深度学习从入门到进阶的12个经典问题及解答

更多干货内容请关注微信公众号“AI 前线”,(ID:ai-front)
即使对于老手而言,深度学习仍然是一种神秘的艺术。因为人们通常在大型数据集上进行复杂的实验,这就掩盖了数据集、超参数和性能之间的基本关系,人们无法窥一斑而知全豹。
本文的目标是通过在小型数据集上运行非常简单的实验,来获得深度神经网络的一些基本直觉。这些实验有助于人们理解通常在大型数据集上发生的趋势。这些实验被设计为“原子”的,因为它们试图以一种可控的方式来分析深度学习的基本方面。此外,这些实验并不需要专门的硬件,它们只需运行几分钟,不需要 GPU。运行时间是基于只使用 CPU 的机器测得的。
所有这些实验都是用 Python 编写的,使用了 tensorflow 和 sklearn 库,但鉴于篇幅,本文中大部分代码都被抽象出来,以便使实验更容易运行。请参阅 Github repo 的完整代码 (https://github.com/abidlabs/AtomsOfDeepLearning/ )。
通用逼近性定理指出,一个具有单个隐藏层和标准激活函数的简单前馈神经网络(即多层感知器),如果隐藏层具有足够数量的单位,它就可以近似任何连续函数。让我们在实践中看一下,看看需要多少单位来近似一些特定函数。
方法:我们将在 50 个数据点 (x,y) 上训练一个 1 层神经网络,这些数据点从域 [-1,1] 上的以下函数中绘制,所得拟合的均方误差(mean square error,MSE)。我们将尝试以下函数(你可随时通过更改以下代码来尝试自己的函数。):
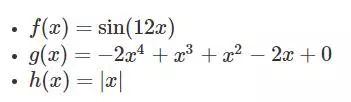
假设: 随着隐藏层中单位的数量增加,所得拟合的正确率(Accuracy)将会增加(误差将会减少)。
运行实验所需的时间: 91.595 s
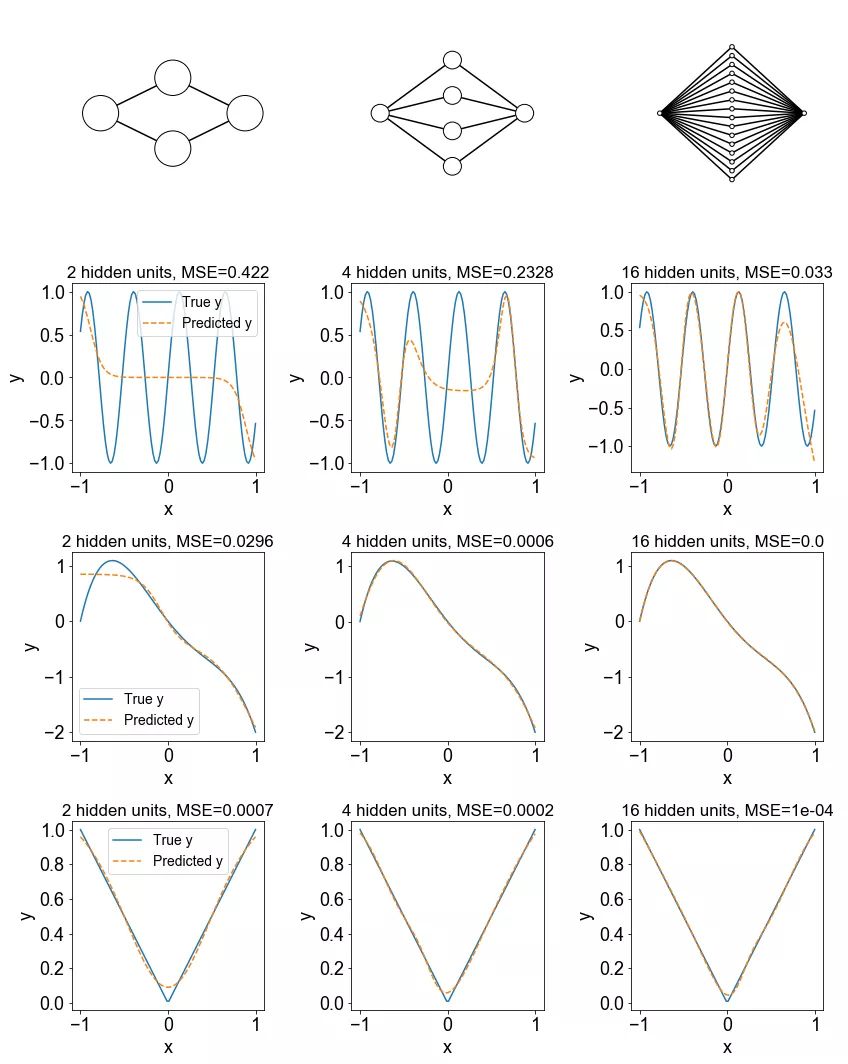
结论: 随着隐藏单位数量的增加,训练数据的逼近误差一般会减小。
讨论: 尽管通用逼近定理指出,具有足够参数的神经网络可以近似一个真实的分类 / 回归函数,但它并没有说明这些参数是否可以通过随机梯度下降这样的过程来习得。另外,你可能想知道我们是否可以从理论上计算出需要多少神经元才能很好地近似给定的函数。你可参阅论文《NEURAL NETWORKS FOR OPTIMAL APPROXIMATION OFSMOOTH AND ANALYTIC FUNCTIONS》对此的一些讨论。
论文地址:
https://pdfs.semanticscholar.org/694a/d455c119c0d07036792b80abbf5488a9a4ca.pdf
在实践中,更深的多层感知器(具有超过一个隐藏层)在许多感兴趣的任务上的表现,在很大程度上都胜过浅层感知器。为什么会出现这种情况呢?有人认为,更深的神经网络仅需更少的参数就可以表达许多重要的函数类。理论上已经表明,表达简单的径向函数和组合函数需要使用浅层网络的指数级大量参数。但深度神经网络则不然。剧透警告:我打算用实验来验证这些论文,但我不能这样做(这并不会使论文的结果无效——仅仅因为存在一组神经网络参数,并不意味着它们可以通过随机梯度下降来轻松习得)。我唯一能做的就是,某种程度上可靠地再现来自论文《Representation Benefits of Deep Feedforward Networks》的唯一结果,这篇论文提出了一系列困难的分类问题,这些问题对更深层的神经网络而言更容易。
Representation Benefits of Deep Feedforward Networks 论文地址:https://arxiv.org/pdf/1509.08101.pdf
简单径向函数论文:https://arxiv.org/pdf/1512.03965.pdf
组合函数论文:https://arxiv.org/pdf/1603.00988.pdf
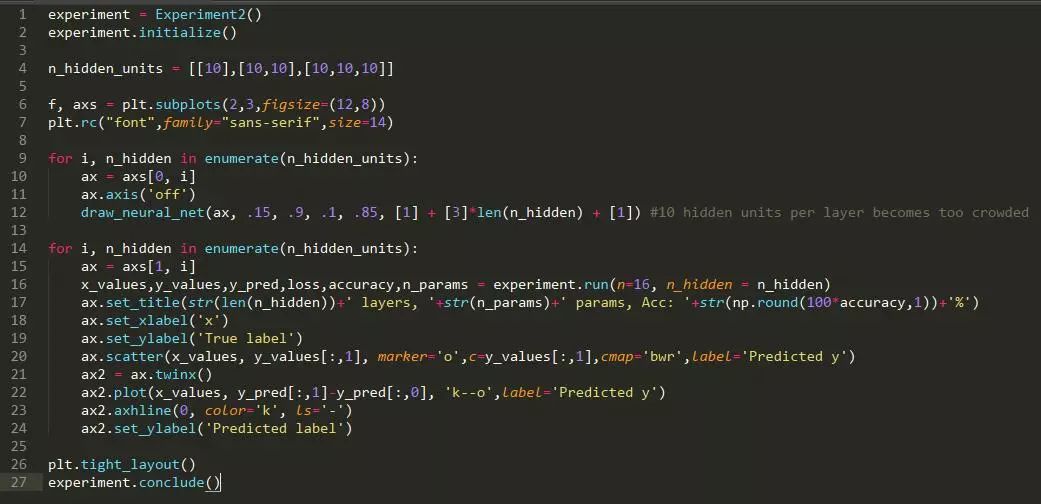
方法: 该数据集由沿着 x 轴的 16 个等距点组成,每对相邻点都属于相反的类。一种特殊类型的深度神经网络(一种跨层共享权重的神经网络)具有固定数量(152)的参数,但测试了层的不同数量。
假设: 随着具有固定数量参数的神经网络中层数的增加,困难的分类问题的正确率将得到提高。
运行实验所需的时间: 28.688 s
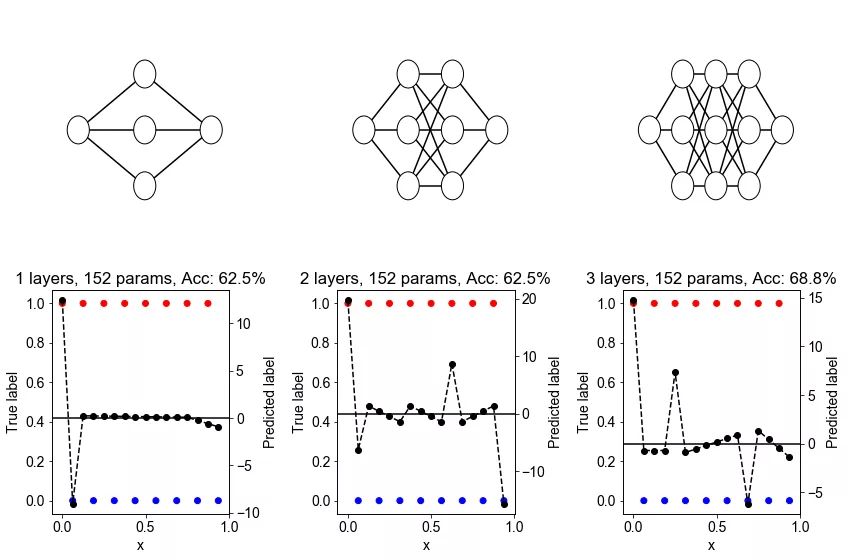
此处,红点和蓝点代表属于不同类别的点。黑色的虚线表示最接近神经网络学习的训练数据近似值(若神经网络分配的分数大于零,则被预测为红点;否则,被预测为蓝点)。零线显示为黑色。
结论: 在大多实验中,正确率随深度的增加而增加。
讨论: 似乎更深的层允许从输入到输出的学习到的函数出现更多“急弯”。这似乎跟神经网络的轨迹长度有关(即衡量输入沿着固定长度的一维路径变化时,神经网络的输出量是多少)。
轨迹长度论文:https://arxiv.org/pdf/1606.05336.pdf
深度学习和大数据密切相关;通常认为,当数据集的规模大到足够克服过拟合时,深度学习只会比其他技术(如浅层神经网络和随机森林)更有效,并更有利于增强深层网络的表达性。我们在一个非常简单的数据集上进行研究,这个数据集由高斯样本混合而成。
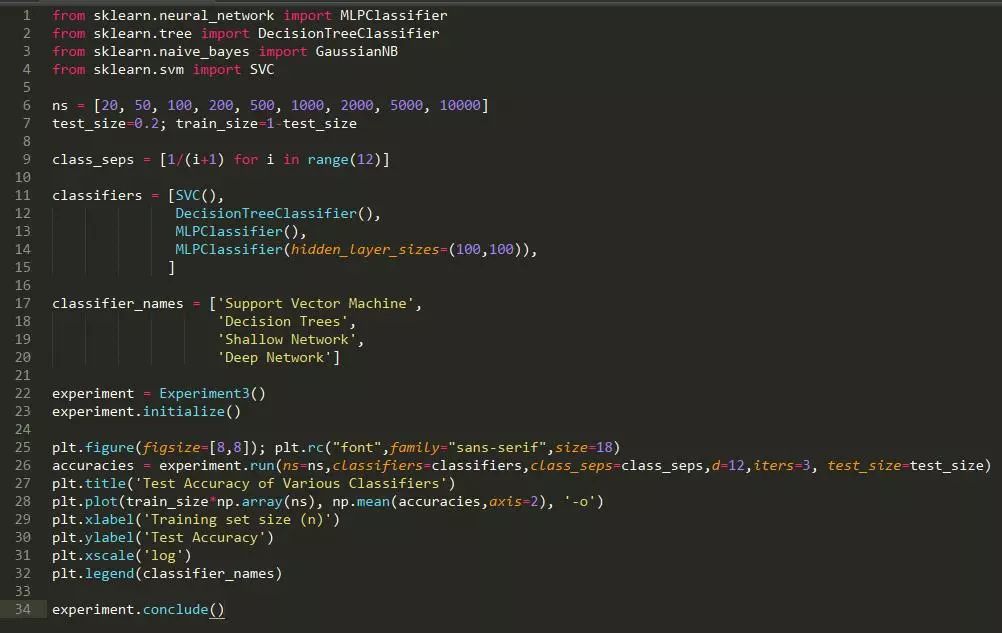
方法: 数据集由两个 12 维的高斯混合而成,每个高斯生成属于一个类的数据。两个高斯具有相同的协方差矩阵,但也意味着在第 i 个维度上有 1/i1/i 单位。这个想法是基于:有一些维度,允许模型很容易区分不同的类,而其他维度则更为困难,但对区别能力还是有用的。
假设: 随着数据集大小的增加,所有技术方法的测试正确率都会提高,但深度模型的正确率会比非深度模型的正确率要高。我们进一步预计非深度学习技术的正确率将更快地饱和。
运行实验所需的时间: 138.239 s
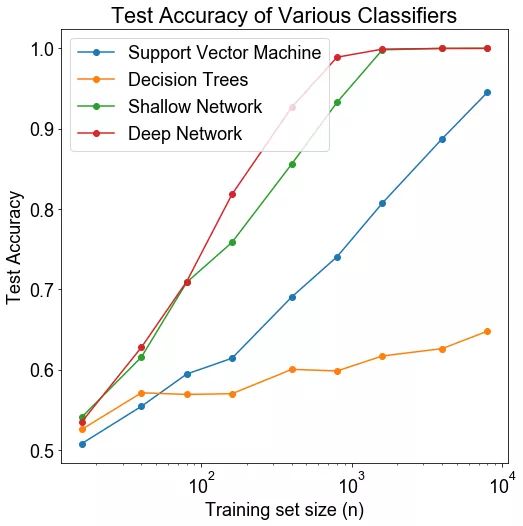
结论: 神经网络在数据集大小方面上表现始终优于 SVM 和随机森林。随着数据集大小的增加,性能上的差距也随之增加,至少在神经网络的正确率开始饱和之前,这表明神经网络更有效地利用了不断增加的数据集。然而,如果有足够的数据,即使是 SVM 也会有可观的正确率。深度网络比浅层网络的表现更好。
讨论: 虽然增加的数据集大小确实会像我们预计的那样有利于神经网络。但有趣的是,在相对较小的数据集上,神经网络已经比其他技术表现得更好。似乎 2 层网络并没有显著的过拟合,即使我们预计某些特征(如 6-12 特征,信号水平低)导致网络过拟合。同样有趣的是,SVM 看上去似乎有足够的数据来接近于 1.0。
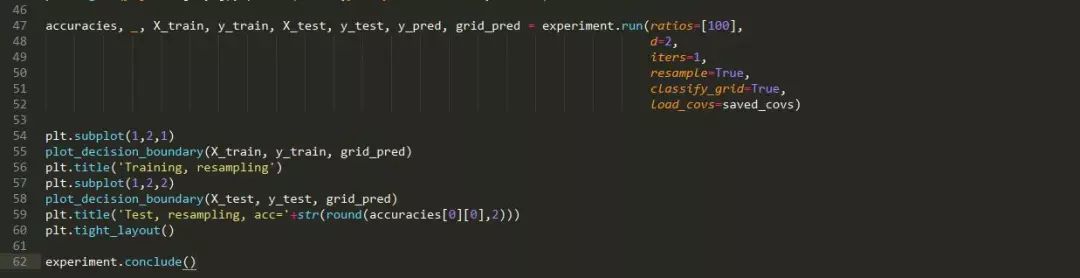
当数据集不平衡时(如一个类的样本比另一个类还多),那么神经网络可能就无法学会如何区分这些类。在这个实验中,我们探讨这一情况是否存在。同时我们还探讨了过采样是否可以减轻问题带来的影响,这是一种流行的补救措施,该措施使用少数类中抽样替换的样本。
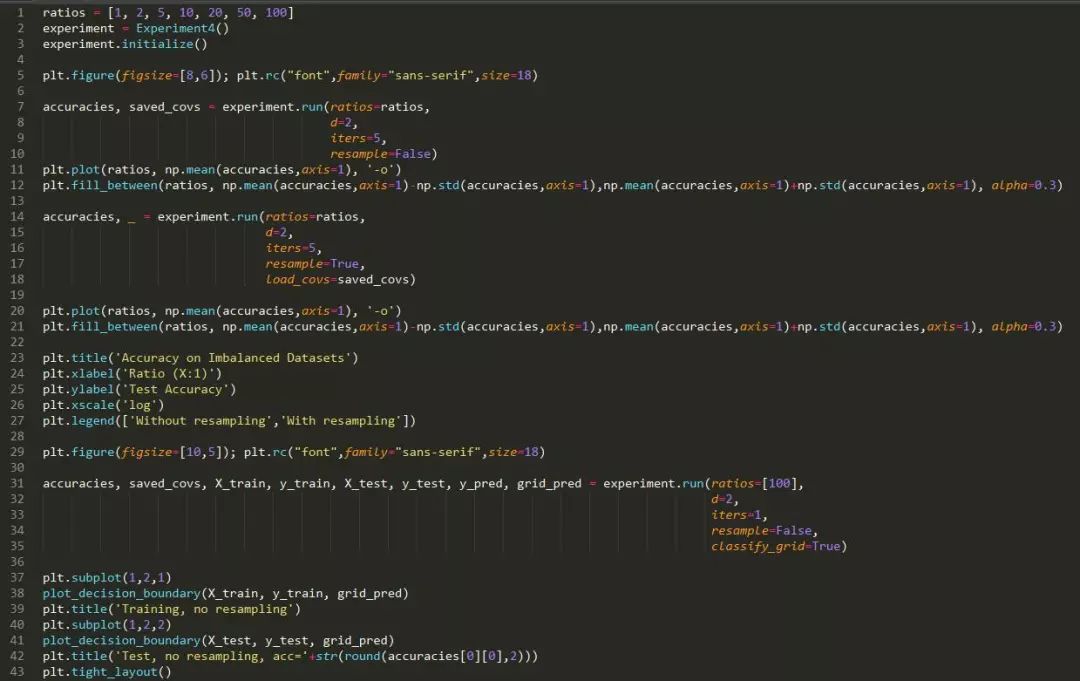
方法:我们生成两个二维的结果(结果未在这里显示,表明相同的结果适用于更高维)高斯,每个产生属于一个类别的数据。两个高斯具有相同的协方差矩阵,但它们的意思是在第 i 个维度上相距 1/i1/i 单位。每个训练数据集由 1,200 个数据点组成,但我们将类别不平衡从 1:1 变为 1:99。测试数据集以 1:1 的比例保持固定,以便于性能比较,并由 300 个点组成。我们还会在每种情况下显示决策边界。
假设:我们预计测试正确率会随着类别不平衡的增加而降低,但我们预计过采样可以缓解这个问题。
运行实验所需的时间: 392.157 s
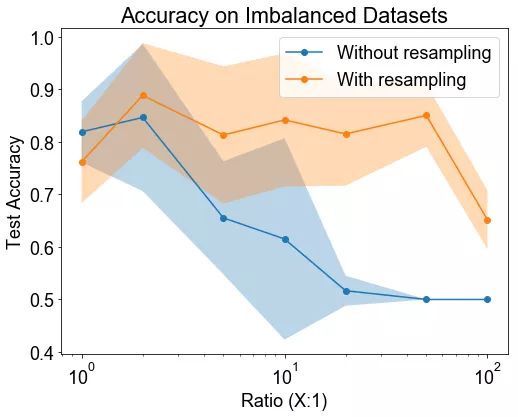
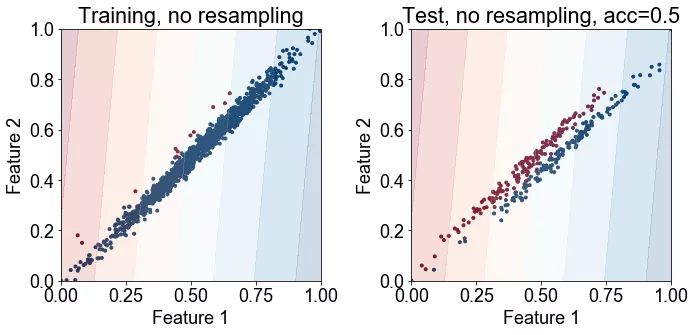
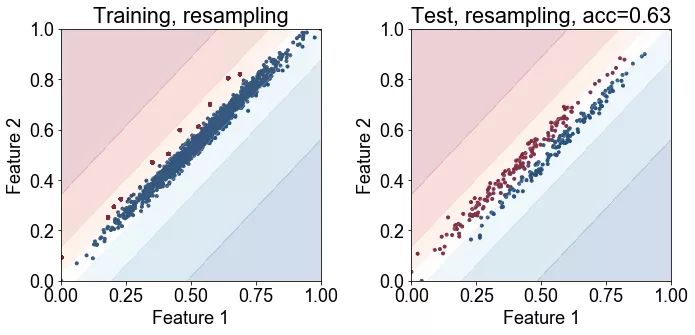
最下面的四张图显示了连同训练点(左)或测试点(右)绘制的决策边界的数量。第一行显示没有重采样法的结果,底部显示了使用重采样法的结果。
结论: 研究结果表明,类的不平衡无疑地降低了分类的正确率。重采样法可以显著提高性能。
讨论: 重采样法对提高分类正确率有显著的影响,这可能有点让人惊讶了,因为它并没有将分类器展示少数类中的新训练的样本。但该图显示,重采样法足以“助推(nudge)”或将决策边界推向正确的方向。在重采样法不是有效的情况下,那么可能需要复合方式来合成新的训练样本,以提高正确率。
相关论文地址:http://www.jair.org/media/953/live-953-2037-jair.pdf
具有许多参数的神经网络具有记忆大量训练样本的能力。那么,神经网络是仅仅记忆训练样本(然后简单地根据最相似的训练点对测试点进行分类),还是它们实际上是在提取模式并进行归纳?这有什么不同吗?人们认为存在不同之处的一个原因是,神经网络学习随机分配标签不同于它学习重复标签的速度。这是 Arpit 等人在论文中使用的策略之一。让我们看看是否有所区别?
相关论文地址:https://arxiv.org/pdf/1706.05394.pdf
方法: 首先我们生成一个 6 维高斯混合,并随机分配它们的标签。我们测量训练数据的正确率,以增加数据集的大小,了解神经网络的记忆能力。然后,我们选择一个神经网络能力范围之内的数据集大小,来记忆并观察训练过程中神经网络与真实标签之间是否存在本质上的差异。特别是,我们观察每个轮数的正确率度,来确定神经网络是真正学到真正的标签,还是随机标签。
假设: 我们预计,对随机标签而言,训练应该耗费更长的时间。而真正标签则不然。
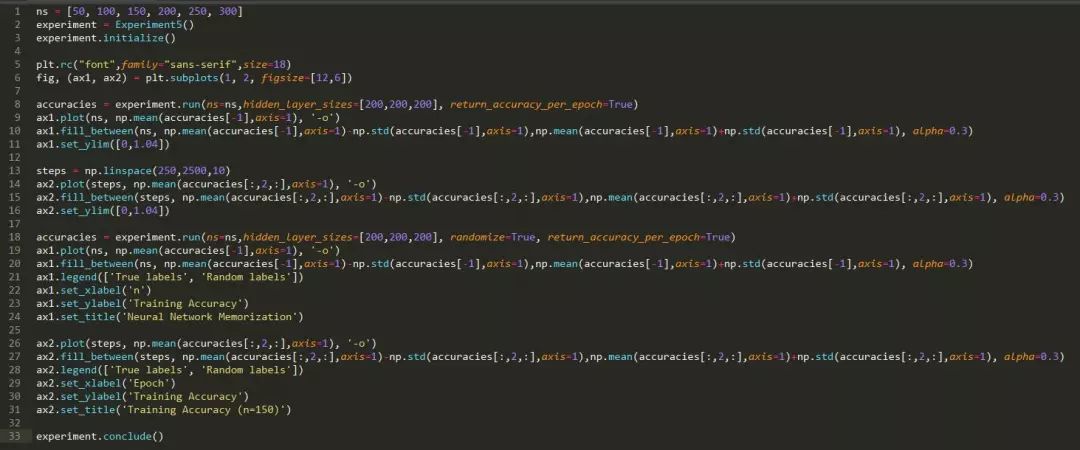
运行实验所需的时间: 432.275 s
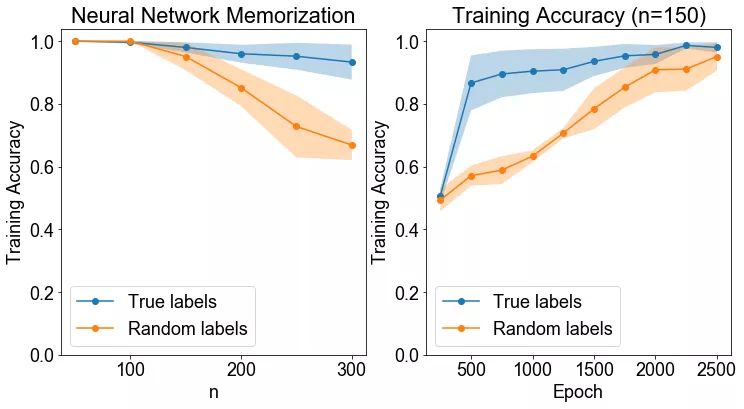
结论: 神经网络的记忆能力约为 150 个训练点。但即便如此,神经网络也需要更长的时间来学习随机标签,而不是真实值(ground truth)标签。
讨论: 这个结果并不令人感到意外。我们希望真正的标签能够更快的学到,如果一个神经网络学会正确地分类一个特定的数据点时,它也将学会分类其他类似的数据点——如果标签是有意义的,但前提它们不是随机的!
当处理非常高维的数据时,神经网络可能难以学习正确的分类边界。在这些情况下,可以考虑在将数据传递到神经网络之前进行无监督的降维。这做法提供的是帮助还是摧毁呢?
方法: 我们生成两个 10 维高斯混合。高斯具有相同的协方差矩阵,但在每个维度上都有一个由 1 隔开的均值。然后,我们在数据中添加“虚拟维度”,这些特征对于两种类型的高斯都是非常低的随机值,因此对分类来说没有用处。然后,我们将结果数据乘以一个随机旋转矩阵来混淆虚拟维度。小型数据集大小 (n=100) 使神经网络难以学习分类边界。因此,我们将数据 PCA 为更小的维数,并查看分类正确率是否提高。
假设: 我们预计 PCA 将会有所帮助,因为变异最多的方向(可能)与最有利于分类的方向相一致。
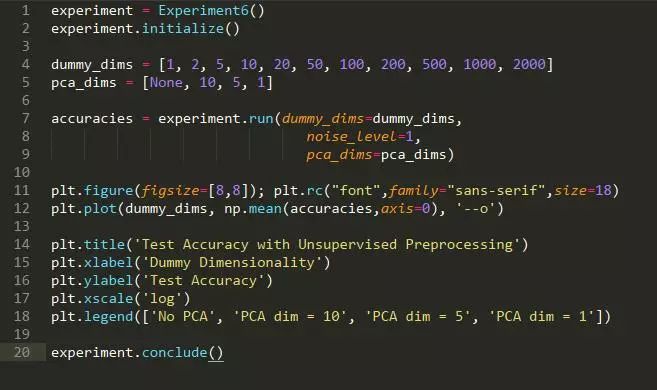
运行实验所需的时间: 182.938 s
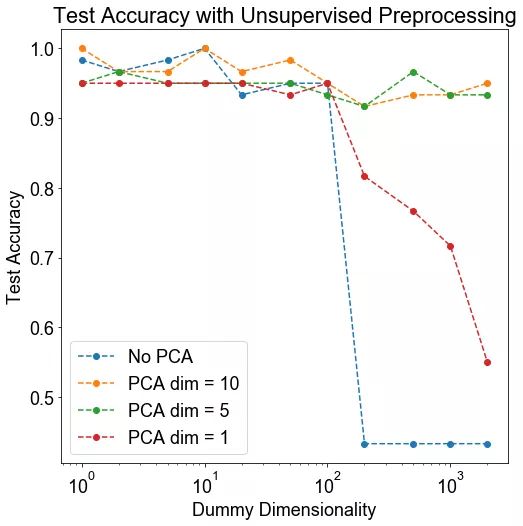
结论: 当维度非常大时,无监督的 PCA 步骤可以显著改善下游分类。
讨论: 我们观察到一个有趣的阈值行为。当维数超过 100 时(有趣的是,这数字是数据集中数据点的数量——这值得进一步探讨),分类的质量会有显著的下降。在这些情况下,5~10 维的 PCA 可显著地改善下游分类。
在通过具有超出典型 ReLU() 和 tanh() 的特殊激活函数的神经网络获得小幅提高的研究,已有多篇论文报道。我们并非试图开发专门的激活函数,而是简单地询问它是否可能在神经网络中使用任何旧的非线性函数?
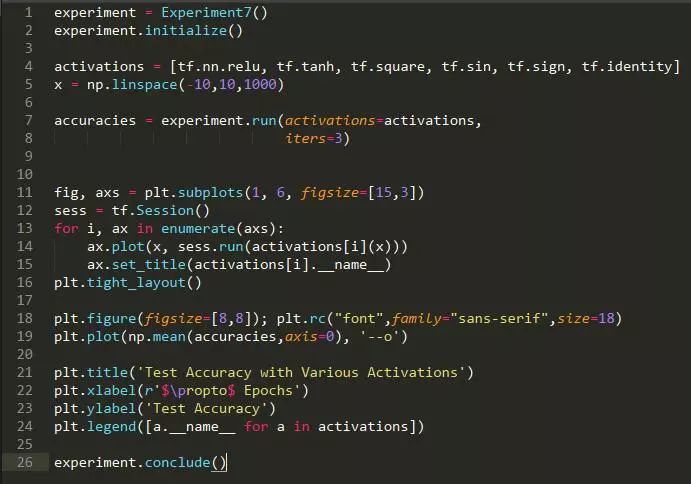
方法: 我们生成著名的二维卫星数据集,并训练一个具有两个隐藏层的神经网络来学习对数据集进行分类。我们尝试了六种不同的激活函数。
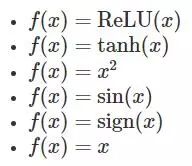
假设: 我们预计恒等函数执行很差(因为直到最后一个 softmax 层,网络仍然保持相当的线性)。我们可能会进一步期望标准的激活函数能够发挥最好的效果。
运行实验所需的时间: 22.745 s

结论: 除去 sign(x) 外,,所有的非线性激活函数对分类任务都是非常有效的。
讨论: 结果有些令人吃惊,因为所有函数都同样有效。事实上,像 x2 这样的对称激活函数表现得和 ReLUs 一样好!从这个实验中,我们应该谨慎地推断出太多的原因。首先,这是一个相对较浅的神经网络。对这种网络有好处的激活函数可能与那些对深度网络有好处的函数非常不同。此外,这个任务可能过于简单,即使几乎完全线性的神经网络 f(x)=x 也能达到约 88% 的正确率。
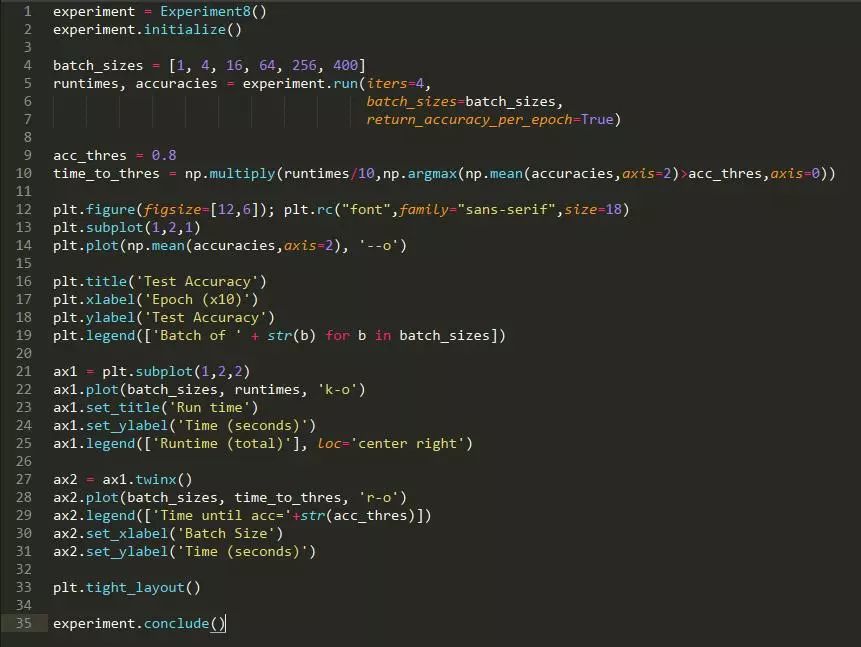
方法: 我们生成两个 12 维高斯混合。高斯具有相同的协方差矩阵,但在每个维度上都有一个由 1 隔开的均值。该数据集由 500 个高斯组成,其中 400 个用于训练,100 个用于测试。我们在这个数据集上训练一个神经网络,使用不同的批大小,从 1 到 400。我们测量了之后的正确率。
假设: 我们期望较大的批大小会增加正确率(较少的噪声梯度更新),在一定程度上,测试的正确率将会下降。我们预计随着批大小的增加,运行时间应有所下降。
运行实验所需的时间: 293.145 s
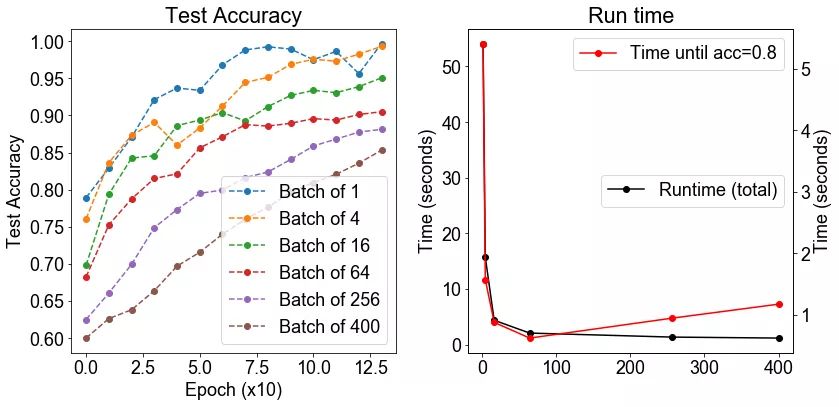
结论: 正如我们预期那样,运行时间确实随着批大小的增加而下降。然而,这导致了测试正确率的妥协,因为测试正确率随着批大小的增加而单调递减。
讨论: 这很有趣,但这与普遍的观点不一致,严格来说,即中等规模的批大小更适用于训练。这可能是由于我们没有调整不同批大小的学习率。因为更大的批大小运行速度更快。总体而言,对批大小的最佳折衷似乎是为 64 的批大小。
相关论文:https://arxiv.org/abs/1508.02788
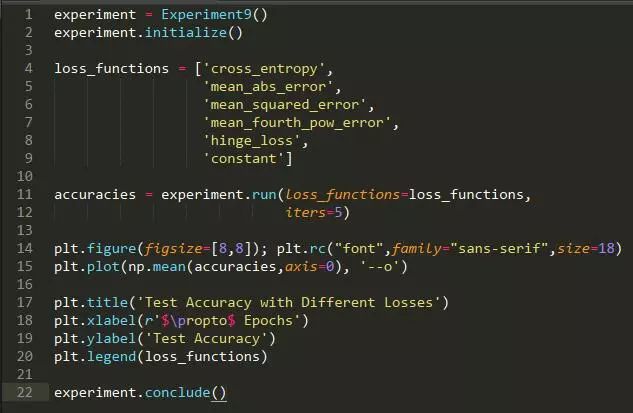
对于分类任务,通常使用交叉熵损失函数。如果我们像通常在回归任务中那样使用均方差,结果会怎么样?我们选择哪一个会很重要么?
方法: 我们生成两个 12 维高斯混合。高斯具有相同的协方差矩阵,但在每个维度上都有一个由 1 隔开的均值。该数据集由 500 个高斯组成,其中 400 个用于训练,100 个用于测试。我们使用几种不同的函数在这个数据集上训练一个神经网络,以确定最终正确率是否存在系统差异。作为阴性对照,包括一个不变的损失函数。
假设: 我们预计交叉熵损失函数作为分类任务的标准损失函数,表现最好,同时我们预计其他损失函数表现不佳。
运行实验所需的时间: 36.652 s
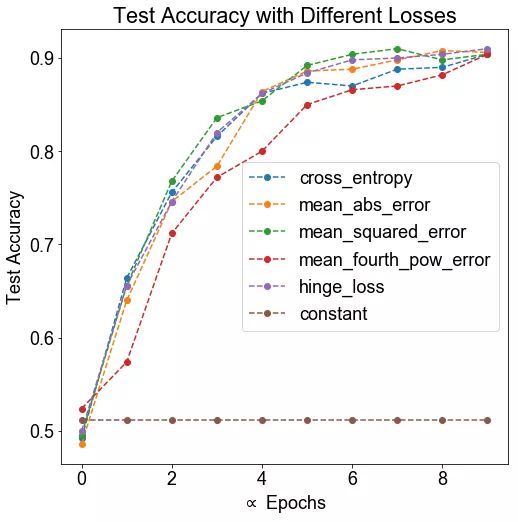
结论: 除去阴性对照外,所有的损失都有类似的表现。损失函数是标签与逻辑之间的区别,提升到四次幂,其性能要比其他差一些。
讨论: 损失函数的选择对最终结果没有实质影响,这也许不足为奇,因为这些损失函数非常相似。
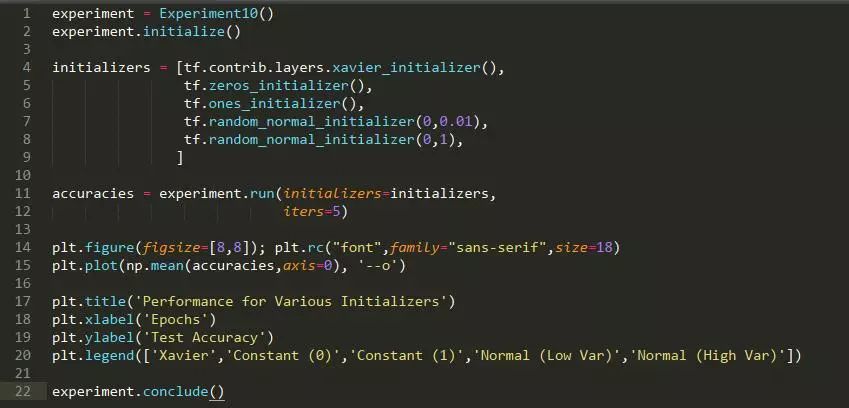
方法: 我们生成两个 12 维高斯混合。高斯具有相同的协方差矩阵,但在每个维度都有一个由 1 隔开的均值。该数据集由 500 个高斯组成,其中 400 个用于训练,100 个用于测试。我们在这个神经网络中初始化权重值,看哪一个具有最好的训练性能。
假设: 我们期望 Xavier 损失具有最好的性能(它是 tensorflow 中使用的默认值),而其他方法性能不佳(尤其是不断的初始化)。
运行实验所需的时间: 34.137 s
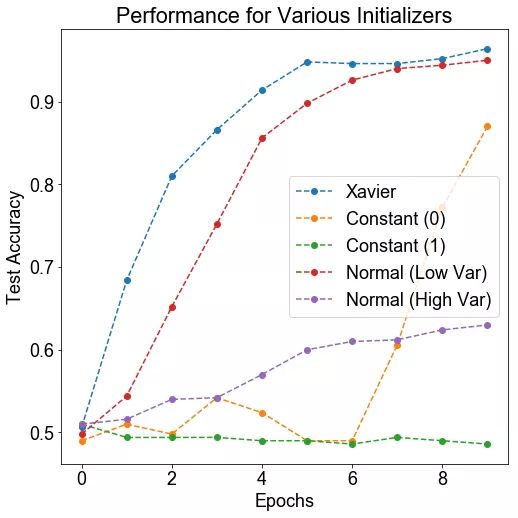
结论: Xavier 和高斯(具有较低的方差)初始化会得到很好的训练。有趣的是,常数 0 的初始化最终导致训练,而其他初始化并不会。
讨论: Xavire 初始化提供了最好的性能,这并不奇怪。标准偏差小的高斯也适用(但不像 Xavire 那样好)。如果方差变得太大,那么训练速度就会变得较慢,这可能是因为神经网络的大部分输出都发生了爆炸。有趣的是,持续的初始化(理论上不应该能够训练神经网络)在几个轮数之后就会导致训练进行。这可能是由于核心并行化导致小的数值误差,最终导致了不同权重的散度。有趣的是,当权重都为 1 时,这些就都不起作用了。
在本节中,我们将研究神经网络的权重值,并可视化它们在整个训练过程中的变化情况。
我们的第一个问题是,不同层的权重是否以不同的速度收敛。
方法: 我们生成两个 12 维高斯混合。高斯具有相同的协方差矩阵,但每个维度上都有一个由 1 隔开的均值。该数据集由 500 个高斯组成,其中 400 个用于训练,100 个用于测试。我们在这个数据集上训练一个带有 3 个隐藏层(将导致 4 层权重,包括从输入到)第一层的权重)的神经网络,我们在训练过程中绘制每层 50 个权重值。我们通过绘制两个轮数之间的权重的差分来衡量收敛性。
假设: 我们期望后一层的权重会更快地收敛,因为它们在整个网络中进行反向传播时,后期阶段的变化会被放大。
运行实验所需的时间: 3.924 s
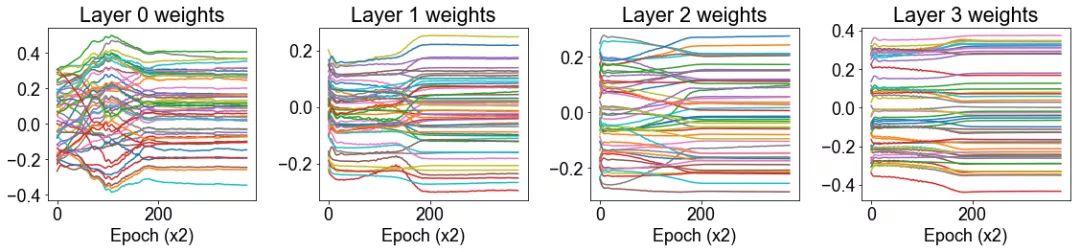
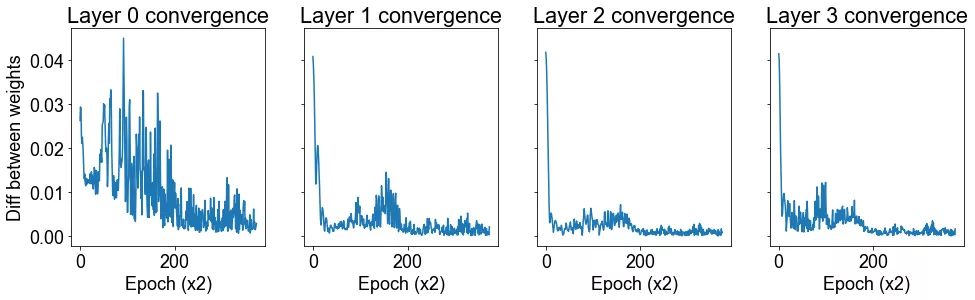
结论: 我们发现后一层的权重比前一层收敛得更快。
讨论: 看上去第三层的权重是几乎单调地收敛到它们的最终值,而且这一过程非常快。至于前几层权重的收敛模式,比较复杂,似乎需要更长的时间才能解决。
方法: 我们生成两个 12 维高斯混合。高斯具有相同的协方差矩阵,但在每个维度上都有一个由 1 隔开的均值。该数据集由 500 个高斯组成,其中 400 个用于训练,100 个用于测试。我们在这个数据集上训练一个具有 2 个隐藏层的神经网络,并在整个训练过程中绘制 50 个权重值。然后我们在损失函数中包含 L1 或 L2 正则项之后重复这一过程。我们研究这样是否会影响权重的收敛。我们还绘制了正确率的图像,并确定它在正则化的情况下是否发生了显著的变化。
假设: 我们预计在正则化的情况下,权重的大小会降低。在 L1 正则化的情况下,我们可能会得到稀疏的权重。如果正则化强度很高,我们就会预计正确率下降,但是正确率实际上可能会随轻度正则化而上升。
运行实验所需的时间: 17.761 s
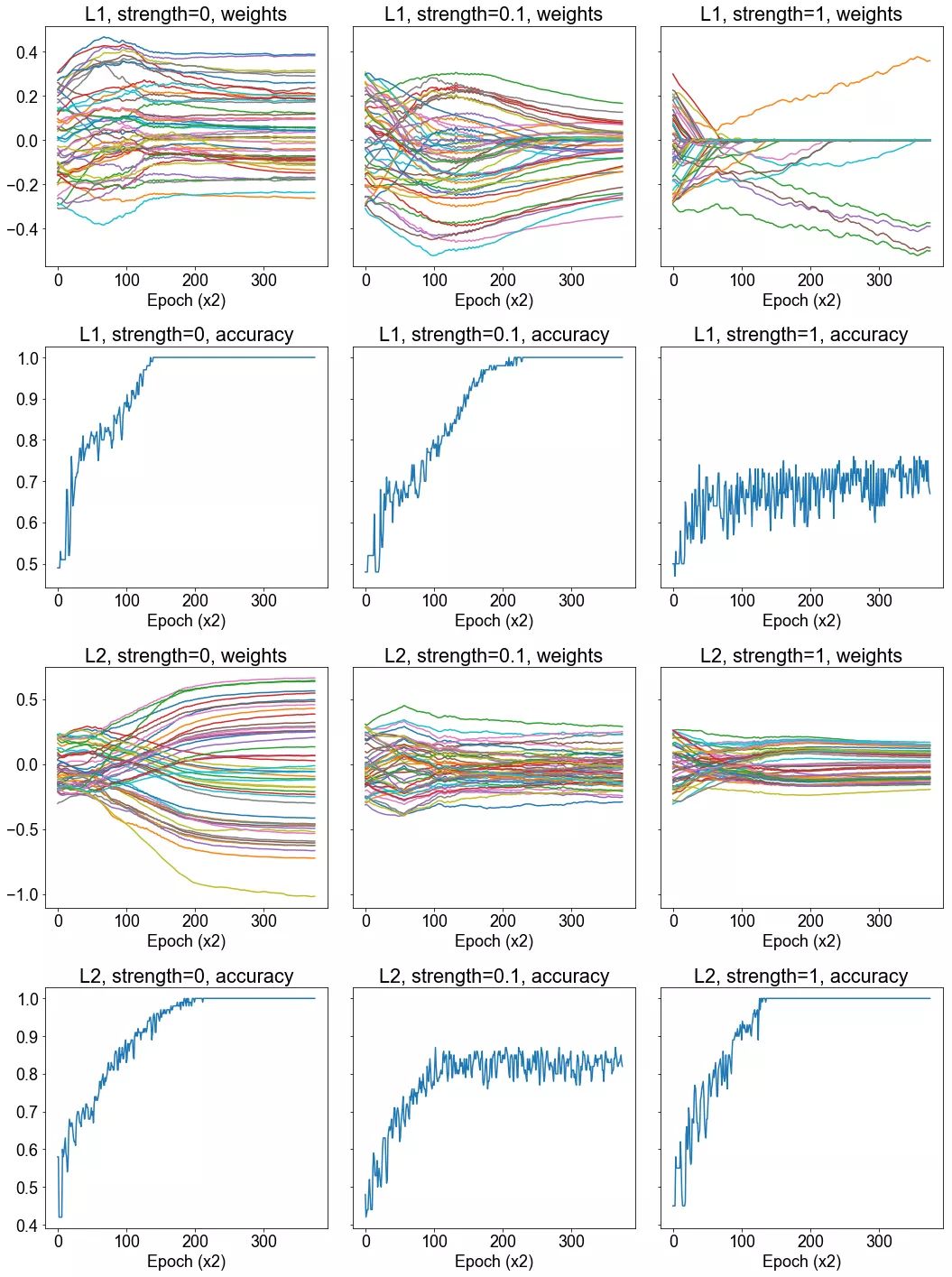
结论: 我们注意到正则化确实降低了权重的大小,在强 L1 正则化的情况下导致了稀疏性。对正确率带来什么样的影响尚未清楚。
讨论: 从我们所选的 50 个权重的样本可以清晰地看出,正则化对训练过程中习得的权重有着显著的影响。我们在 L1 正则化的情况下能够获得一定程度的稀疏性,虽然看起来有较大的正则化强度,这就导致正确率的折衷。而 L2 正则化不会导致稀疏性,它只有更小幅度的权重。同时,对正确率似乎没有什么有害的影响。
我们只是刚刚开始做了肤浅的研究。例如,所有这些实验都涉及(不是那么深的)MLP,并且有很多实验如果用 CNN 或 RNN 来做会很有趣。如果你想添加一个实验,请考虑以下我认为值得探讨的一些观点:
批大小和学习率之间的关系是什么?
端到端的学习与训练神经网络在任务上的区别是什么?
什么是批标准化?它为什么有用?
当数据有限时,迁移学习对神经网络有没有帮助?


如果你喜欢这篇文章,或希望看到更多优质报道,记得给我留言和点赞哦!




