NeurIPS 2020 | AWS Auto-Aug: 利用权重共享思想的新型自动数据增强方法解读

导读:在NeurIPS 2020上,商汤研究院工具链的搜索和决策团队提出了一项基于权重共享的新型自动数据增强方法。该工作以多项有启发性的实验现象为动机,第一次从权重共享角度思考自动数据增强,实现了既高效又有效的增强策略搜索算法。该方法在多个图像分类数据集上取得了优秀的表现,尤其在CIFAR-10数据集上刷新了当时的SOTA性能。
论文名称:Improving Auto-Augment via Augmentation-Wise Weight Sharing
背景与挑战
数据增强是深度学习中被广泛运用的一项正则化技术,其被用于提升数据分布的多样性。例如对图像数据,常用的操作有仿射变换、调整色相/饱和度/曝光、锐化等。最近一些自动数据增强算法被提出,其旨在自动搜索一些数据增强策略(通常可表示为各个操作的概率分布),使得在这些策略下进行训练的模型可以得到更好的性能表现。这些自动算法已经取得了显著的成果,在许多任务上远远超过了人工设计的增强策略。然而,这项技术仍然存在挑战:
1.速度:一个最直接的搜索方式是每次从头训练模型,以其最终的验证集性能为指标来评估增强策略并更新。这需要成千上万次的反复训练,开销巨大。只有Google最早的自动数据增强[1] 使用了这样的搜索方式。我们把这个搜索方式称为“原始任务”。
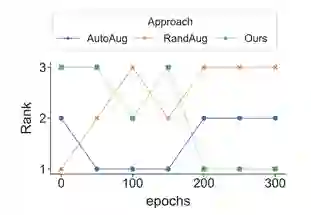
2.可靠性:后续许多自动增强算法选择牺牲可靠性来换取效率。这些算法大都采用了迭代近似的思想,设计了一项“代理任务”代替“原始任务”,即:只完整地训练一次模型;每隔一个或数个模型优化迭代步数,就选择一次指标来评估、更新数据增强策略。然而最近一些神经网络架构搜索(NAS)的工作指出,对训练早期的模型进行评估往往是不准确的(早期表现优秀的模型,在后期不一定仍然优秀)。这在我们的实验中也得到了验证。如下图,不同数据增强策略下的模型,在训练过程中的相对排名变化很大。
一个更理想的自动数据增强算法需要同时兼顾效率与可靠性。为实现这一点,我们观察了带有数据增强的训练过程。通过发现的一些性质,同时借由NAS领域的权重共享策略,我们提出了一种新型自动数据增强算法。
动机
1.数据增强的性质
我们不妨先从另一项正则化手段入手:早停(Early Stopping),即在验证集误差开始显著上升时停止训练。早停非常符合直觉,其也许能体现过拟合带来的负面影响往往是在后期才显露出来的。因此,我们猜想数据增强也有类似性质:数据增强主要是在后期提升模型的泛化能力。为了验证这一点,我们在CIFAR10上使用Google AutoAug [1]对ResNet18在不同阶段进行了数据增强。即:我们始终训练300轮(epoch)模型,但只在开头或结尾的Naug轮里进行数据增强。结果如下图,蓝色实线代表在开头数个轮次的训练中带有数据增强,橙色虚线代表在末尾数个轮次的训练中带有数据增强。例如图中标出的蓝点表示在第1至第75个轮次里使用了数据增强,而在第76至第300个轮次里未使用。
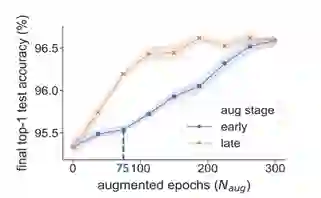
由图可见数据增强确实在后期作用更加显著。例如均只在x轮采用数据增强,那么将x轮放在训练后期比放在前期会带来更大的提升;同时,为了达到相同的精度,在后期进行增强相比在前期进行增强,需要的轮数更少。
2.权重共享的思想
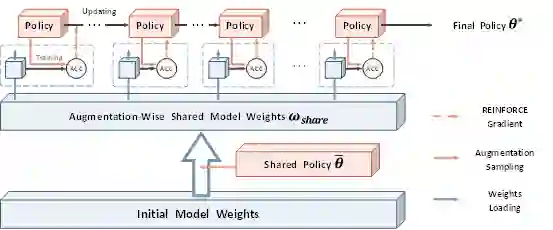
既然数据增强在后期更加重要,我们大可利用这一点,尝试将前期不太重要的阶段“共享”起来,只聚焦在后期进行评估和搜索,来达到提升效率的目的。受NAS中权重共享思想的启发,我们提出了一个新的“代理任务”,它把模型的训练过程分为前期、后期两阶段。在前期,模型会在一个“共享策略”的增强下进行训练,得到“共享权重”;在后期我们才真正进行策略评估和搜索,模型会在当前正在被搜索的策略的增强下进行训练,得到最终的验证集性能并用于更新策略。
方法介绍
1.问题建模与搜索算法
自动数据增强旨在自动搜索能使验证集性能最好的数据增强策略。原始任务需要反复从头训练模型,并以最终验证集准确度作为评估指标。这是一个典型的双层优化问题(ω表示分类器模型的权重,θ表示自动数据增强策略的权重):
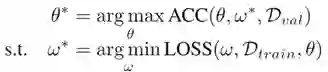
直接求解双层优化问题会非常耗时。而对于我们的分阶段代理任务,在早期我们会选取一个能够代表各种策略的共享策略,在其增强下训练一个共享的模型权重:
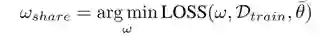
在后期我们则会让分类器模型继承早期的共享权重,进行fine-tune和策略搜索:
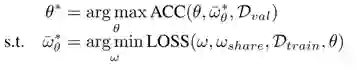
由于早期训练使用的策略是共享策略,与搜索过程完全解耦,因此共享权重只需训练一次即可用于后续的全部搜索,显著提升了搜索效率。我们将这一权重共享思想称为“Augmentation-wise Weight Sharing”。
于是当前问题转化为:如何选取具有代表性的共享策略?经过推导发现,一个均匀分布下的策略,可以使单独训练和共享训练的增强操作采样分布之间的KL散度最小。至此,我们便可以得到完整的AWS Auto-Aug搜索算法:
2.搜索空间与搜索策略
为了与先前工作进行更公平的对比,我们选择了与其几乎一致的搜索空间(我们甚至在搜索空间中去掉了更强大的增强操作:Cutout与Sample Pairing)。对于搜索策略,由于我们提出的方法是通用的,任何启发式搜索算法均适用。实验中我们发现PPO强化学习算法(也是Google AutoAug使用的算法)已经有了足够好的表现。
实验结果
1.表现对比
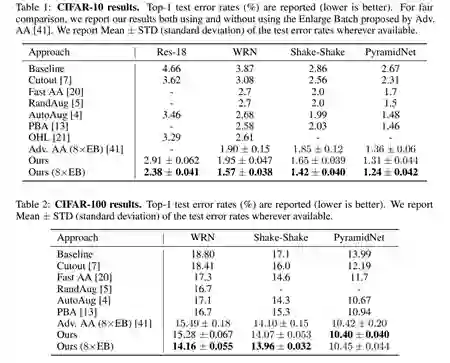
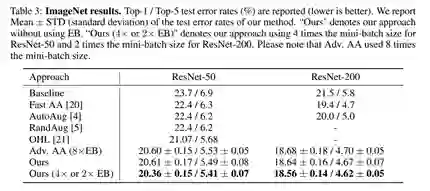
我们在3个最主流的图像分类数据集和4个主流模型上进了算法表现对比。结果如下,在各数据集、各模型上我们均取得了最优表现;尤其是在未使用额外数据的CIFAR-10上,在我们搜索得到的数据增强策略下,PyramidNet取得了新的SOTA性能(旧的SOTA性能为Adv. AA [2] 策略下的PyramidNet):
2.时间开销对比
我们以OHL AutoAug [3] 的时间开销为基准(1x),以WideResNet-28x10在CIFAR-10上使用Cutout的错误率为基准(0%),对比各方法的时间开销和相对误差降低如下。可见我们的方法在可接受的计算量内取得了很好的表现。
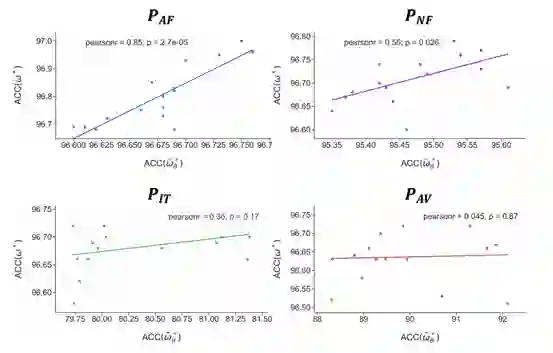
3.代理任务可靠性对比
为了验证我们所选择代理任务相比其他代理任务的高可靠性,我们计算了在搜索过程中取得的准确度和最终准确度的相关性,结果如图所示:
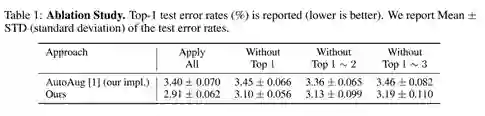
4.消融实验
为了验证我们搜索得到的策略的有效性,我们将我们的策略和Google AutoAug的策略中概率最高的增强操作逐个去除,并观察性能的变化。结果如下表所示,可见我们搜索得到的策略确实更有效。
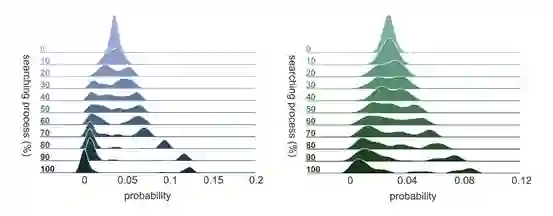
5.搜索过程展示
最后,我们还展示了我们的策略分布在整个搜索过程中的变化。如下图所示(左右分别对应CIFAR-10、ImageNet),增强操作在最初均为均匀分布(图中做了平滑);随着搜索进程推进,多数操作的概率开始趋向0,而为数不多的数个操作的概率则不断增大,体现出分化的过程。

结语
在这项工作中我们提出了一种利用权重共享思想的新型自动数据增强方法。该方法很好地解决了自动数据增强的评估效率与评估可靠性之间的矛盾问题,充足的实验结果也验证了其的高效性和有效性。最后,我们还期待这项工作中的现象或蕴含的思想能够对更多的超参数优化工作带来帮助和启发。如果您希望作进一步讨论,欢迎与我们联系:tiankeyu.00@gmail.com。
招聘信息
我们来自商汤研究院,主要专研于全生命周期的AutoML技术(Auto Aug、NAS、Auto Loss、Auto Sampler)和公司的通用检测模型(包括人脸、人脸人体、车辆结构化、视频分类、关键点等感知模型)等相关研究,组内工作多次被宣传,成果不但发表在各大会议上,更在公司产品中有落地应用。组内有海外教授担任相关技术顾问,GPU卡非常丰富,组员背景丰富。感兴趣的同学可以投递简历至sunming1@sensetime.com, 实习,校招,正式均可。期待能够长期实习/在检测等感知算法或者数学方面有突出的经历的正式小伙伴。
References
[1] Cubuk, Ekin D., et al. "Autoaugment: Learning augmentation policies from data." arXiv preprint arXiv:1805.09501 (2018).
[2] Zhang, Xinyu, et al. "Adversarial autoaugment." arXiv preprint arXiv:1912.11188 (2019).
[3] Lin, Chen, et al. "Online hyper-parameter learning for auto-augmentation strategy." Proceedings of the IEEE International Conference on Computer Vision. 2019.