提出了选择领导或者服从的理论解释:被试根据他们对最佳选择的确定性的需求,再在主观价值空间中进行评估,从而做出选择领导或服从的决策。
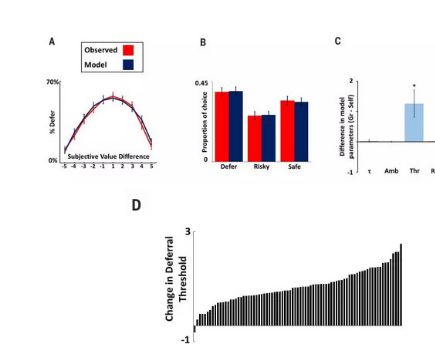
图4.计算模型结果
责任规避的神经机制
研究者发现,相比于自我试次,小组试次中TG的活动更高。在TG活动的前提下,观察到了在更强的责任规避下,mPFC对aIns的影响是不同的; TG活动的升高与mPFC对aIns的抑制效应有关。领导者一般表现出较少的抑制。这或许是差别阈限改变的潜在神经机制。这些发现支持了责任规避是与mPFC活动有关的主观价值计算的一个二阶过程结果。

图5. DCM模型预测与真实值的相关(A,差别阈限,B,领导力得分);mPFC对aIns的影响受到TG活动的调节(C)。
综上所述,这些结果表明,责任厌恶是一个强有力的且生态效度高的领导预测因子。这些结果表示,当个人面临领导他人进行决策时,决策过程中的一些关键的潜在因素必须改变,而不是面对相同决策时仅仅单独为自己考虑。
参考文献:
EdelsonM G, Polania R, Ruff C C, et al. Computational and neurobiological foundationsof leadership decisions[J]. Science, 2018, 361(6401): eaat0036.
未来智能实验室是人工智能学家与科学院相关机构联合成立的人工智能,互联网和脑科学交叉研究机构。
未来智能实验室的主要工作包括:建立AI智能系统智商评测体系,开展世界人工智能智商评测;开展互联网(城市)云脑研究计划,构建互联网(城市)云脑技术和企业图谱,为提升企业,行业与城市的智能水平服务。
如果您对实验室的研究感兴趣,欢迎加入未来智能实验室线上平台。扫描以下二维码或点击本文左下角“阅读原文”




