开源开放 | 糖尿病知识图谱DiaKG(CCKS2021)
OpenKG地址:http://openkg.cn/dataset/diakg
阿里云天池:
https://tianchi.aliyun.com/dataset/dataDetail?dataId=88836
开放许可协议:CC BY-SA 4.0 (署名相似共享)
贡献者:妙健康(常德杰、刘朝振、刘利平、李栋栋、李伟),阿里云(陈漠沙),清华大学(许斌)

DiaKG: an Annotated Diabetes Dataset for Medical Knowledge Graph Construction
1. 摘要
2. 背景
3. 数据集
3.1 数据来源
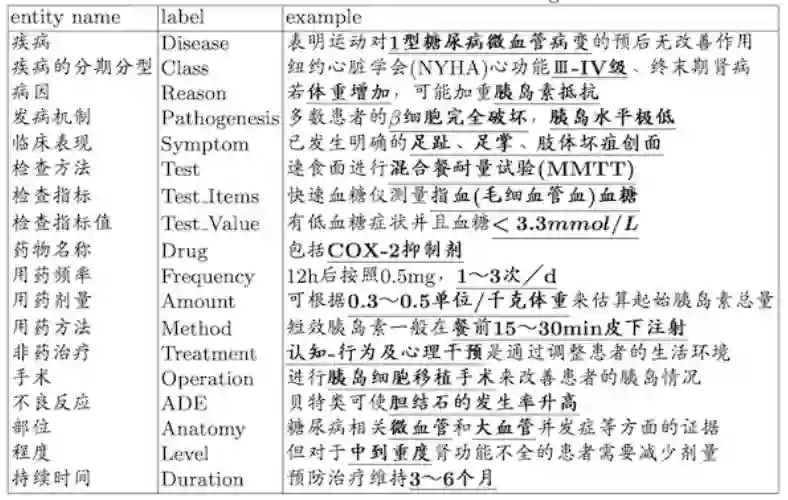

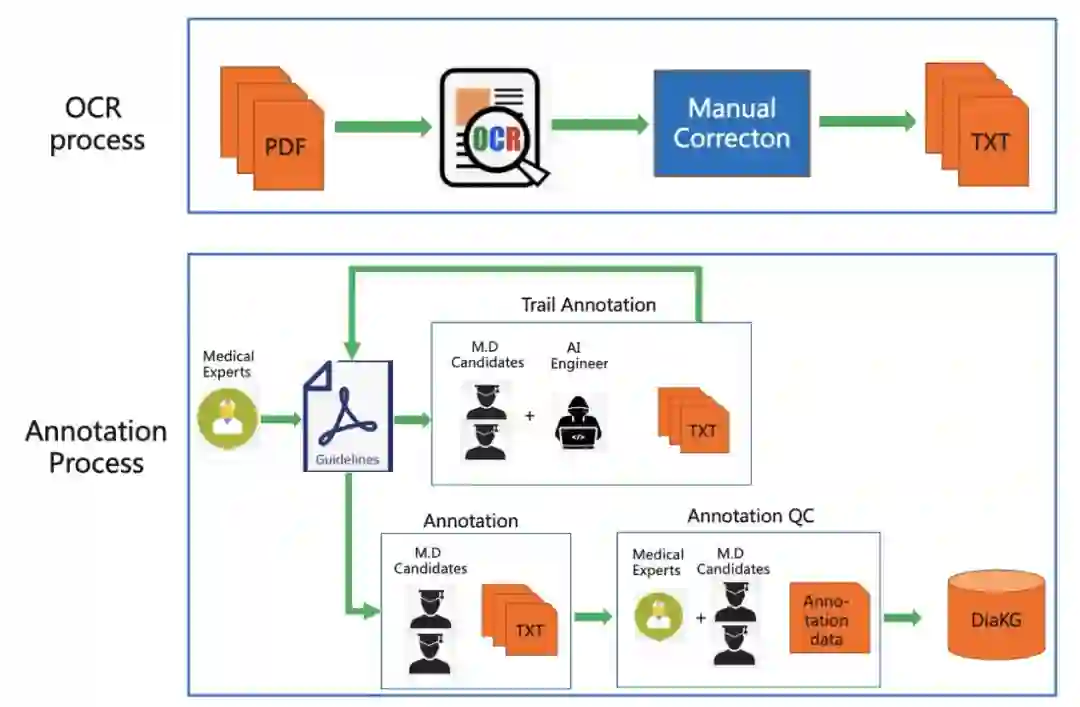
图1:DigKG标注流程示意图

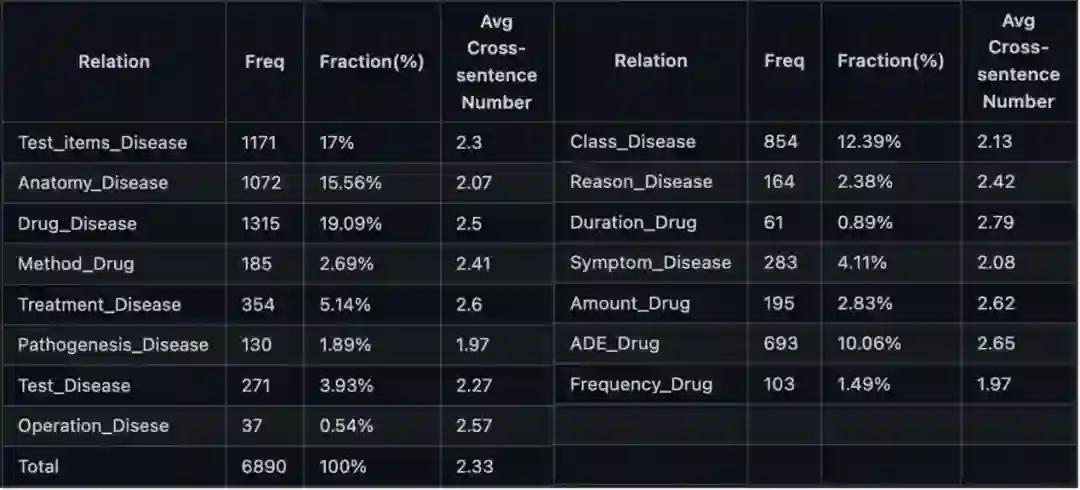
4. 结语
5. 致谢
本论文由妙健康常德杰负责论文撰写,刘朝振提供算法实验指导,刘利平、李栋栋和李伟负责模型实验以及部分论文章节的撰写。特别感谢阿里云高级算法专家陈漠沙提供数据集构建思路和写作指导,清华许斌教授最终论文的审核。最后感谢标注专家的辛勤细致的付出!
OpenKG
OpenKG(中文开放知识图谱)旨在推动以中文为核心的知识图谱数据的开放、互联及众包,并促进知识图谱算法、工具及平台的开源开放。

点击阅读原文,进入 OpenKG 网站。
登录查看更多
相关内容

全国知识图谱与语义计算大会(CCKS: China Conference on Knowledge Graph and Semantic Computing)由中国中文信息学会语言与知识计算专委会定期举办的全国年度学术会议。CCKS源于国内两个主要的相关会议:中文知识图谱研讨会the Chinese Knowledge Graph Symposium (CKGS)和中国语义互联网与Web科学大会Chinese Semantic Web and Web Science Conference (CSWS)。
首届中文知识图谱研讨会于2013年在苏州举行,随后分别在武汉、宜昌成功举办第二次和第三次研讨会。CSWS首次会议于2006年在北京举办,随后的近十年里,逐渐成为国内语义技术领域的主要会议。新的知识图谱与语义计算大会将致力于成为国内知识图谱、语义技术、链接数据等领域的核心会议,并聚集了知识表示、自然语言理解、智能问答、知识抽取、链接数据、图数据库、图挖掘、自动推理等相关技术领域的重要学者和研究人员。
Arxiv
11+阅读 · 2019年9月23日





相关VIP内容
相关资讯
相关论文
Arxiv
11+阅读 · 2019年9月23日