点击上方“CVer”,选择加"星标"置顶
重磅干货,第一时间送达![]()
来自华为诺亚方舟实验室、清华大学和同济大学的研究人员提出了一种渐进剪枝的单阶段可微分架构搜索方法,能够显著提升可微分搜索算法的稳定性,并且允许在更加自由的搜索空间内进行探索,找到更性价比更高的网络结构。在CIFAR10数据集上,该方法只需要0.4个GPU天(单卡10小时)即可完成一次搜索,同时得到至少六个Pareto最优的网络结构,其中最小的一个能够以1.58M参数量达到97%的重训练精度,而以往达到相同精度的网络至少包含2.4M参数量。在ImageNet数据集上直接搜索时,该方法同样表现稳定,只需要1.7个GPU天(单卡40小时)即可完成搜索,是现有直接搜索ImageNet的方法中速度最快的,同时在移动设定(600M计算量)下达到了76%以上的重训练精度,是表现最好的可微分搜索方法之一。
值得一提的是,该论文被NeurIPS 2020以desk reject形式拒稿。组委会给出的模板化意见语焉不详。作者发信表达强烈不满后,依然只得到了PC模板化的回信。
现有的网络架构搜索算法,包括搜索空间设计和搜索算法设计,通常包含大量手工设计的规则。这些规则能让搜索算法更稳定,但却限制了。在这一工作中,我们尝试消除绝大部分手工设计的规则,从而允许算法在一个超大搜索空间(包含超过10160个网络架构)中进行搜索。在这样一个的搜索空间中,现有的可微分方法大多会因为搜索的不稳定性而失效,而我们提出两个主要的改进措施,即单阶段优化和渐进剪枝,很好地提升了搜索的稳定性。我们的算法名为GOLD-NAS,其中G表示渐进剪枝、OL表示单阶段优化、D表示可微分搜索。GOLD-NAS能够在一次搜索过程中通过渐进剪枝的方式,同时得到一系列不同复杂度、不同精度,却同为Pareto最优的网络架构。受益于自由度高的搜索空间,这些网络架构(从未被探索过)都能够在复杂度和精度之间达到更好的权衡。我们相信,我们提出的搜索空间和搜索策略,都为NAS领域指明了新的探索方向。
论文地址:
https://arxiv.org/abs/2007.03331
可微分网络架构搜索(DARTS [1])是2019年网络架构搜索领域最大的进步之一。该方法通过松弛化的网络架构建模,能够使得优化函数对于网络架构参数可微,从而将权重参数(即卷积参数等)和网络参数(即每种操作所占比例)整合到一个端到端的超网络优化过程中,实现了训练的极大加速。在过去的一年中,针对DARTS的改进方案层出不穷,其中代表性的工作包括P-DARTS [2]和PC-DARTS [3]等:它们都在一定程度上提升了DARTS的稳定性和可迁移性。时至今日,许多基于DARTS的方法都能够在CIFAR10甚至ImageNet上取得较高的精度,但是可微分搜索的三个基本问题依然没有获得解决:
第一,搜索空间极度受限。在DARTS的搜索空间上,所有normal和reduction单元都具有相同的结构,其中每个内部节点只能连接2个前置节点,而每条边上只能保留1个操作。这些约束都有助于提升搜索算法的稳定性,但也限制了空间的容量,使得搜索算法很难找到性价比更高的网络架构。更重要的是,这些约束使得搜索算法只需要一些简单的trick就能够取得较好的结果(如P-DARTS规定每个单元里有且仅有2个skip-connect),从而使得研究者很难判断一个搜索算法本身(除trick外)的质量。这些都限制了NAS领域的发展。
第二,两阶段优化算法具有天然的不稳定性。DARTS原文和一些后续工作[4,5,6]都提到过,DARTS的两阶段优化方法都建立在对Hessian矩阵的数学近似上,而这个近似产生的误差是不可控制的。因此,不论是改变搜索空间、调节搜索超参数、甚至仅仅是增加搜索代数,都有可能导致搜索算法的完全失效:[4,5,6]都报告DARTS搜索退化为全skip-connect的单元;[6]虽然从提出了一种更好的两阶段近似,但很难扩展到更大的搜索空间上。同时,两阶段优化也需要更多的计算资源。
第三,部署阶段的严重误差。可微分搜索算法在最后阶段进行的剪枝操作(有时也称为离散化)造成了超网络和子网络之间的优化误差,也就是说,一个优质的超网络在剪枝后不一定能够得到一个优质的子网络。现有的解决方案主要是搜索过程中有意地将操作权重推向两极[7,8]或者使用逐步剪枝[9],但受限于搜索空间(如要求所有单元具有相同结构),剪枝过程依然会对网络精度造成较大的波动。
总结来说,上述几个问题都影响了可微分搜索方法的稳定性和可扩展性,而且它们是环环相扣的。为此,我们提出一个新的框架,系统性地解决了上述问题。
本文以DARTS为基线方法,也沿用了其搜索空间。然而DARTS的搜索空间存在三个不甚合理的约束:
·所有normal单元(或者reduction单元)都具有相同的结构,不同阶段的单元只是具有不同的通道数——也就是说,整个网络架构只有两种不同的单元;
·每个单元中,每个内部节点必须且只能与2个前置节点连接;
·最终保留的每条边上,有且仅有1个操作,也就是说,不同操作是互斥的。
这些约束限制了搜索空间的自由度,使得DARTS无法找到性价比更高的网络架构。本文提出一种新的搜索空间,释放了上述约束,使得找到如下的网络架构成为可能:
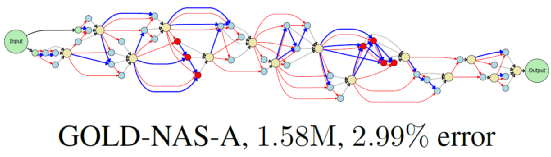
上述网络能够以1.58M参数在CIFAR10上达到97%以上的分类精度,而原始搜索空间达到相同精度至少需要2.5M参数。这说明搜索空间的开放能够提升网络架构的性价比——前提是搜索算法能够稳定运行。
进一步地,我们也提出对于搜索空间设计的观点。我们认为,一个适合NAS研究的搜索空间必须满足两个基本性质。第一,它能够覆盖一大类手工设计和自动搜索的网络架构,如直链结构、ResNet系列、MobileNet系列,甚至包括一些常见的模块如SE等。第二,随机搜索算法需要花费大量时间才能找到好架构,而人工经验几乎无法起到作用,从而能够促进搜索算法本身的演进。我们提出的搜索空间虽然相比于现有方法已经有了进步,但依然无法达标:既不能得出直链、ResNet和MobileNet结构,且随机搜索24次就能在CIFAR10数据集上达到平均96%以上的精度。因此,搜索空间依然有很大的改进空间。
为了在新空间中取得稳定的搜索效果,我们使用单阶段优化方法。
我们首先回答一个问题:为什么两阶段优化策略会被DARTS使用,也被一系列方法沿用?我们认为,主要的问题是网络参数和架构参数的不平衡特性。此处,网络参数指的是卷积核等需要在重训练过程中优化的参数(通常以ω表示),而架构参数指的是松弛化后不同算子的权重(通常以α表示)。值得注意的是,ω和α的体量存在巨大差异:ω通常是百万级别,而α通常是百或千级别。这就决定了在超网络优化过程中,更新ω和α能够达到显著不同的效果:对ω的优化往往能够使得训练精度快速上升,但是最终对搜索有用的是对α的优化。这样的不一致性就决定了,如果将ω和α的优化放在同一阶段进行,就会导致超网络倾向于优化ω而忽略了优化α。在极端情况下,即使超网络只优化ω而不优化α,也能在短时间内达到很高的训练精度,但是这对于网络架构搜索毫无作用。为了避免这一现象,DARTS的作者提出了两阶段优化方法,将训练集划分为两个部分,一部分用于优化ω(固定α),另一部分用于优化α(固定ω)。
然而,这样的优化过程产生了很大的数学负担。在第二阶段中,计算超网络关于α的梯度需要进行一系列的数学假设和近似。这些假设通常无法保证,而关于Hessian矩阵的近似甚至无法确保优化方向的正确性。这些分析都详细记录在我们的前置工作[6]中,此处不再赘述。一个简单的结论是:两阶段优化方法无法保证搜索稳定性,特别是随着搜索空间的增大,优化特性会愈加难以控制。
于是,我们回到单阶段优化,尝试解决超网络趋向于迅速拟合ω的问题。从本质上说,超网络偏向优化ω是一种过拟合现象,而各种通用的正则化方法都能够缓解这种现象。在实验中,我们测试了自动数据扩增(AA,仅在搜索阶段使用)、加入辅助损失函数(auxiliary loss)、L2正则等方法,发现这些方法都能够有效地减慢拟合ω的速度。特别地,当搜索直接在ImageNet数据集上进行时,由于训练数据量和难度的增加,甚至在不使用任何正则化的情况下,迅速拟合ω的现象都不会出现。在CIFAR10数据集的搜索阶段,使用自动数据扩增和Cutout作为正则化方法,单阶段优化策略能够在原空间上取得97.20%精度的网络架构,与两阶段优化方法持平。
今后,我们建议将带正则化的单阶段优化作为标准方法,用于可微分网络架构搜索。
3.3 渐进剪枝:在新空间中达到精度和复杂度的平衡
在新空间中,除了使用单阶段优化,还必须对超网络进行一定的修改,包括将DARTS中使用的操作间softmax归一化改为对每个操作的sigmoid归一化,以确保每个操作能够独立地存在于最终的网络架构中[7]。修改后的超网络存在一个问题:由于操作之间不存在竞争机制,在超网络训练过程中,最好的策略就是简单地保留所有操作——但是这种结论对于网络架构搜索并无益处。换句话说,与原空间自带操作间竞争不同,新空间需要引入额外的正则项来保证得到高性价比的网络架构。我们将在实验中看到,新的机制能够更好地在网络架构的精度和复杂度之间取得平衡,也能够提升搜索算法的稳定性。
具体地说,我们针对网络架构参数α引入一个正则化项,用于估计当前网络架构的复杂度。在本文中,我们使用预估的FLOPs作为正则化项,而这一项在任何时刻对α可微。整体优化函数被写成Lcls(ω,α)+λ∙FLOPs(α),其中前者是分类损失函数,后者是由平衡系数λ控制的复杂度损失函数。搜索初始阶段,λ设定为0,超网络能够在不考虑复杂度的情况下优化训练精度。在一定训练阶段过后,λ逐渐增大,破使超网络在精度和复杂度之间取得平衡,从而将某些操作对应的α值降低。当某些边的α值(准确地说,是sigmoid(α)值)降低到一定的程度(如0.05一下),就将这条边从超网络中去除(即执行剪枝操作),直到保留下的超网络满足特定要求(如FLOPs降低至定值以下)为止。搜索的伪代码如下图所示:
这种渐进剪枝算法主要有两个好处。第一,每次剪枝只会影响到一条或者少数几条边,因而对于整个超网络的精度不会产生显著的扰动。这一改进大大缓解了超网络的优化误差,不致发生“优质超网络不对应于优质子网络”的问题。第二,渐进剪枝的过程中得到的每一个中间结果,都是Pareto最优的(对应于精度和复杂度间的某种平衡)。也就是说,每次搜索都能产生一系列在复杂度下最优的网络架构。
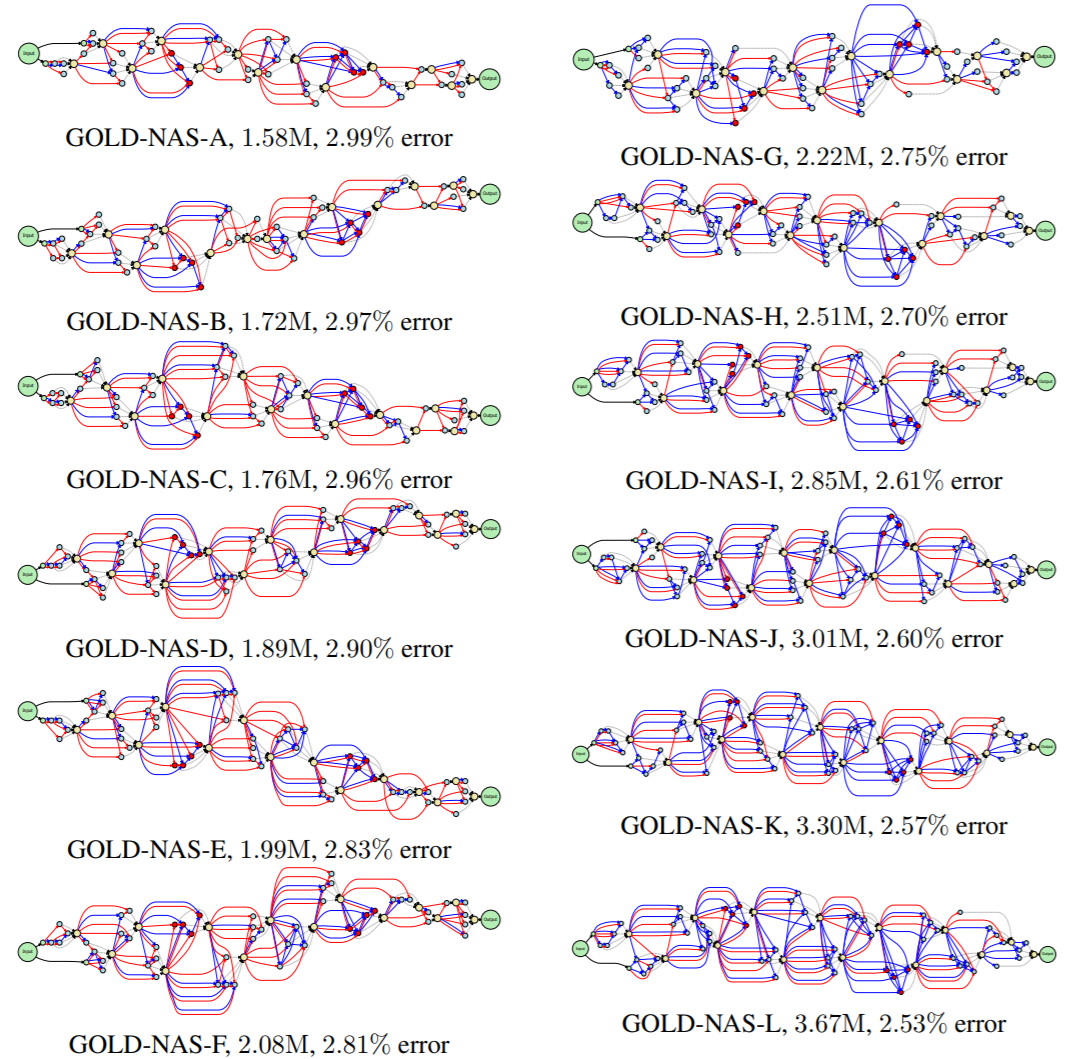
在CIFAR10数据集上,我们使用不同的正则化强度(更强的正则化能够找到更轻量的网络结构)进行了两次搜索,得到的结果如下图所示。
![]()
图3 GOLD-NAS在两次CIFAR10搜索过程中找到的一系列网络架构,其中左侧对应FLOPs约束较强时的架构,右侧对应FLOPs约束较弱时的架构。注意,左侧和右侧的六个架构是在一次搜索过程中先后得到的(从大到小),均为Pareto最优。红边表示skip-connect,蓝边表示sep-conv-3x3,黑色虚线表示concatenation。
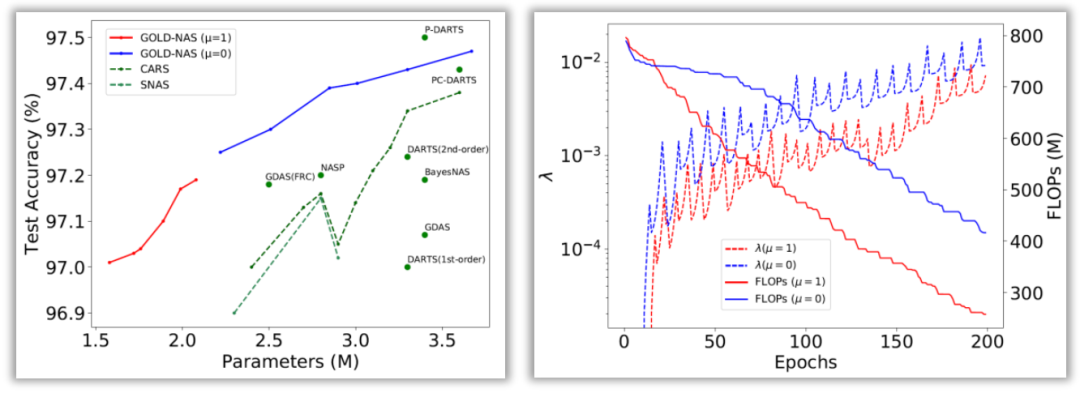
在下图中,我们针对搜索过程进行了分析。我们能够看到,在FLOPs约束较强时,我们的方法在CIFAR10上得到了一系列轻量级模型,其中最小的一个(即GOLD-NAS-A)只使用1.58M参数就在CIFAR10上达到97.01%的精度,是已知达到97%以上精度的模型中最小的一个。从这个模型的架构上看,靠近输入输出的单元都被剪去了大量的操作,说明中层特征计算对于CIFAR10 最为有利。而正是经过扩展的搜索空间和稳定的搜索算法,使得找到这些性价比更高的网络架构成为可能。
![]()
图4 对两次搜索过程的诊断(红线对应FLOPs约束较强时的搜索过程,蓝线对应FLOPs约束较弱时的架构:左侧表明搜索出的结构达到了比现有方法更好的精度-复杂度平衡;右侧展示了搜索网络的精度随着平衡系数λ的变化情况
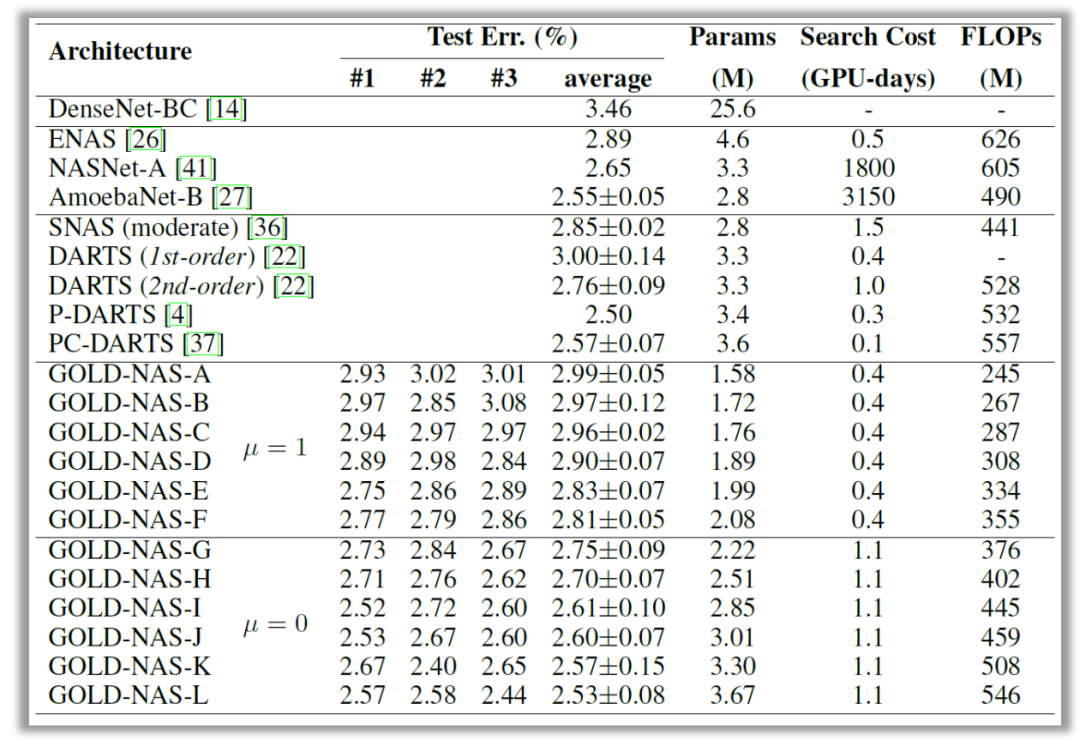
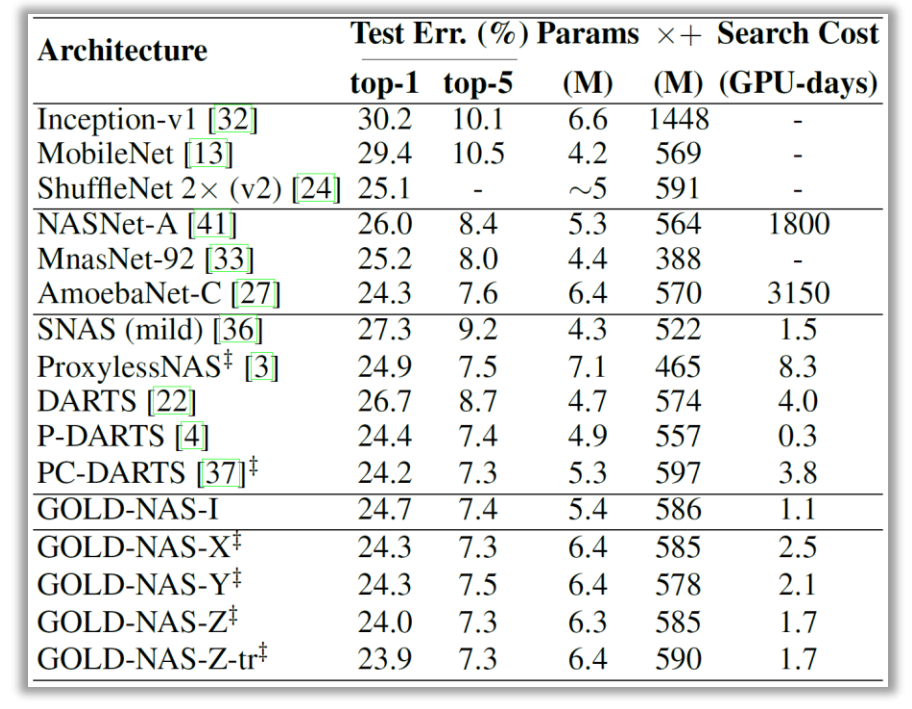
在CIFAR10上与其他方法的对比如下表所示。我们的方法既能得到性价比极高的轻量网络,也能在重量网络上达到接近业界最佳的性能。所有训练方法均使用标准方式:600个epoch,不带自动数据扩增(AA)。值得一提的是,我们的方法对自动数据扩增非常友好:在使用AA的情况下,最轻量级(1.58M)的网络架构也能在重训练中产生接近98%的准确率。
![]()
我们的方法还能够轻松地迁移到ImageNet上。由于ImageNet的比较需要在移动设定下进行(FLOPs不超过600M),我们的方法在每次搜索过程中能够达到一个恰好低于600M的模型。为了得到不同的模型,我们使用了不同的基础通道数(44、46、48)进行搜索,得到了三组模型(GOLD-NAS-X/Y/Z),都取得了很好的重训练精度(76.0%左右)。同时,我们迁移了一个CIFAR10上搜索的中等大小的网络架构(GOLD-NAS-I),也取得了较高的精度。
![]()
本文提出了一套新的框架,包括扩充的搜索空间、单阶段优化方法和渐进剪枝算法,从而系统性地解决了可微分架构搜索算法中存在的若干问题。鉴于这一算法的灵活性和稳定性,我们相信它能够为未来的网络架构搜索提供新的思路,甚至成为新的基线算法。未来,我们还将通过引入硬件约束(如latency约束[10]),得到更适合实际部署的网络架构搜索算法。
参考文献
[1] Hanxiao Liu, Karen Simonyan, and Yiming Yang. DARTS: Differentiable architecture search. In ICLR, 2019.
[2] Xin Chen, Lingxi Xie, Jun Wu, and Qi Tian. Progressive differentiable architecture search: Bridging the depth gap between search and evaluation. In ICCV, 2019.
[3] Yuhui Xu, Lingxi Xie, Xiaopeng Zhang, Xin Chen, Guo-Jun Qi, and Qi Tian. PC-DARTS: Partial channel connections for memory-efficient differentiable architecture search. In ICLR, 2020.
[4] Arber Zela, Thomas Elsken, Tonmoy Saikia, Yassine Marrakchi, Thomas Brox, and Frank Hutter. Understanding and robustifying differentiable architecture search. In ICLR, 2020.
[5] Hanwen Liang, Shifeng Zhang, Jiacheng Sun, Xingqiu He, Weiran Huang, Kechen Zhuang, and Zhenguo Li. Darts+: Improved differentiable architecture search with early stopping. In arXiv:1909.06035, 2019.
[6] Kaifeng Bi, Changping Hu, Lingxi Xie, Xin Chen, Longhui Wei, and Qi Tian. Stabilizing DARTS with amended gradient estimation on architectural parameters. In arXiv:1910.11831, 2019.
[7] Xiangxiang Chu, Tianbao Zhou, Bo Zhang, and Jixiang Li. Fair DARTS: Eliminating unfair advantages in differentiable architecture search. In ECCV, 2020.
[8] Yunjie Tian, Chang Liu, Lingxi Xie, Jianbin Jiao, and Qixiang Ye. Discretization-Aware Architecture Search. In arXiv:2007.03154, 2020.
[9] Guohao Li, Guocheng Qian, Itzel C. Delgadillo, Matthias Muller, Ali Thabet, and Bernard Ghanem. SGAS: Sequential greedy architecture search. In CVPR, 2020.
[10] Yuhui Xu, Lingxi Xie, Xiaopeng Zhang, Xin Chen, Bowen Shi, Qi Tian, and Hongkai Xiong. Latency-aware differentiable neural architecture search. In arXiv:2001.06392, 2020.
下载
在CVer公众号后台回复:GOLD-NAS,即可下载本论文
CVer-AutoML&NAS 微信交流群已成立
扫码添加CVer助手,可申请加入CVer-AutoML&NAS 微信交流群,目前已汇集400人!互相交流,一起进步!
同时也可申请加入CVer大群和细分方向技术群,细分方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、PyTorch和TensorFlow等群。
一定要备注:研究方向+地点+学校/公司+昵称(如NAS+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群
![]()
▲长按加群
![]()
▲长按关注我们
整理不易,请给CVer点赞和在看!![]()